derniers billets - Carrefour de l'agrégation le 2 juin 2025
- Graphes sémantiques pour l'industrie (mars 2025)
- CapData Opéra présenté à SWIB24
- Retours sur SemWeb.pro 2024
- Forum Teratec 2024
- Forum entreprendre dans la culture en 2024
- Role Models à la radio - Le Retour
- 2ème Symposium Solid
- SemGraph pour transformer vos données en graphes sémantiques
- Logilab était au Capitole du libre 2023
- Retour sur SemWeb.Pro 2023
- Notre parcours de formation Web Sémantique
- CubicWeb 4 est disponible !
- Une journée SemWeb.pro à Toulouse !
- Retours sur la PyConFR 2023
- AFPYRo du 16 mars 2023
- CubicWeb dans le catalogue GouvTech
- SemWeb.Pro 2021 aura lieu le 9 décembre
- Négociation de contenu dans CubicWeb
- SemWeb.Pro 2019 : envoyez votre proposition avant samedi 31 août !
- Logilab soutient pgDay Lyon 2019
- La conférence Mercurial aura lieu mardi 28 mai, à Paris !
- Mini-sprint mercurial du 4 au 7 avril à Paris
- Logilab soutient pgDay Paris 2019
- Fosdem 2019, nous y étions !
- Logilab présent au Capitole du Libre 2018
- Logilab présent à Paris Open Source Summit
- Logilab soutien PyParis 2018 : consultez le programme et inscrivez-vous !
- SemWeb.Pro 2018 : utilisez le code de réduction SWEP et incrivez-vous !
- Logilab a une nouvelle adresse à Toulouse !
- Logilab présent au PyConFr 2018 !
- SemWeb.Pro 2018 : le programme est en ligne, inscrivez-vous !
- Logilab présent aux journées d'études "Documenter la production artistique : données, outils, usages"
- SemWeb.Pro 2018 : l'appel à proposition est ouvert !
- Mini-sprint mercurial du 21 au 25 mai chez Logilab
- Logilab sera présente au FOSDEM et au Config Management Camp 2018
- Meetup Nantes monitoring : netdata et sensu, c'est demain !
- Rencontres Régionales du Logiciel Libre 2017
- C'est nouveau : exposition de posters à SemWeb.Pro
- SemWeb.Pro, tarif à 67€ jusqu'au 3 novembre !
- Le meetup Python, c'est ce soir !
- Nous recrutons !
- Meetup salt, salt-cloud et formulas : jeudi 28 septembre
- SemWeb.Pro 2017
- Mise en ligne de FranceArchives.fr
- Atelier AFNOR usages du Web pour l'industrie
- PyParis 12/13 juin 2017
- Données de santé sur le Web - 23 mai 2017
- Appel à communication SemWeb.Pro 2017
- Week-end Debian de mai 2017
- Logilab vous donne rendez-vous au Paris Open Source Summit 2016
- Logilab fait maintenant partie du GT Système d'Information
- Le meetup Python Nantes monitoring c'est ce soir !
- Découvrez la présentation de Logilab aux Rencontres Régionales du Logiciel Libre
- Logilab aux Rencontres Régionales du Logiciel Libre
- Paris Web of Data - "les utilisations de schema.org" ce jeudi 06/10
- SemWeb.Pro 2016 : le programme est en ligne, inscrivez-vous !
- Paris Web of Data - les utilisations de schema.org le 6 octobre 2016
- Rencontres Régionales du Logiciel Libre - Toulouse 2016
- SemWeb.Pro 2016 : envoyez votre proposition avant vendredi 8 juillet !
- Nous avons été à Agile France 2016 !
- Nous ferons une présentation à la conférence Pydata à Paris
- Logilab soutient la conférence Pydata 2016
- Logilab vous attend sur son stand à la Convention Systematic.
- Le portail FEVIS a été lancé !
- SemWeb.Pro 2016 : l'appel à proposition est ouvert !
- Mercredi 11 mai : Paris Web of Data, les rencontres du Web de données
- Soirée Python à Nantes le 18 mai 2016
- Soirée Salt à Paris le 12 mai 2016
- Avancement du projet OpenDreamKit
- Logilab était à pgDay, à Paris !
- Logilab, un industriel du logiciel
- Libre Théâtre au Forum des Archivistes
- Présentation à Nantes Monitoring Meetup
- Raid Agile dans les Cévennes, on y a été !
- Découvrons les nouveautés de PostgreSQL 9.5 à Toulouse
- Nous avons été à FOSDEM et à Config Management Camp 2016
- [Présentation annulée] Pourquoi et comment Logilab investit dans la R&D ?
- Pourquoi et comment Logilab investit dans la R&D ?
- Logilab présente au FOSDEM et au Config Management Camp !
- Rejoignez-nous aux RRLL 2015 jeudi 3 décembre
- Bilan SemWeb.Pro 2015
- Les présentations Logilab à Paris Open Source Summit
- Capitole du Libre édition 2015 annulée
- Logilab présent à Paris Open Source Summit
- Système d'Archivage Électronique Mutualisé : prochaines présentations
- Rendez-vous aux Rencontres Régionales du Logiciel Libre à Toulouse
- Libre Théâtre : une bibliothèque numérique gratuite d'oeuvres théâtrales du domaine public se prépare
- SemWeb.Pro 2015 : Encore 2 jours pour bénéficier du tarif à 65€
- Logilab présent au Hackathon Code_TYMPAN
- 15 ans de Logilab
- SemWeb.Pro 2015 : découvrez le programme et inscrivez-vous !
- Logilab sera présent au meet-up Code_Tympan !
- Logilab fête ses 15 ans !
- Unlish, une application CubicWeb
- Lancement du blog Simulagora
- Lancement du projet OpenDreamKit
- Logilab présent à la conférence PyConFr 2015
- Logilab partenaire technique de Libre Théâtre
- Logilab au Salon du Bourget et Forum Teratec 2015
- SaltStack animera une formation du 2 au 4 septembre 2015 à Paris
- Logilab au Bibcamp 2015 de l'ADBU
- Logilab partenaire SaltStack pour assurer la formation, le support et la certification sur Salt en France et en Europe
- Logilab et l'Open Source Innovation Spring
- Sprint Salt le 4 mars 2015 à Logilab
- Nouvelle formation "Gestion de sources avec Git"
- Présentation des compétences Big Data
- Capitole du Libre - notre participation 2014
- Supports de présentation Battle OpenData - DataLab
- Logilab au Capitole du Libre les 14/15/16 novembre 2014 à Toulouse
- Logilab présente Saltstack le 3 novembre à la cantine Toulouse
- Battle des plate-formes Open Data - octobre 2014
- Conférence SemWeb.Pro le 5 novembre, programme et inscriptions
- Logilab à "Réutilisation et open data : quels enjeux pour les archives ?"
- Logilab aux Rencontres Régionnales du Logiciel Libre à Nantes
- Logilab à EuroSciPy 2014
- Logilab, une pépite du pôle Systematic
- Réunion Salt le 23 septembre 2014 à Paris
- Logilab participe à Debconf 2014
- Save the date : RRLL Toulouse le 14 novembre
- Convention Systematic 2014
- Code_TYMPAN au congrès Nafems 2014
- Test-Driven Infrastructure avec Salt à Solutions Linux 2014
- Réunion Salt le 19 mai 2014 à Paris
- Nouvelle formation "Développement de code par le scientifique"
- Prochaines sessions de formation
- Réunion Salt le 15 avril 2014 à Paris
- Python pour DevOps à Paris (mars 2014)
- Hackathon codes de mécanique (mars 2014)
- Barcamp OpenScience à Toulouse (fév 2014)
- Logilab au FOSDEM 2014
- Objectifs de Logilab en 2014
- Logilab officiellement membre d'Aerospace Valley
- Réunion Salt le 6 février 2014 à Paris
- Mini DebConf Paris 2014
- OpenCat - un catalogue de bibliothèque fondé sur data.bnf.fr
- Calendrier des sessions de formation du 1er semestre 2014
- Nouveau programme de formation Debian avancé
- Mise en ligne des données Brainomics/Localizer
- Défi CubicWeb pour la Nuit de l'info 2013
- Présentation CubicWeb à la communauté urbaine de Bordeaux
- Rencontres Régionales du Logiciel Libre et du Secteur Public
- AG actionnaires de Logilab - 2013
- Retour sur OpenWorldForum 2013
- Logilab sera présent demain au Barcamp Open Data Toulouse métropole
- Logilab sponsor du Capitol du Libre 2013 à Toulouse
- Logilab à l'OpenWorldForum 2013
- Logilab sponsor de DebConf13
- Coupure d'électricité
- Nouvelle formation "Apprentissage statistique et fouille de données avec Python"
- Nouvelles sessions de formation en rentrée 2013
- Nouvelle formation "Python pour l'analyse de données"
- Trophée de l’Excellence Documation - MIS 2013 « Data Intelligence » pour data.bnf.fr
- Nomination de Logilab aux Data Intelligence Awards 2013
- Nouvelles sessions de formation en juin / juillet 2013
- Session inter-entreprises de la formation "Développer une application avec CubicWeb"
- Prix Stanford de l'innovation pour data.bnf.fr
- CubicWeb lauréat de Dataconnexions 2013
- Logilab rejoint le cluster Digital Place
- CubicWeb à dataconnexions#2
- Calendrier formations 1er semestre 2013
- Logilab partenaire de l'IRILL
- Présentation conjointe Logilab / SNCF au séminaire NAFEMS
- Logilab participe à Agile Tour Nantes
- Stages Ingénieur 2012-2013
- Mini DebConf Paris 2012
- Nouveau catalogue de formations
- Logilab signe la Charte pour l'emploi logiciel libre
- data.bnf.fr - épisode II
- Logilab recrute à Toulouse
- Présentation à la conférence "La Fabrique de la Loi"
- Logilab au congrès Nafems 2012
- Revue de presse : Mini-interview de Sylvain Thénault sur midenews.com
- Logilab sponsor du Software Carpentry Project
- Logilab participe à la semaine de l'OpenData à Nantes
- Revue de presse : Logilab s'implante à Toulouse
- SemWeb.Pro 2012
- Lancement du projet OpenCat
- Lancement du projet ANR Niconnect
- Le site intitutionnel de Logilab fait peau neuve
- Mise à jour des formations Python numérique
- Logilab lance LibAster
- Inscrivez-vous à SemWeb.Pro 2011 - Paris
- SemWeb.Pro 2011 à Paris
- Formation CubicWeb
- Nouveaux locaux à Paris
- EuroScipy 2010 à Paris
- Lancement du projet CSDL - Complex System Design Lab
- Logilab à EuroSciPy 2009
- Logilab participe à PyconFR 2009
- CubicWeb 3.0
- Logilab à EuroPython 2008
- Logilab aux rencontres Ter@tec
- Logilab à Google I/O 2008
- Logilab participe à PyconFR
- Logilab publie LAX
- Logilab au Directoire de System@tic
- Augmentation de capital
- Livre blanc APRIL
- Annuaire 118000 et CubicWeb
- Logilab et Itaapy proposent une offre de TMA et de migration de Zope/CPS
- Sprint PyPy à Genève
- Conférence EuroPython 2006 - CERN Genève
- Paris capitale du Libre 2006
- Réunion annuelle CUPS
- Pôle de compétitivité System@tic Paris-Région
- Conférence de Logilab à XPDay France 2006
- Logilab à XPDay France 2006
- Logilab à Solutions Linux
- Sprint PyPy à Paris
- souscrire

|
BilletsLogilab était au Carrefour de l'agrégation, organisé par le Ministère de la Culture et la FEMS, qui s'est tenu le 2 juin 2025 au Mucem à Marseille. Voici notre résumé des nouvelles qui ont retenu notre attention.
La numérisation des bâtiments a commencé, avec la publication de modèles 3D, qui seront probablement consultables via une extension du protocole IIIF qui en cours de définition par le IIIF 3D community group.
Le ministère a publié une première version du profil d'application LIDO-MC accompagné d'un tableau de correspondance avec le format Joconde. Une nouvelle version sera disponible d'ici un an et ajoutera la description des données bibliographiques et de provenance, sachant que l'objectif à l'horizon 2030 est de multiplier par quatre la quantité de données par rapport à 2020.
La Plateforme Ouverte du Patrimoine (POP) a récemment bénéficié d'améliorations avec la séparation entre production et diffusion des données, des actions de sécurisation et une migration vers un cloud souverain, en l'occurence OVH. La moissonneuse de POP, qu'il n'est pour le moment pas prévu de publier en logiciel libre, nous a rappelé les fonctions de collecte de UData. UData est le logiciel libre développé et utilisé par data.gouv.fr. A Logilab nous avons une application similaire que nous utilisons par exemple pour CapData Opéra et pour GraphEthno dont nous avons justement présenté les dernières avancées lors de la journée.
Le ministère mène actuellement des actions d'accompagnement pour aider à la transformation numérique et la cybersécurité et a ouvert un guichet de financement pour les référentiels et la découvrabilité des contenus.
La conférence Europeana 2025 aura lieu les 11 et 12 juin 2025 à Varsovie et sera retransmise en ligne. C'est une bonne occasion de se tenir au courant des récentes évolutions de cet agrégateur européen des données culturelles et de l'espace européen des données patrimoniales.
Merci au Mucem pour l'invitation dans une salle de conférence avec vue sur la mer, nous y reviendrons avec plaisir ! Nous avons le plaisir de soutenir financièrement la Plate-Forme Intelligence Artificielle (PFIA2025) dont l'objectif est de réunir chercheurs, industriels et étudiants autour de conférences et d’ateliers consacrés à l’Intelligence Artificielle (IA).
Cette manifestation est organisée annuellement et regroupe sept conférences différentes, chacune concernant une branche de l’intelligence artificielle :
* Conférence Nationale sur les Applications Pratiques de l’Intelligence Artificielle (APIA)
* Conférence sur l'Apprentissage Automatique (CAP)
* Conférence Nationale en Intelligence Artificielle (CNIA)
* Journées Francophones d’Ingénierie des Connaissances (IC)
* Journées Francophones sur la Planification, la Décision et l’Apprentissage pour la conduite de systèmes (JFPDA)
* Journées Francophones sur les Systèmes Multi-Agents (JFSMA)
* Journées d’Intelligence Artificielle Fondamentale (JIAF)
* Rencontre des Jeunes Chercheurs en Intelligence Artificielle (RJCIA)
Chez Logilab, vu notre expertise en technologies du Web Sémantique, nous participons régulièrement aux conférences IC et APIA en tant qu'auditeurs, rédacteurs et relecteurs. En effet, ces conférences sont le lieu où sont abordées les évolutions relatives au Web Sémantique et au Web de données liées (voir par exemple notre article présenté en 2024 et intitulé CapData Opéra: faciliter l'interopérabilité des données des maisons d'opéra ou nos autres publications scientifiques).
Comme à l'accoutumée, nous participerons avec enthousiasme à cet événement qui nous donne l'occasion d'approfondir nos connaissances et d'orienter nos prochains projets. Rendez-vous à l'Université de Bourgogne à Dijon du 30 juin au 4 juillet 2025 ! Logilab a assisté à la mini-conférence « Graphe sémantique pour l’industrie », organisée à Paris par GrapheWise au mois de mars 2025.
Ce meetup était principalement dédié au domaine de la santé. Les intervenants ont présenté des solutions innovantes pour améliorer l'interopérabilité et l'exploitation des données dans le secteur de la santé.
Guillaume Rachez de Perfect Memory a souligné l'importance de la sémantisation des données pour les rendre accessibles et compréhensibles, en intégrant toutes les données, structurées ou non, et en les contextualisant. Il a insisté sur l'acceptation de la subjectivité des ontologies.
Chez Servier, Christopher Arnoll et Joffrey Cesbron ont montré comment ils utilisent des ontologies et des LLMs pour contextualiser les données R&D, notamment avec un graphe de connaissances et la possibilité de requêter ce graphe en langage naturel.
Thierry Dart et Yann Briand de l'Agence du Numérique en Santé ont présenté leur serveur multi-terminologie pour faciliter l'interopérabilité sémantique. Ils ont mis en avant l'importance des ressources sémantiques pour structurer et harmoniser les données de santé, permettant ainsi une meilleure exploitation des référentiels médicaux par les acteurs du secteur, par exemple au travers du Référentiel unique d'interopérabilité du médicament.
Amel Raboudi a présenté les travaux qu’il mène chez Fealinx pour concevoir une ontologie adaptée au domaine de la psychiatrie.
Ces diverses présentations mettent en lumière l'importance des graphes de connaissances et des ontologies pour structurer et harmoniser les données de santé, permettant ainsi une meilleure exploitation et interopérabilité.
Si ces sujets vous intéressent, explorez les archives avec Le web sémantique au service du bon usage du médicament, SemBot pour le bon usage des médicaments et le Serveur Multi-Terminologie et ne manquez pas la prochaine conférence semweb.pro le 27 novembre 2025 à Paris ! Logilab est partenaire de la conférence DebConf25 qui se déroulera à Brest du 14 au 20 juillet 2025. Nous contribuons au projet Debian depuis les débuts de Logilab et nous proposons des formations et de l'assistance pour le déploiement de cette distribution, que nous utilisons sur tout notre parc informatique.
Debian est le fruit du travail d'une association internationale structurée et bien organisée, doté d'une constitution, qui élit son chef de projet une fois par an. Elle a la particularité d'être non commerciale et constituée exclusivement de logiciels libres, contrairement à d'autres distributions du système d'exploitation Linux, ce qui résume le slogan "Debian : un système d'exploitation universel".
Retrouvez-nous en juillet prochain à la DebConf 2025 ! Nous avons présenté les résultats du projet CapData Opéra lors de la conférence Semantic Web In liBraries en novembre dernier (SWIB24). Le support de présentation et l'enregistrement vidéo sont disponible sur la page du programme intitulée CapData Opéra: ease data interoperability for opera houses.
Le projet CapData Opéra a appliqué les principes exposés par notre approche SemGraph
qui tente de généraliser la transformation de données en graphes sémantiques grâce à une méthodologie claire et des outils sous licence logiciel libre. Ces outils modulaires, qui reposent sur les standards du W3C pour l'échange de données RDF, se combinent pour construire une solution adaptée à chaque cas client.
La même approche est en ce moment utilisée pour le projet GraphEthno, mené par la Fédération des écomusées et des musées de société, qui a été présenté lors des rencontres professionnelles 2025. Nous remercions vivement tous les participants de cette dernière édition 2024, qui ont participé aux discussions et présenté leurs travaux !
Cette édition 2024 a subi un léger lifting: nous avons modifié le format de la conférence en réduisant le nombre de présentations au profit de plus de temps pour les échanges pendant une session poster ouverte par des présentations éclairs (moins de 3 min pour présenter son sujet et donner au public l'envie d'en savoir plus).
Comme chaque année depuis 2020, Pierre-Antoine Champin est venu faire le bilan des avancées des différents groupes de travail de l'écosystème Data and Knowlegde du W3C.
Nous espérons que ce nouveau format vous aura plu !
Pour tous ceux qui n'ont pas pu être présent, vous retrouverez les supports des présentations et les vidéos SemWeb.Pro 2024 et sur PeerTube.SemWeb.Pro.
La prochaine édition de la conférence SemWeb.Pro, qui se tiendra en novembre 2025, est déjà en préparation. Si vous souhaitez recevoir les annonces, abonnez-vous à la liste de diffusion en envoyant un mail à contact at semweb.pro ou bien suivez le compte mastodon.logilab.fr/@semwebpro ! Nous avions un stand sur le boulevard de l'IA lors du Forum Teratec 2024.
Nous y avons parlé d'Onyxia, un logiciel libre
qui permet d'offrir, via un navigateur web, des environnements de traitement
et de manipulation de données tels que Jupyter, OpenRefine, etc.
Nous envisageons d'en faire le successeur de notre JupyterApps que nous utilisons
pour diverses applications, dont la formation.
Nous y avons aussi présenté une démo d'utilisation d'un modèle de langue pour
interroger en RQL le site SemWeb.Pro.
Les techniques de RAG se révèlent en effet efficaces pour générer des requêtes RQL à partir d'une base d'exemples bien construite. Mi-juin 2024, nous étions invités au forum entreprendre dans la culture, qui a réuni pendant trois jours divers professionnels engagés dans la valorisation du secteur culturel, en particulier avec des moyens numériques.
L'événement a mis en lumière des problématiques communes, notamment en matière d'indexation de contenu, mais aussi aux différents aspects de l'usage des techniques d'intelligence artificielle. Entre impact environnemental, modification du processus de création et aide à la reconnaissance d'image et de texte, ces outils désormais incontournables changent le paradigme des données dans la culture.
Nous avons participé à l'atelier sur les défis et enjeux de la mutualisation des données, qui a mis en avant des projets de fusion de données hétérogènes auxquels nous collaborons, tels que Cap Data Opéra et FranceArchives.
L'INA a animé un atelier sur l'indexation automatique de leurs contenus vidéo et a abordé entre autres des problématiques d'alignement avec des référentiels externes, tels que Wikidata, que nous connaissons bien pour les traiter nous aussi sur de très gros volumes de données au sein de FranceArchives ou de Data.BnF. Logilab a participé en mai 2024 à l'émission "Libre à vous" sur radio Cause Commune, pour y parler des résultats du projet Role Models, qui étudie les modèles d'organisation ouverts dans les entreprises du logiciel libre.
Pour en savoir plus, vous pouvez écouter le podcast depuis la page de l'émission 209 du 28 mai 2024 ou bien lire la transcription. Nous étions les 2 et 3 mai 2024 à Louvain, en Belgique, pour le second symposium sur Solid, qui a réunit une centaine de personnes d'une vingtaine de nationalités au sein d'une université multi-centenaire pour discuter du futur des applications web.
Solid (SOcial LInked Data) est un projet initié par Tim Berners Lee, l'inventeur du Web. Le projet Solid vise à définir, sous l'égide du W3C, un ensemble de protocoles pour gérer l'authentification, l'authorisation et l'accès au données dans les applications web, en permettant aux trois aspects d'être séparés et donc conjugués à partir de fournisseurs différents pour chacun d'eux.
Grâce aux avancées dans ce domaine, les applications du web social de demain vous permettront du vous authentifier à partir du fournisseur d'identité de votre choix (pensez à ces boutons "login with google", "login with facebook", mais intégrés directement dans votre navigateur et sans se limiter aux GAFAM) et d'utiliser votre propre espace de stockage qui n'exposera que les données auxquelles vous accorderez l'accès (pensez à une sorte de Google Drive ou de NextCloud avec des permissions avancées et des données structurées telles que des personnes ou des événements, partagées par toutes les applications que vous utilisez). Avec Solid, fini les recopies d'un silo à l'autre !
Merci à tous les participants pour des discussions enrichissantes et rendez-vous l'an prochain pour la suite. D'ici là, passez nous voir à SemWeb.Pro en novembre à Paris si vous vous intéressez à Solid.

Nous venons de mettre en ligne un site vitrine dédié à notre offre centrée sur la construction de graphes sémantiques, que nous avons nommée SemGraph.
En s'appuyant sur les standards du Web et une architecture décentralisée, les outils indépendants de la suite SemGraph se complètent pour permettre la mise en réseau de données issues de multiples applications disjointes.
Les graphes de connaissances ainsi constitués apportent une valeur inégalée en faisant apparaître des relations auparavant invisibles et en servant de base à de multiples applications d'intelligence artificielle. Nous avons eu le plaisir les 18 et 19 novembre 2023 de participer au Capitole du Libre, que ce soit en tant qu'orateur que visiteur.
Le Capitole du Libre regroupe chaque année sur le campus de l'ENSEEIHT de Toulouse de nombreux passionnés et entreprises autour de conférences sur les logiciels libres et leur impact sur la société. En tant que développeur et utilisateur de logiciels libres depuis plus de vingt ans, Logilab participe régulièrement à cet événement Toulousain.
Cette année Élodie a réalisé une présentation pour vulgariser le Web de données, l'histoire de ses standards ainsi que son utilité pour l'interopérabilité des données et la décentralisation. La conférence a été filmée et la vidéo est disponible sur la chaîne Youtube de l'événement.
Nous avons aussi assisté à de nombreuses autres conférences tout le weekend ce qui nous a permis de découvrir de nouvelles technologies ou solutions libres.
Nous participerons, bien entendu, à la prochaine session du Capitole du libre. Nous avons déjà hâte de vous y rencontrer ! Cette année encore, Logilab a eu le plaisir de vous convier à la conférence SemWeb.pro 2023.
Nous remercions chaleureusement tous les participants et participantes, ainsi que les présentateurs et présentatrices et les membres du comité de programme de cette édition 2023.
Cette édition était riche de 13 présentations aussi intéressantes et animées les unes que les autres. Certains ont pris le risque de la démo et s'en sont sortis avec succès !
Les sujets abordés permettent de se rendre compte de l'air du temps concernant l'utilisation des
technologies du Web Sémantique dans un cadre professionnel. Les travaux présentés concernaient le milieu de l'agriculture, des statistiques, de l'édition d'ouvrages scolaires ou encore des archives.
Tous ces exemples permettent de se rendre compte de l'impact de ces technologies dans de nombreux domaines. Cette année, une place de choix a été accordée à l'utilisation des grands modèles de langues, qui apportent déjà un vent de nouveauté dans les techniques de traitement des données.
Toutes les vidéos des présentations sont accessibles sur https://peertube.semweb.pro/w/p/af3G6oBrS74CyPb6WDwq4U/ si vous souhaitez voir ou revoir certaines explications et démonstrations.
Nous invitons toutes les personnes présentes à répondre au questionnaire qu'elles ont reçu dans notre dernière lettre d'information.
Vu les riches échanges qui ont eu lieu durant cette édition, nous sommes convaincus que cette journée a son utilité et nous allons lancer l'organisation de la session 2024.
En vous abonnant à notre lettre d'information ou en suivant notre compte https://mastodon.logilab.fr/@semwebpro , vous vous tiendrez au courant du prochain appel à communication et des dates clés de l'événement.
En espérant vous croiser à la prochaine édition fin 2024. Début juin, l'émission de radio Libre à Vous, animée par l'April, a ouvert son micro au projet Role Models, qui a décrit sa manière d'étudier (à son petit rythme) les modèles d'organisation ouverts dans les entreprises du logiciel libre.
Logilab, qui s'est inspirée des valeurs du logiciel libre pour sa propre organisation, apporte son soutien à ce projet, initié par le dirigeant de la société.
Pour en savoir plus, consultez la liste des productions du projet, écoutez le podcast ou lisez la transcription de l'émission. 400 mots: ~3min
Après une décennie d'accompagnement de grandes institutions culturelles dans la gestion et la publication de leurs données, Logilab propose un parcours complet de formation pour découvrir et contribuer au Web des données (ou Web sémantique).
Le Web sémantique est l'ensemble des technologies et standards pour rendre des données accessibles sur la toile de manière décentralisée et les lier entre elles. Les données publiées de cette façon se complètent les unes les autres, comme les articles qui se référencent mutuellement sur le Web via des liens hypertexte. A l'instar du Web des documents où tout un chacun peut publier des pages Web et y placer des liens vers les pages déjà existantes, les standards du W3C pour le Web sémantique permettent de publier des données en y insérant des liens vers les autres données déjà existantes.
Une première formation permet de découvrir pas à pas les notions du Web des données, en allant de l'hypertexte du Web des documents jusqu'aux ontologies du Web Sémantique et en passant par le cycle de vie des données et les standards de publication et d'interrogation. L'objectif de la formation est de repartir avec des points de repères clairs sur le sujet.
Une deuxième formation est dispensée afin d'apprendre à contribuer au Web des données dans le respect des standards du W3C. Les principales techniques de description de ressources et de publication sont abordées sous un angle concret avec des exercices de mise en pratique. L'objectif étant d'apprendre à passer d'un ensemble de données CSV à un entrepôt SPARQL contenant des triplets RDF de ces données et de les interroger en SPARQL.
Une troisième formation complète le parcours en abordant la réalisation d'un projet mettant en place les techniques du Web des données. Le but est de fournir des principes servant de boussole pour garder le cap d'un projet de ce type et ne pas passer à côté des caractères différenciant qui font l'intérêt du Web Sémantique.
À l'issue de ces formations, qui ont déjà été suivies par plusieurs dizaines de personnes, les participantes et participants seront à même de proposer à l'institution ou l'entreprise qui les emploie une stratégie adaptée à ses objectifs de valorisation et de diffusion et de les mettre en œuvre en publiant des données sur le Web sémantique. 1500 mots: ~7min
Du 1er au 3 juin 2023 a eu lieu le colloque "Des archives aux données" au cours duquel deux jours de hackathon ont permis de s'interroger sur l'interopérabilité des données entre différentes institutions culturelles.
Les données présentées concernaient les représentations théâtrales de la Comédie Française (Base RCF), de la Comédie Italienne, du théâtre d'Amsterdam (Base On Stage) et du théâtre français des XVIIe et XVIIIe siècles (Base CESAR).
Ce fut l'occasion d'éprouver dans un contexte concret les avantages des technologies du Web Sémantique. Les requêtes fédérées ont en effet permis d'assembler et de manipuler des données publiées sans concertation préalable par les différents participants.
Tempête de cerveaux sur les besoins en interopérabilité
Lors de la première journée nous avons commencé par faire émerger des idées de traitements qui nécessitent une interopérabilité des données. Cette session a été très riche et il nous a fallu quelques efforts pour résumér les diverses idées et choisir vers quoi nous diriger.
Nos sources de données divergent principalement sur le périmètre étudié: les registres de la Comédie Française concernent une unique troupe, la base "ON_Stage" se focalise sur le théâtre d'Amsterdam et la base CESAR se limite à une période de temps.
La date des représentation théâtrales a été clairement identifiée comme centrale puisqu'elle permet de les aligner de manière non ambigüe. Chaque source de données décrit différemment les représentations, mais toutes ont renseigné la date.
Les lieux des représentations constituent un autre point de contact, pour autant que les périodes temporelles soient les mêmes.
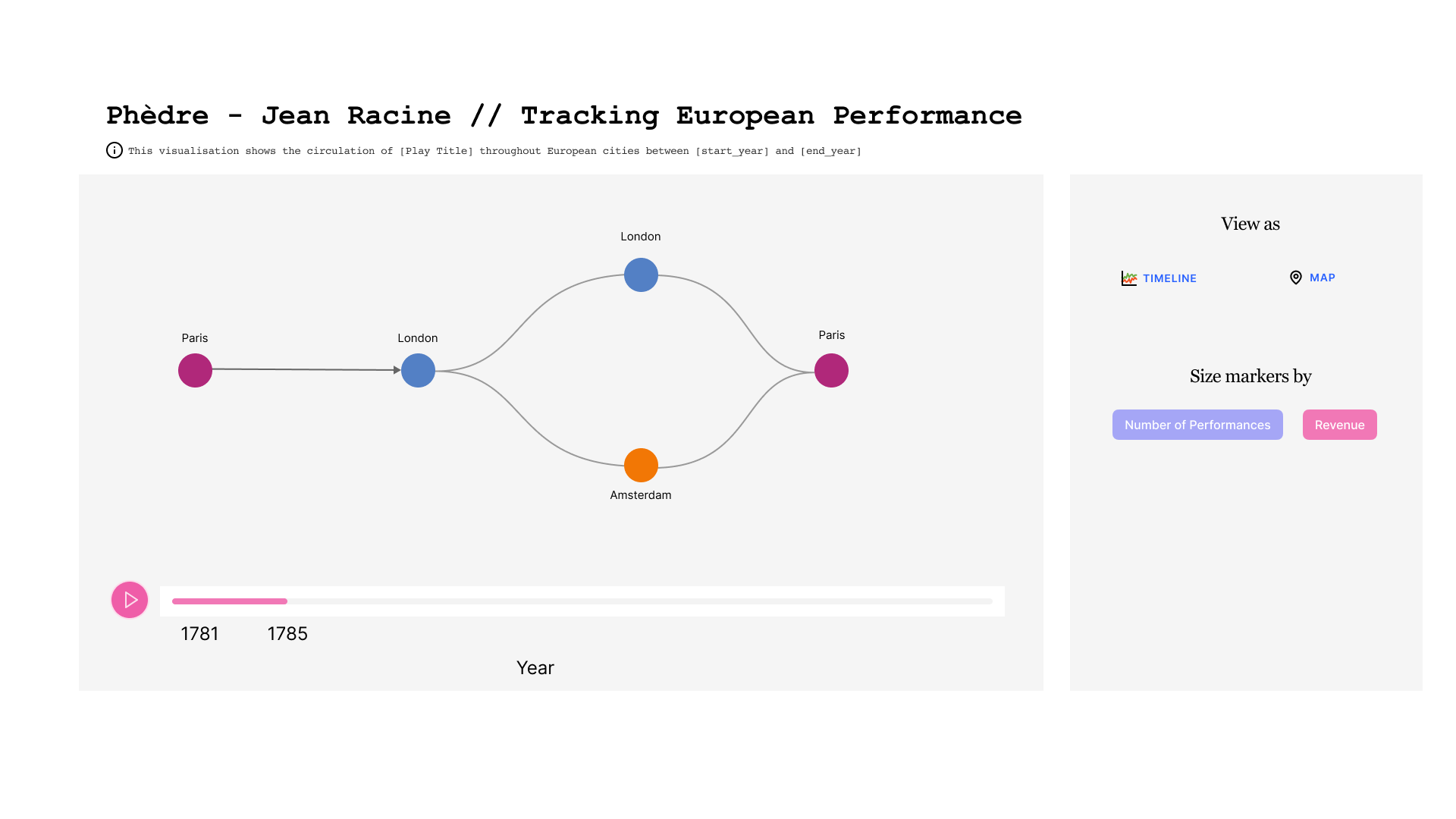
Partant de ces deux constats, nous nous sommes demandé s'il serait possible d'afficher un graphique qui rendrait compte de l'évolution géographique d'une pièce dans une période de temps donnée.
Maquette d'une potentielle application
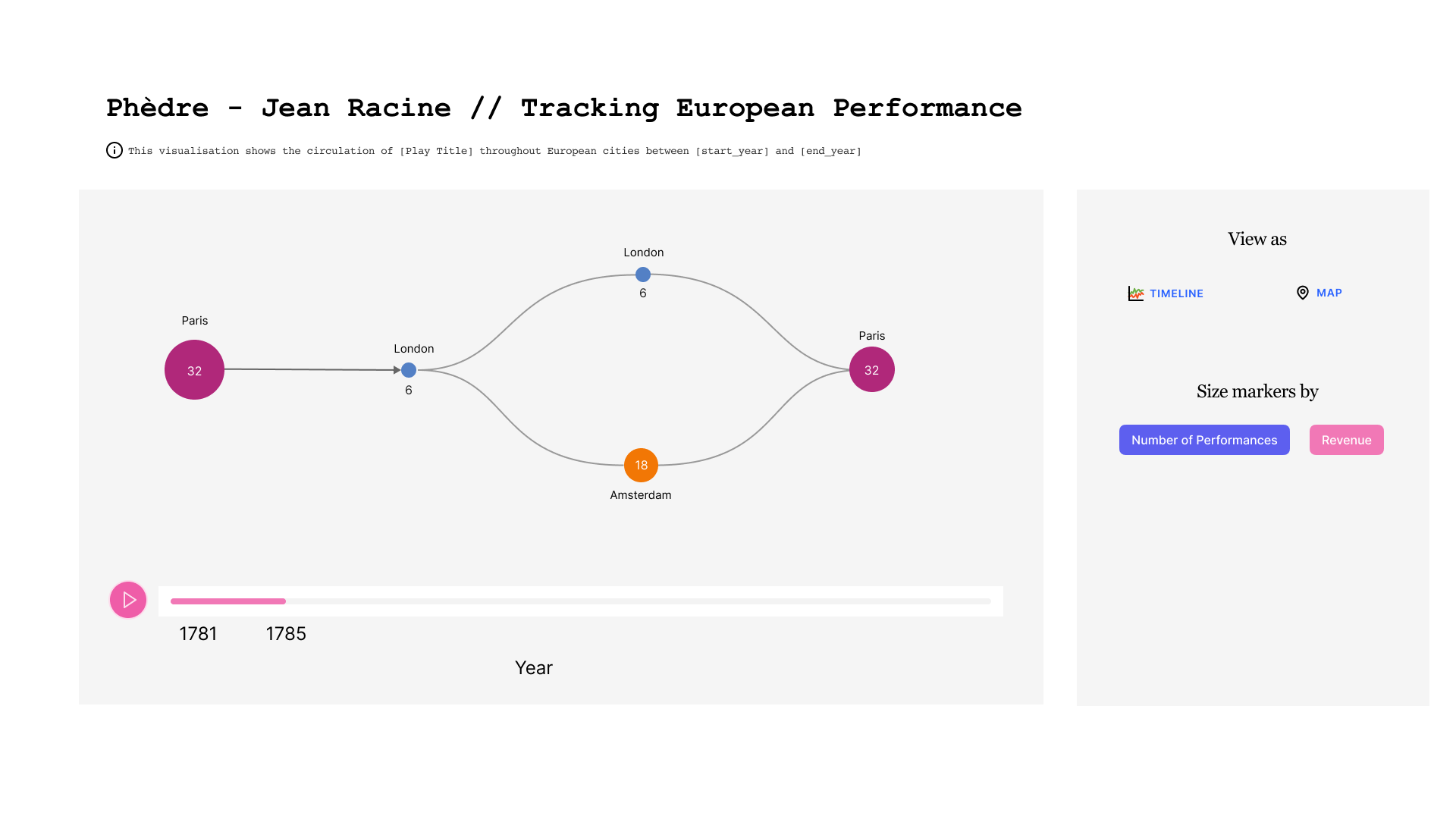
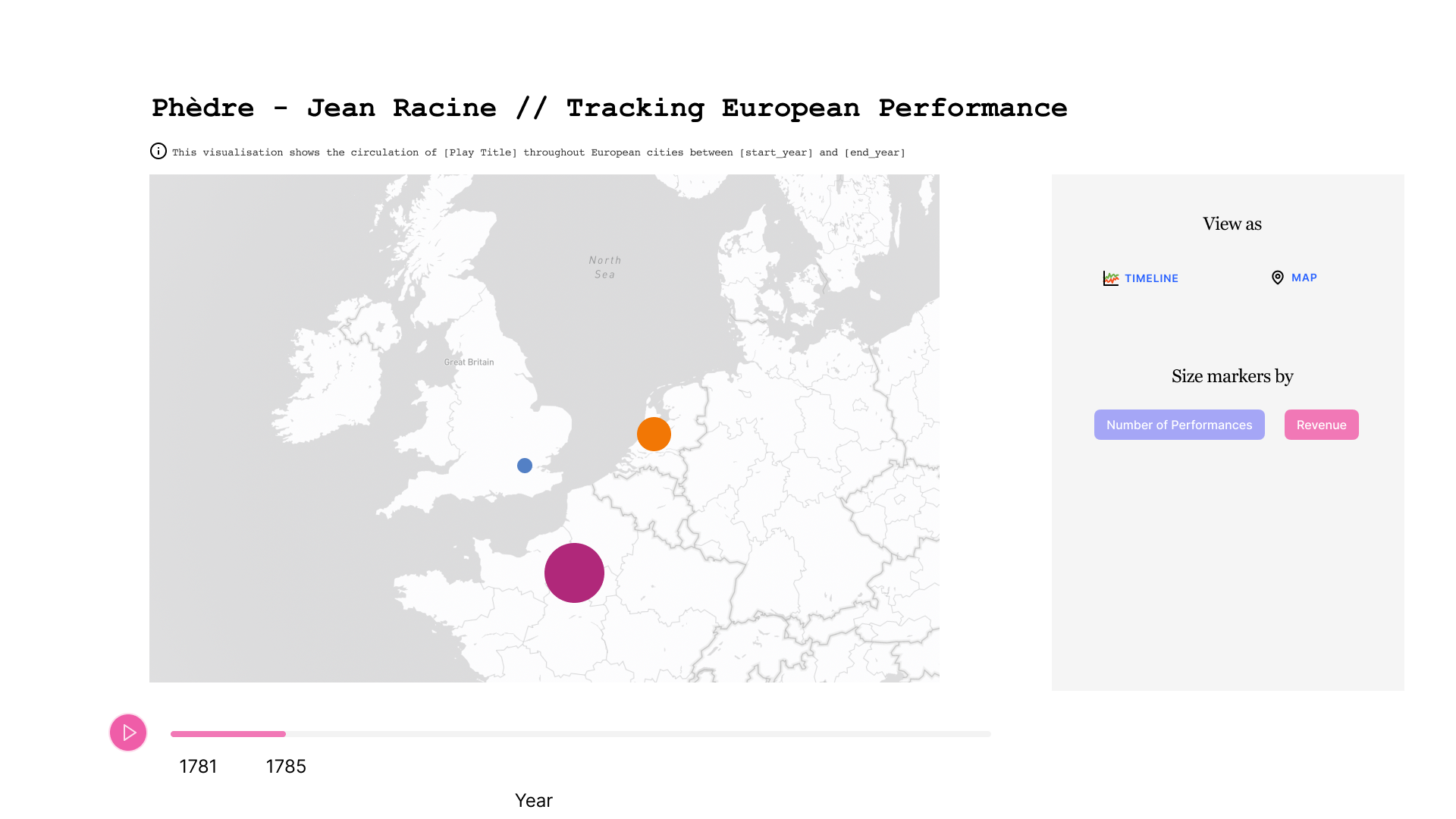
Dans la maquette ci-dessous, nous pouvons observer l'évolution dans le temps d'une pièce donnée. Au centre on voit l'enchaînement des villes où la pièce a été jouée. Une ville peut apparaître plusieurs fois si la pièce y a été rejouée après avoir tourné ailleurs. En bas figure la ligne de temps, qui est sous-divisée par année. A droite, on trouve un cadre avec des boutons qui permettent de choisir le mode de représentation.
Dans la première figure, la taille des cercles qui représentent les villes est liée au nombre de représentations.
Dans la deuxième figure, la taille des cercles qui représentent les villes est liée au revenu généré.
Dans la troisième figure, les données sont affichées sur une carte plutôt qu'avec un graphe.
Analyse des sources de données
Nous avons choisi de nous focaliser sur les sources déjà publiées dans des entrepôts SPARQL pour deux raisons. D'une part le hackathon était court, donc il fallait éviter de onsacrer du temps à des questions de lecture de formats de fichiers qui ne produiraient aucun résultat visible. D'autre part les gens autour de la table connaissaient déjà bien ces jeux de données.
Nous avons donc privilégié l'utilisation de ces trois sources de données:
* Les registres de la Comédie Française / accès sparql
* La base CESAR / accès sparql
* La base ON-STAGE / accès sparql
Nous avons tout d'abord écrit des requêtes SPARQL fédérées afin de pouvoir joindre avec une seule requête des données de plusieurs bases.
Ce faisant, nous avons rencontré un premier problème technique, à savoir que l'entrepôt qui héberge les données de la Comédie Française n'était pas configuré pour accepter les requêtes fédérées. Nous avons donc essayé l'inverse, à savoir interroger l'entrepôt de la base CESAR, mais ce dernier repose sur Ontop, qui ne permet pas non plus les requêtes fédérées. Nous avons finalement utilisé l'entrepôt de la base ONSTAGE, déployé avec TriplyDB, pour exécuter une requête fédérée assemblant des données de RCF et CESAR... mais aucune de ONSTAGE. Ceci nous a rappelé que la fédération de requêtes, séduisante sur le papier, est parfois plus compliquée qu'il n'y paraît.
Alignement des modèles
Nous avons ensuite cherché quel modèle utiliser pour assembler les données obtenues avec ces requêtes.
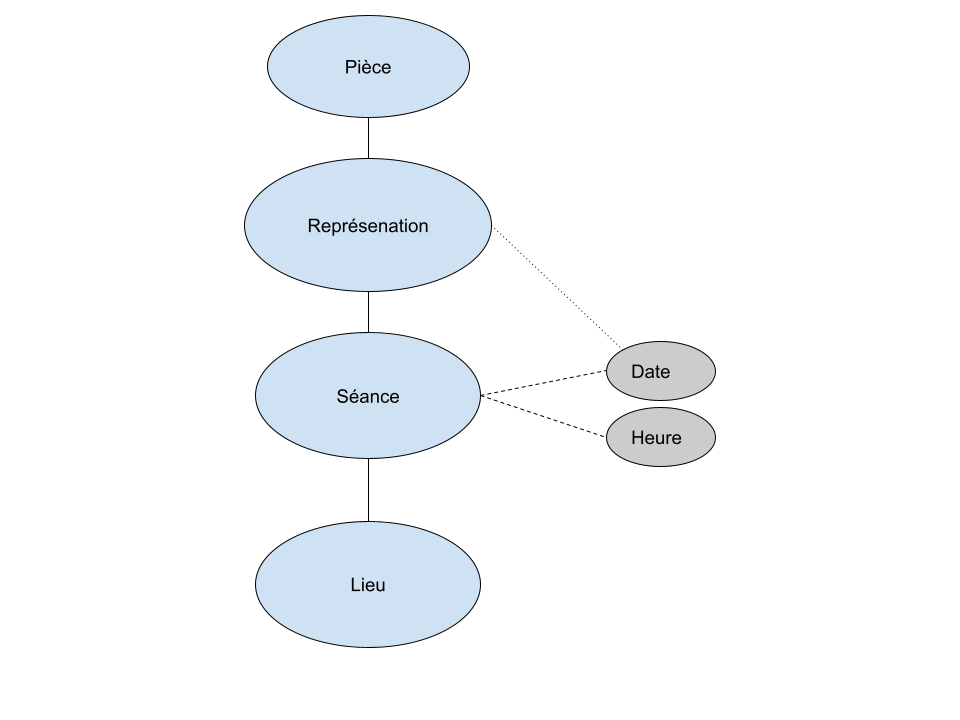
La base CESAR décrit des "Séances", qui peuvent être définies comme des ensembles de représentations contigües. Cette notion peut être rapprochée de celle de "Journée" dans le modèle RCF, mais cet alignement n'est pas tout à fait exact puisqu'il est possible qu'il y ait plusieurs "Séances" à la même date, donc plusieurs "Séances" dans une "Journée". Les registres de la Comédie Française ne détiennent pas cette information de "Séance" spécifique et se contentent de considérer uniquement la "Journée".
Ces différences de modélisation sont monnaie courante et nous avons dû, sans surprise, définir un modèle intermédiaire adapté à notre objectif et des opérations de transformation des données pour les convertir de leur modèle d'origine vers ce modèle afin de les fusionner.
Nous avons retenu les notions de Pièce, de Représentation, de Séance et de Lieu.
Alignement des données
L'objectif de notre maquette étant de rendre visible les évolutions des pièces qui apparaissent quand on fusionne les données complémentaires issues des différentes sources, nous avons ensuite aligné les pièces.
Pour cela, nous avons utilisé la date de représentation pour restreindre les candidats à l'alignement, puis le nom de la pièce. Par exemple, nous savons que le 30 septembre 1681 on a joué d'après la base CESAR une pièce 123303 intitulée "Phèdre et Hippolyte" et une pièce 23287 intitulée "Les Fragments de Molière". A la même date, d'après la base RCF, on a joué une pièce 5772 intitulée "Phèdre et Hippolyte ou Phèdre" et une pièce 5396 intitulée "Fragments de Molière (Les)". Avec une simple distance de Levenshtein entre chaînes de caractères, nous pouvons aligner les pièces et affimer que 123303 chez CESAR correspond à 5396 chez RCF.
En appliquant ce traitement sur l'ensemble des dates, nous avons obtenu un alignement entre les 49 pièces de CESAR et RCF.
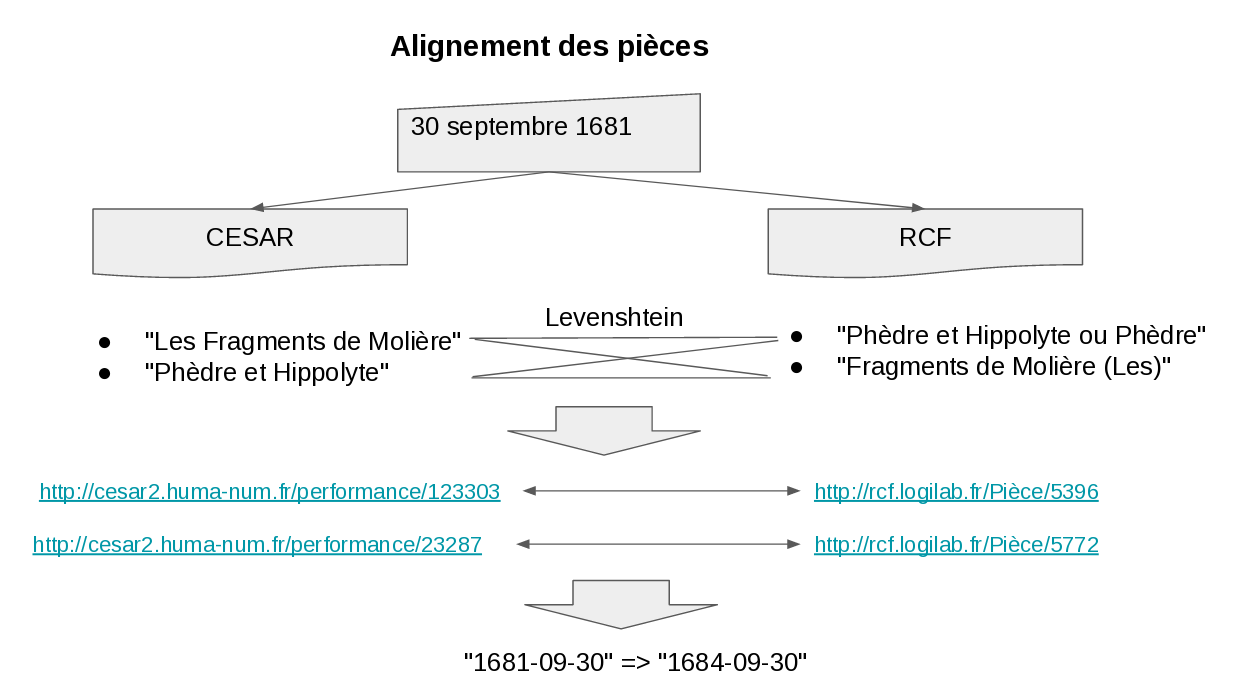
Vu le temps imparti, nous nous sommes limité aux pièces, mais on pourrait pousser plus loin et par exemple inclure dans le modèle les personnes, puis les aligner en utilisant des critères appropriés.
Exploitation des données
Une fois les données importées depuis les différentes sources, converties dans le même modèle et alignées automatiquement entre CESAR et RCR ou une par une pour quelques pièces de ONSTAGE, il devient possible de les exploiter.
Les bases RCF et ONSTAGE ne contenant pas de lieux, nous avons supposé que toutes les représentations RCF étaient à Paris et toutes celles d'ONSTAGE à Amsterdam. C'est probablement faux, donc pour améliorer la qualité du résultat il faudrait trouver des sources complémentaires à partir desquelles importer les lieux exacts des représentations.
Dans le calepin Jupyter qui nous a servi pour consigner nos expérimentations de manière reproductible, nous avons finalement produit le graphique ci-dessous:
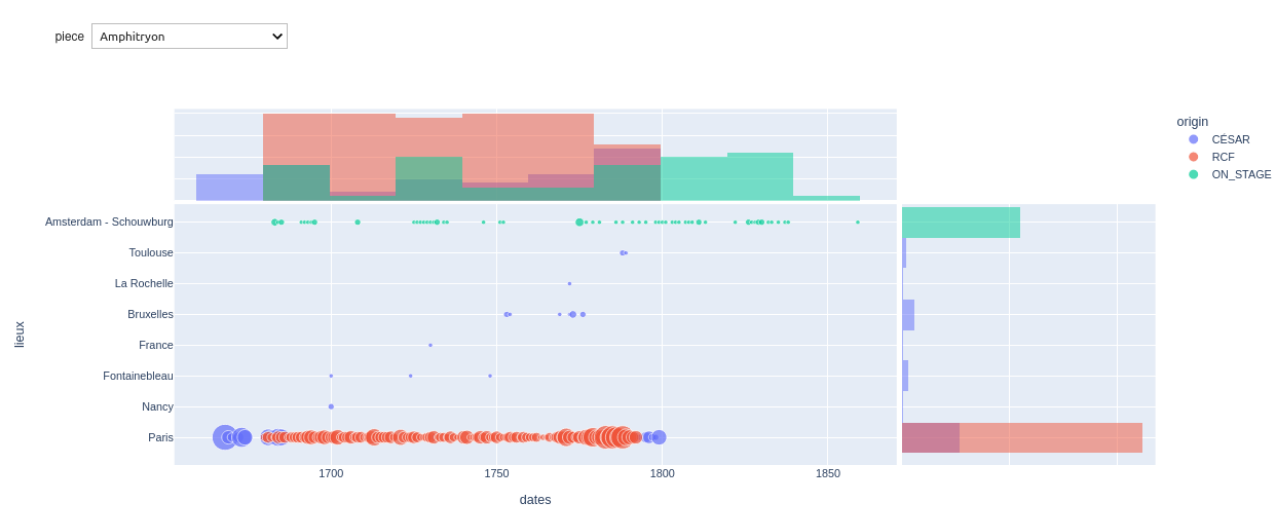
Le menu déroulant en haut à gauche permet de choisir une pièce.
Nous voyons au centre un nuage de points, avec l'année en abscisse et la ville en ordonnée. La couleur des points reflète la source de données et leur taille dépend du nombre de représentations.
L'histogramme au-dessus du graphique est l'aggrégation des données par an pour toutes les villes. L'histogramme de droite est l'agrégation par ville pour toutes les années.
Ce graphique démontre que nous avons produit les données souhaitées, mais il aurait fallu plus de temps pour les représenter comme imaginé en début de hackathon lorsque nous avons dessiné les maquettes graphiques.
Conditions de l'interopérabilité et gouvernance
Ce hackathon a mis en lumière pour tous les participants des questions bien connues de ceux qui ont l'habitude de ce genre d'exercice:
- un modèle commun est nécessaire pour communiquer entre les bases et celles et ceux qui administrent ces bases
- la qualité des données d'entrée détermine l'efficacité du traitement, c'est à dire le rapport entre la qualité du résultat et l'effort nécessaire pour le produire
- l'alignement est une étape cruciale de la fusion des données issues de plusieurs sources
- les standards du Web Sémantique, et particulièrement le RDF et le SPARQL sont des atouts indéniables pour faire interopérer plusieurs sources de données
Ces constats ont fait émerger, au sein de la communauté présente à ce colloque, la question du partage des bonnes pratiques de publication de données. Effectivement, maintenir un modèle commun d'échange, rédiger une guide de bonnes pratiques pour la publication, accompagner les institutions dans leur parcours d'apprentissage, tout cela est un travail long, mais primordial pour supprimer les obstacles à l'interopérabilité.
Il a été discuté de créer un consortium Huma-Num consacré à la gestion des données du spectacle vivant et à l'expression de ces bonnes pratiques, pour orienter la suite des travaux vers des solutions communes et faciliter les interactions entre les données de différentes institutions.
A Logilab, nous apprécions le travail que nous réalisons depuis plusieurs années pour le projet des Registres de la Comédie François et nous avons été honorés d'être invités à ce colloque. Ce hackathon nous a permis de relier les données de RCF, que nous connaissons bien, à d'autres jeux de données, que nous avons découverts, mais aussi de prendre part aux débats sur leur gouvernance future. Nous espérons pouvoir continuer à apporter nos compétences techniques à ces projets, pour faciliter le travail de recherche sur le théâtre et son histoire. 480 mots - 3 minutes de lecture
Logilab est spécialisée dans le développement d’applications Web pour la publication de données ouvertes et dans la gestion de connaissances. Pour cela, nous maintenons, depuis maintenant près de 20 ans, le cadriciel de développement CubicWeb. Nous utilisons ce cadriciel comme base dans la majorité de nos projets, car il nous permet d’avoir accès à un grand nombre de fonctionnalités bien intégrées entre elles et nous évite une continuelle réinvention de la roue.
Depuis les premières versions de CubicWeb, nous avons voulu permettre la génération de l’interface utilisateur à partir du modèle de données pour que les modifications apportées à ce dernier soient facilement reportées dans les affichages qui n’ont pas besoin d’être faits sur-mesure.
Cette pratique était depuis quelques années dépassée, puisque les interfaces utilisateurs du web sont maintenant très souvent de véritables applications exécutées dans le navigateur plutôt que des pages produites par le serveur.
Afin de suivre cet élan et de permettre aux développeurs et développeuses utilisant CubicWeb de bénéficier des outils devenus standards pour les interfaces utilisateurs dynamiques, nous avons produit cette version majeure de CubicWeb qui extrait dans un composant (le cube web) la partie en charge de la génération des pages à partir du modèle de données. CubicWeb devient ainsi ce que l’on appelle un système de gestion de données “sans tête”.
Chacun peut donc développer une ou plusieurs interfaces graphiques en utilisant la technologie qui lui convient (React, Angular, Vue.JS, etc.) et profiter des dernières évolutions techniques côté client, tout en conservant les avantages de CubicWeb côté serveur.
Pour exposer les fonctionnalités du serveur, un cube API a été développé. Ce cube offre une API HTTP publique, qui respecte OpenAPI et permet d’accéder à toutes les fonctionnalités de CubicWeb. La route principale est l’accès à l’interrogation en RQL.
Afin de faciliter encore plus le développement de la partie cliente, nous développons des bibliothèques JavaScript qui implémentent la partie générique des interactions avec un serveur CubicWeb. La bibliothèque @cubicweb/client permet d’établir une connexion avec une instance CubicWeb et @cubicweb/react-form-utils facilite l’écriture de formulaire s’appuyant sur React Hook Form et rendent accessible côté client le modèle de données du serveur et ses types. D’autres outils arriveront dans les prochains mois. Par exemple CubicWeb React Admin peut être utilisé pour avoir une interface d’administration générique sur toute instance de CubicWeb, un peu comme ce que fournissait le cube web en CubicWeb 3.
L’objectif de CubicWeb étant de favoriser la publication de données ouvertes, nous avons profité de la version 4 pour rapprocher encore plus ce cadriciel des technologies du Web Sémantique qui l’ont inspiré, en utilisant notamment la notion de négociation de contenu pour publier du RDF. L’URL d’une entité donne accès soit à une page HTML de base qui affiche les données avec très peu de mise en page, soit aux données en RDF dans l’un des différents formats de sérialisation disponibles.
La liste complète des changements apportés à cette version se trouve dans la documentation. Bon développement ! Un nouvel événement dédié au Web Semantique dans la ville rose s'organise !
Nous avons le plaisir de vous annoncer le programme de la journée d'atelier SemWeb.Pro que nous organisons le 13 Juin prochain à Toulouse.
Cette journée aura lieu le 13 Juin à Toulouse, dans l'espace de coworking et de réunion O'Local, dans une belle bâtisse typiquement toulousaine, avec comme objectif de favoriser au maximum les interactions.
Pensez à vous inscrire !
Le programme de cette journée s'articule en deux temps, le matin une session de présentations et l'après-midi dédié aux échanges autour des thématiques et des questions ayant animé le débat le matin même. Une restitution rapide des ateliers clôturera la journée.
Au programme :
| Créneau |
Titre de la présentation |
Intervenant |
| 10h00-10h30 |
Création automatique d'ontologies à partir de documents techniques |
M. Lalanne (Airbus) |
| 10h30-11h00 |
Intérêt des Systèmes d'Informations pilotés par des ontologies. Illustration avec OpenSilex |
P. Neuveu (INRAE - MISTEA) |
| 11h30-12h00 |
Génération d'un contexte JSON-LD à partir d'un méta-modèle : exemple avec Asset Administration Shell |
É. Thiéblin (Logilab) |
| 11h30-12h00 |
En cours de définition ... |
|
Tous les détails relatifs à l'inscription sont sur le site SemWeb.pro Attention, le nombre de places est limité.
Nous espérons que cet événement tiendra ses promesses en rassemblant et vous permettra d'entretenir votre réseau tout en découvrant un large spectre des possibilités du web sémantique. 380 mots - 2 minutes de lecture
Nous collaborons avec Siemens sur un projet relatif au Web sémantique des objets (Semantic Web of Things ou SWoT en anglais).
Semantic Web of Things
Le Web des objets (Web of Things, WoT), a pour objectif de standardiser l'utilisation des technologies du Web (HTTP, URI, etc.) pour contrer la fragmentation de l'Internet des objets.
Cette standardisation est menée par un groupe de travail du W3C.
Le Web des objets profite notamment de l'interopérabilité offerte par le Web sémantique via la réutilisation de ses standards de représentation de données (RDF, ontologies OWL/RDFS, etc.).
WoT - Thing Description
La spécification WoT-Thing Description (WOT-TD) permet de décrire l'API de chaque objet connecté : quelles propriétés, actions, événements et interactions sont propres à l'objet.
Toutes ces informations sont exprimées à la fois dans un JSON normalisé et en RDF avec une ontologie dédiée.
Le document numérique décrivant l'objet est nommé Thing Description (TD).
WoT - Thing Description Directory
Une fois que les TD sont créées, il faut les rendre accessibles et découvrables. La spécification WoT-Discovery décrit les différentes manières de publier et de centraliser les TD.
Un Thing Description Directory, décrit dans WoT-Discovery, est entrepôt de TD ayant une API en JSON, RDF et SPARQL.
Nous avons developpé un prototype de Thing Description Directory (SparTDD) en Flask et SPARQL, que nous avons présenté à la conférence ESWC2022.
Asset Administration Shell
Asset Administration Shell est une spécification issue du projet allemand Platform Industry 4.0, qui a pour but de numériser les données de l'industrie et de permettre la création de jumeaux numériques.
Un Asset Administration Shell (AAS) caractérise une ressource (asset) en donnant sa description, ses fonctionnalités, la documentation des objets électroniques, etc.
La spécification se veut très générique pour couvrir un maximum de cas d'usages ; c'est de fait une sorte de méta-modèle. Elle comprend un JSON-Schema et une ontologie OWL générée à partir de ce JSON-Schema.
Avec Siemens, nous avons étendu SparTDD pour qu'il puisse ingérer et servir des AAS en plus des TD. Nous avons également créé un module de traduction d'une TD vers un AAS pour, lors de l'import d'une TD créer son pendant en AAS. Les AAS obtenus de SparTDD peuvent ensuite être ingérés par les outils existants qui savent manipuler des AAS. 500 mots - 3 minutes
La PyConFR est le rendez-vous immanquable de la communauté Python en France. Hébergé cette année par l'Université de Bordeaux, cet évènement a rassemblé des développeurs, novices et expérimentés, pendant quatre jours autour de sprints, conférence et ateliers. Après presque trois ans d'attente, nous étions contents de pouvoir enfin retrouver la communauté Python.
Sprint ReservoirPy
Les jeudi et vendredi 15 et 16 étaient consacrés aux sprints, ces ateliers qui rassemblent plusieurs personnes pour faire avancer des projets choisis au préalable.
Nous avons pu contribuer à reservoirpy, une bibliothèque de Reservoir Computing développée à l'INRIA. Nous avons travaillé sur la publication automatique via l'intégration continue (GitHub Actions en l'occurrence) de nouvelles versions de la bibliothèque sur Pypi et sur un entrepôt Anaconda.
Pour en savoir plus sur le Reservoir Computing, vous pouvez regarder cette vidéo d'introduction captée à Dataquitaine en février 2022).
Conférences
Le programme des conférences était très riche et nous avons apprécié la diversité des thématiques (généralistes, web, science des données, devops, ...). Nous n'avons pas pu aller voir toutes les conférences, mais voici un échantillon de celles qui ont particulièrement retenu notre attention.
NucliaDB, une base de données pour le machine learning et les données non-structurées
Éric Bréhault (Nuclia) a présenté NucliaDB qui est une base de données vectorielle, c'est-à-dire qu'elle permet d'associer des données à des vecteurs situés dans un espace ayant de nombreuses dimensions. Adaptée à un usage en machine learning, cette base de données propose une API permettant d'indexer des données non structurées, de faire des recherches sémantiques, etc.
À la découverte de Polars (ou pourquoi vous pourriez quitter pandas)
Cette présentation de Olivier Hervieu nous a fait découvrir une alternative à Pandas pour le traitement de données tabulaires, nommée Polars. Cette bibliothèque est utilisable en Rust et en Python. Nous avons retenu sa capacité à charger des données de manière paresseuse à partir de fichiers.
Python moderne et fonctionnel pour des logiciels robustes
La présentation de Guillaume Desforges (Tweag) a mis en avant les avantages de la programmation fonctionnelle et son applicabilité au langage Python. Elle s'est terminée par une présentation de l'architecture en oignon appliquée à une application Flask.
Psycopg, troisième du nom
Durant cette conférence, Denis Laxalde (Dalibo) a présenté l'historique de la bibliothèque Psycopg. Nous avons également pu découvrir le protocole de communication utilisé pour parler avec un cluster PostgreSQL. Enfin, nous avons observé comment Psycopg s'appuie sur la bibliothèque libpq pour proposer une API haut niveau aux développeurs Python. La version 3 de Psycopg apporte de nombreuses améliorations dont le support de async/await, le support du mode pipeline ou encore le typage statique. Nous sommes fiers à Logilab d'avoir contribué à son financement.
Conclusion
Les PyConFR sont toujours un grand moment partagé avec la communauté Python. Que ce soit pendant les sprints ou entre les conférences, nous avons eu l'opportunité de rencontrer des développeurs de tous horizons et d'échanger avec eux sur des problématiques communes. Rendez-vous dans un an pour la prochaine édition et le 16 mars dans nos locaux parisiens pour un Afpyro. Les AFPYRo reprennent et le prochain aura lieu dans nos locaux parisiens entre Denfert Rochereau et la Place d'Italie !
Un AFPYRo est un événement organisé par l’AFPy − Association Francophone Python − pour regrouper des personnes souhaitant discuter du langage de programmation Python dans un cadre convivial. Après une ou deux présentations (vous pouvez proposer la vôtre), nous échangerons autour de quelques pizzas.
Le prochain AFPYRo sera donc à Logilab, au 104 Boulevard Auguste Blanqui 75013 Paris, le 16 mars 2023 de 19h à 21h et nous offrirons les pizzas.
N’hésitez pas à vous inscrire et à passer nous voir ! Comme annoncé en novembre dernier, nous allons essayer de diversifier les événements SemWeb.Pro. Nous commençons par organiser une journée d'ateliers Semweb.pro à Toulouse au sujet du web sémantique et orientée vers les données industrielles.
L'idée est de réunir les acteurs industriels locaux ou non pour échanger ensemble sur l'usage des standards du web sémantique, qu'il s'agisse de décrire des installations, des processus ou des équipements, exploiter des réseaux de capteurs, etc.
Cette journée aura lieu le 14 Mars à Toulouse, dans l'espace de coworking et de réunion O'Local, dans une belle bâtisse typiquement toulousaine, avec comme objectif de favoriser au maximum les interactions.
La matinée sera dédiée à des présentations sur le thème du Web Sémantique pour l'industrie. L'après-midi sera l'occasion de mener des ateliers en petits groupes pour prendre le temps d'échanger. Une restitution rapide des ateliers clôturera la journée.
Tous les détails relatifs à l'inscription sont sur le site semweb.pro.
Attention, le nombre de places est limité. La recherche scientifique publique est financée par l'État mais le processus classique de publication de résultats de recherche passe par les éditeurs scientifiques qui imposent des tarifs élevés pour accéder aux articles produits par les chercheuses et chercheurs.
HAL archives ouvertes est une plateforme de science ouverte, qui permet aux chercheuses et chercheurs de publier leurs travaux en les rendant librement accessibles.
La science ouverte redonne l'accès aux contenus scientifiques à celles et ceux qui les ont financés (les citoyens et citoyennes). Comme le logiciel libre, elle vise à partage la connaissance avec toutes et tous.
Les activités de recherche de Logilab, qu'elles soient menées pour son propre compte ou en collaboration avec ses clients, font régulièrement l'objet de publications scientifiques, qui sont consultables sur HAL et présentées sur la page des publications en utilisant le logiciel libre SpirHAL (auquel nous avons bien sûr contribué). Logilab a publié son calendrier de formations pour le premier semestre 2023. Ces formations commenceront à partir du mois de mars avec un programme varié et modulable.
Cette année, nous proposons des formations sur Toulouse en plus de nos incontournables formations à Paris. Par ailleurs, quelques-unes de nos formations (qui s'y prêtent bien) se dérouleront en ligne afin d'éviter des déplacements et des heures de trajet inutiles. Grâce à nos outils de visio-conférence, vous pourrez profiter de sessions d'exercices avec un suivi aussi soigné que pour nos formations en présentiel.
Cette année, quelques nouveautés ont été ajoutées au catalogue afin de couvrir au mieux les besoins de formation que nous avons identifiés. Par exemple, la formation "Exploiter le Web des données avec Python (2 jours)" qui s'adresse à des experts et des techniciens dans le domaine de la publication de données ouvertes.
Spécialiste de Python en France depuis 2000, nous proposons toujours un large choix de formations sur ce langage de programmation et ses bibliothèques. Nous proposons également des formations sur :
Nous limitons volontairement le spectre de nos formations pour ne proposer que les sujets que nous pratiquons au quotitien. Assister à une formation Logilab, c'est donc la garantie d'apprendre avec des professionnels compétents maîtrisant parfaitement le sujet qu'ils enseignent. Nos formations sont toujours ajustées en fonction des stagiaires présents. Pour toute demande spécifique, n'hésitez pas à contacter notre service dédié.
Logilab est déclarée comme organisme de formation depuis sa création, est référencée dans Data-Dock, et a été certifiée Qualiopi au titre des actions de formations. Les formations que nous proposons peuvent donc être financées par vos OPCO. Nous avons participé mardi 29 novembre à l'émission Libre à vous diffusée en Ile-de-France sur la bande FM par la radio Cause Commune et en podcast sur Internet. Cette émission, organisée par l'April était consacrée aux logiciels de gestion de version décentralisés et aux forges logicielles.
De concert avec les autres participants, nous avons retracé l'historique des outils de gestion de version, puis expliqué leur rôle clé dans le travail de rédaction collaborative qui est au coeur du processus de développement des logiciels.
Nous avons ensuite abordé le sujet des forges logicielles, qui intègrent au sein d'une même interface utilisateur de multiples fonctions nécessaires à la conception et à la mise en production des applications : gestion de projet, processus de relecture contrôle du changement, automatisation des tests, automatisation du déploiement et de la remontée des erreurs, etc.
Depuis sa création, Logilab produit la quasi-totalité de ses documents et la totalité de ses logiciels en utilisant un logiciel de gestion de version comme base du processus de rédaction collaborative. Après avoir migré à Mercurial au milieu des années 2000, Logilab a contribué à son développement et en particulier aux fonctionnalités avancées concernant le mode brouillon et l'évolution de l'historique. Depuis quelques années, Logilab utilise et encourage le projet Heptapod, qui est fork amical de GitLab permettant d'utiliser à la fois Mercurial et Git.
Nous espérons que l'émission aura intéressé des auditeurs non-techniques et remercions chaleureusement les organisateurs pour leur invitation.
Pour plus de détails, écoutez le podcast de la 160ème de "Libre à vous" ou lisez la transcription de l'émission ! L'édition 2022 de la conférence International Semantic Web Conference (ISWC) dédiée au Web sémantique s'est tenue intégralement en ligne du 23 au 27 octobre 2022. Les vidéos des présentations ont été mises à disposition sur le site, ce qui a rendu assez agréable leur visionnage à tête reposée malgré les contraintes d'emploi du temps que nous pouvions avoir.
Le nombre de présentations et de tables rondes auxquelles ont participé les entreprises Bosch et Siemens nous semble révélateur de l'intégration de plus en plus concrète du Web sémantique dans des applications industrielles comme l'Internet des objects (IoT) ou le jumeau numérique.
Les retours d'expérience de ces entreprises démontrent l'utilité des ontologies pour l'interopérabilité entre bases de données précédemment silotées. La structure ou la couverture des ontologies ne sied cependant pas toujours aux données ou aux applications qui doivent les utiliser et des stratégies de contournement sont parfois mises en place, comme l'ont montré les deux articles suivants.
Le premier, Ontology Reshaping for Knowledge Graph Construction: Applied on Bosch Welding Case, met le doigt sur le fait que la structure d'une ontologie est souvent plus complexe que les données qu'on souhaite lui faire représenter, ce qui amène à générer des blank nodes, qui accroissent la taille du graphe de connaissance et rendent plus difficile son interrogation. Nous avons déjà expérimenté ce genre d'inconvénients sur des projets clients et avons trouvé intéressant de voir la liberté prise dans cet article par rapport à l'ontologie originelle.
Le second, SeLoC-ML: Semantic Low-Code Engineering for Machine Learning Applications in Industrial IoT, présente l'interfaçage entre des réseaux de neurones déjà entraînés et des descriptions d'objets connectés suivant la recommandation du W3C WoT Thing Description (TD). Nous connaissons bien cette ontologie car nous participons à sa mise au point dans le cadre de notre collaboration avec Siemens. Dans cet article, le choix qui a été fait est de convertir les descriptions d'objets décrites avec l'ontologie TD dans une nouvelle ontologie dédiée aux besoins de l'application.
Nous travaillons depuis peu sur le Web sémantique appliqué au domaine industriel et espérons pouvoir à notre tour présenter des résultats lors d'une prochaine conférence de cette ampleur ! Merci à tous les participants à la conférence SemWeb.Pro qui a eu lieu le 8 novembre dernier à Paris. Cette édition 2022 était enfin l'occasion de se retrouver en présentiel pour discuter des dernières évolutions techniques et des projets en cours.
Le programme était riche de douze présentations variées qui ont cette année encore démontré que le web sémantique se diffuse et s'utilise désormais partout: ministère des finances, nautisme, santé, culture, agronomie, télévision, etc. Les captations vidéo sont disponibles sur PeerTube.SemWeb.Pro.
La prochaine édition de la conférence SemWeb.Pro, qui se tiendra fin octobre 2023, est déjà en préparation. Si vous souhaitez recevoir les annonces, abonnez-vous à la liste de diffusion en envoyant un mail à contact at semweb.pro ou au compte semwebpro@mastodon ! Nous étions présents les 8 et 9 novembre 2022 au Palais des congrès à Paris pour Open Source Experience, qui est le rendez-vous européen de l'écosystème Open Source.
Nous avons reçu des visites sur notre stand, où nous proposions principalement nos formations à Python et aux autres outils et techniques que nous utilisons au quotidien : Web sémantique, Salt, GitLab, Docker, Mercurial, etc.
Lors des conférences, nous avons présenté CubicWeb-as-a-Service, grâce auquel nous pouvons désormais, à partir d'une ontologie OWL et de données RDF, construire et déployer en deux clics une application Web sur nos clusters Kubernetes.
Comme tous les ans, nous avons eu plaisir à discuter longuement avec les membres des entreprises et associations qui portent et défendent les valeurs du logiciel libre. Nous aurons probablement l'occasion de reparler ici des projets qui devraient découler de ces échanges passionnants. Ce week end, samedi 19 et dimanche 20 novembre, aura lieu le Capitole du libre à Toulouse. Cet évènement est toujours important dans notre calendrier car Logilab porte depuis sa création les valeurs du Logiciel Libre et dispose de locaux à Paris et à Toulouse. Nous serons donc, cette année encore, sponsor de cette conférence et prévoyons d'assister à de nombreuses présentations.
Nous présenterons, le samedi 19 novembre à 17h en salle A202, les dernières avancées de nos travaux de recherche, à savoir "CubicWeb-as-a-Service: Publier des données ouvertes ‘as a service’".
Nous serons enchantés de faire de nouvelles rencontres à l'occasion de Capitole du Libre. Contactez-nous par les réseaux sociaux si vous voulez convenir d'un moment pour discuter. Au plaisir de vous croiser cette fin de semaine à Toulouse ! 
Nous avons le plaisir de vous annoncer le programme de la conférence SemWeb.Pro 2022, que Logilab organise tous les ans depuis 2011 et qui réunit les professionnels du Web sémantique.
Après deux années chamboulées par la pandémie qui nous a imposé d'innover avec des conférences virtuelles dont les archives sont visibles sur peertube.semweb.pro, cette édition sera (enfin!) l'occasion de se retrouver en présentiel le 8 novembre 2022 prochain de 10h à 17h au FIAP de Paris. Vous avez jusqu'au 8 octobre pour profiter du tarif préferentiel de 82€.
Cette année, nous avons la chance de bénéficier du soutien de l'AFIA (l'Association Française en Intelligence Artificielle) qui offrira des entrées gratuites aux étudiantes et étudiants qui en feront la demande.
Le programme de cette édition s'articule autour de trois thématiques: le Web Sémantique face à de gros volumes de données, le Web Sémantique pour la culture et l'avenir du Web Sémantique.
Nous présenterons avec l'École normale supérieure de Lyon nos travaux sur la publication des données extraites des registres de la Comédie française dans la session Registres de la Comédie Française: du papier aux données RDF quantitatives.
Nous espérons que cet événement tiendra ses promesses en rassemblant comme tous les ans une centaine de personnes et en leur permettant de partager leurs travaux et d'entretenir leur réseau ou de découvrir les possibilités du web sémantique. Temps de lecture 2 min (325 mots)
Nous sommes allés à la Plateforme Française en Intelligence Artificielle 2022 à Saint-Étienne cette année. Cet ensemble de conférences rassemble chaque année les acteurs de l'intelligence artificielle francophone. Nous étions très heureux et heureuses de pouvoir y participer cette année encore.

Nous avons suivi la conférence d'Ingénierie des Connaissances, qui est la plus proche de notre domaine d'expertise. Nous y avons présenté nos travaux actuels sur OWL2YAMS et avons eu des retours positifs avec plusieurs perspectives dont nous vous ferons part dans de futurs articles.
Même si toutes les présentations étaient enrichissantes (nous avons appris beaucoup de choses !), nous avons choisi d'en mettre trois en lumière.
DAGOBAH est un outil permettant de générer un graphe RDF à partir d'un fichier CSV, en alignant au passage les données avec Wikidata et DBPedia. Cet outil est arrivé premier à SemTab 2021, un challenge de sémantisation de données tabulaires. Cet outil, que nous avions déjà vu lors de SemWeb.Pro 2021 pourrait nous servir de base de départ pour les projets de sémantisation de données CSV, mais ses conditions d'utilisation (libre ou non ?), restent à préciser.
Un état de l'art sur la négociation de contenu a été présenté. Il catégorise les approches existantes et ouvre des perspectives en proposant de la négociation de contenu par vocabulaire ou par forme SHACL sur les données RDF disponibles. Nous allons voir comment utiliser ces résultats dans nos travaux sur la négociation de contenu dans CubicWeb. Les dernières propositions, si elles sont standardisées, pourraient être utiles dans notre navigateur pour le web de données.
Le projet ATLANTIS a pour but de sémantiser des instructions nautiques, jusque là conservées dans un document textuel, afin de simplifier la recherche en leur sein. Ce projet est une application très concrète des technologies du Web sémantique, qui montre comment elles peuvent aider les utilisateurs et utilisatrices. Nous essayons, à Logilab, de promouvoir les mêmes idées à travers de projets comme data.bnf.fr, ou encore FranceArchives. Temps de lecture estimé 3 minutes.
Dans les articles précédents nous avons utilisé Pandas pour analyser un jeu de données, et avons créé des graphiques interactifs avec un calepin Jupyter. Cet article conclut la série en montrant comment utiliser Voilà et Jupyter-flex pour créer une application Web à partir d'un tel calepin.
Comme nous l'avons vu dans les deux premiers articles de cette série, l'utilisation de calepins Jupyter améliore le flux de travail des chercheurs et scientifiques depuis la phase exploratoire jusqu'à la communication des résultats. Pour un public non spécialisé, la présentation du code dans les calepins peut avoir un aspect rebutant, c'est pourquoi nous allons maintenant examiner Voilà et Jupyter-flex, qui permettent de créer facilement des tableaux de bord à partir des calepins.
Voilà
Voilà est un outil très simple qui permet de transformer nos calepins en applications web ou en tableaux de bord.
Voilà cache le code et affiche seulement le texte, les widgets et les résultats des calculs réalisés par le code, y compris les graphiques. Il se lance avec la commande voila <mon-calepin.ipynb>.
Si l'on reprend nos exemples précédents, cela donne :

Et si l'on reprend nos tableaux :
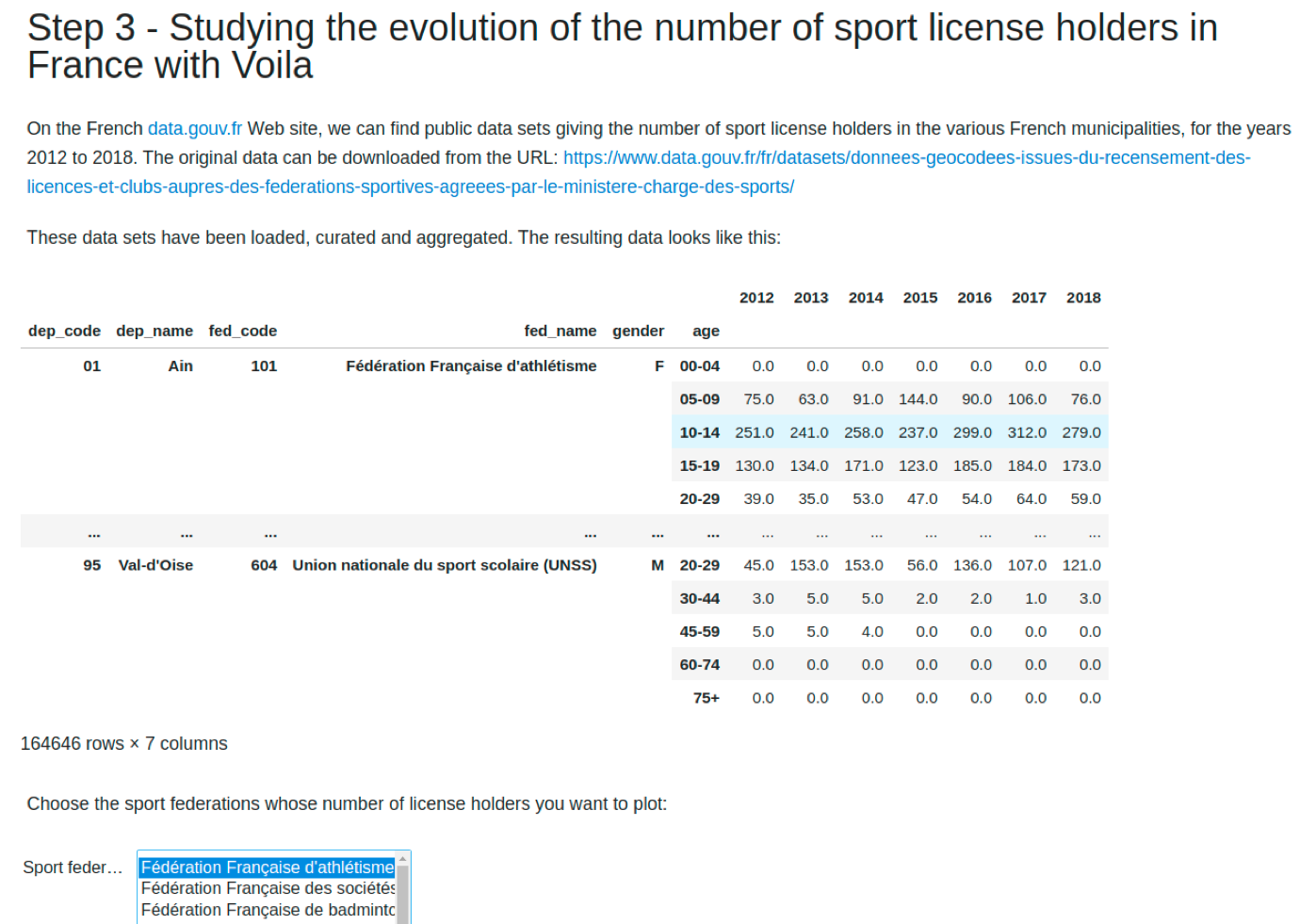
Le document reste interactif et on peut jouer avec, tout comme on le ferait avec un calepin, mais sans intervenir sur le code.
Jupyter Flex
Jupyter-flex quant à lui permet de créer des tableaux de bord HTML basés sur des calepins Jupyter. Il suffit pour cela d'ajouter un tag body dans la ou les cellules que l'on souhaite afficher dans le tableau de bord, puis de lancer la commande jupyter nbconvert --to flex <mon-calepin.ipynb> --execute qui exécutera toutes les cellules du calepin et retournera un joli tableau de bord composé avec les cellules taguées.
À noter : si nous utilisons la commande précédente, nous obtenons une version statique, ce qui peut être le comportement souhaité pour un tableau de bord. Si nous lançons le calepin avec Voilà, nous avons un tableau de bord dynamique.
Chez Logilab, nous utilisons Jupyter-flex pour notre tableau de bord interne. Couplé à la CI, il est mis à jour régulièrement.
Nous avons utilisé Jupyter et Jupyter-flex dans le cadre de projets clients, notamment le projet Resourcecode pour l'IFREMER (Institut Français de Recherche pour l'Exploitation de la Mer) et ses partenaires.
Les outils créés à cette occasion sont visibles dans la page ResourceCodeTools et le code disponible dans l'entrepôt GitLab de l'Ifremer.
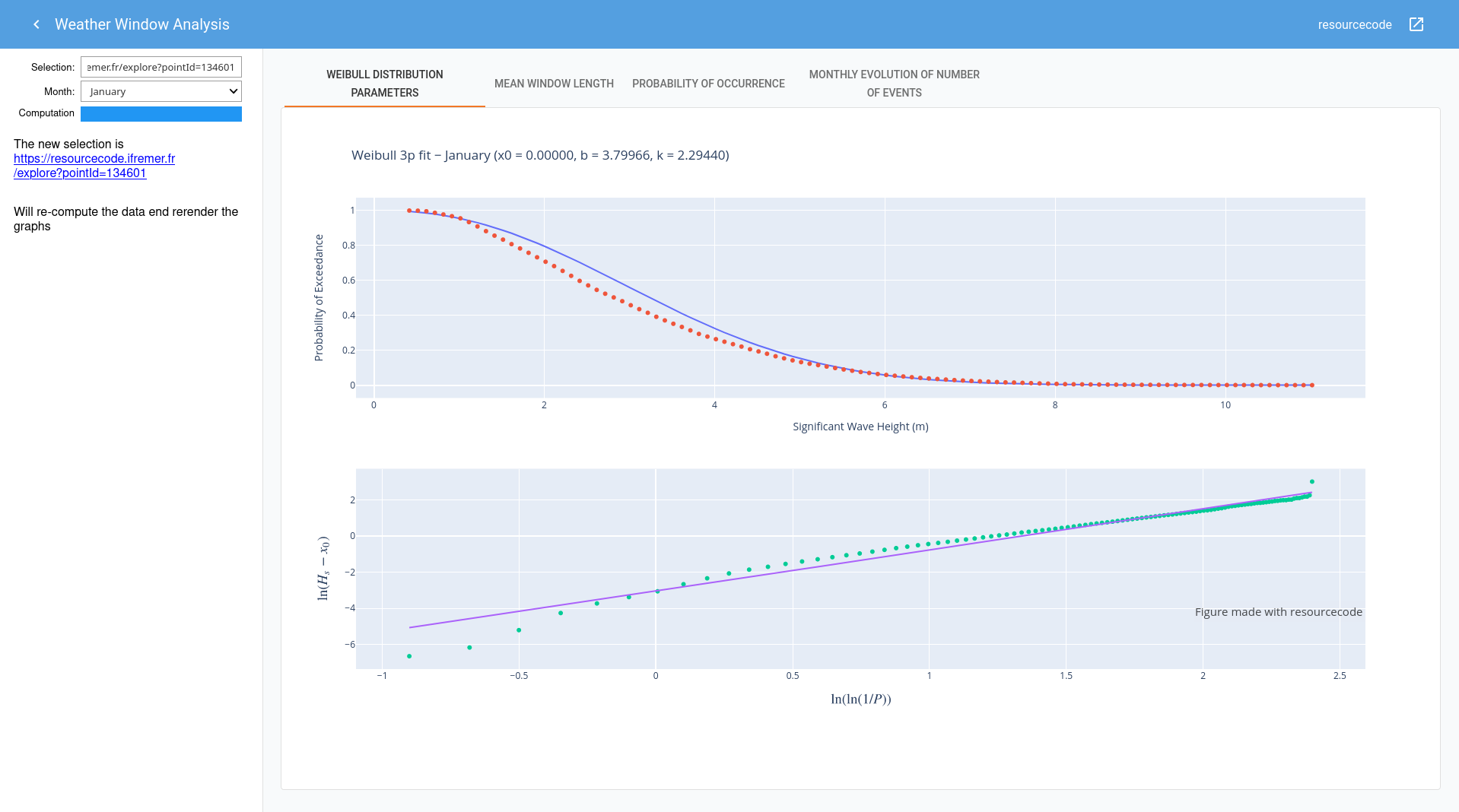
Comme on le voit dans cette illustration tirée du projet Resourcecode, on peut ajouter un menu latéral, des onglets ou une infobulle d’information. Jupyter-flex propose une architecture Cards -> Section : une Card (encart) contient une ou plusieurs cellules (code ou markdown) taguées (body, source, footer, ou même help pour afficher un modal) et une Section est constituée d'un ou plusieurs encarts que l'on affiche en colonnes ou en rangées. Jupyter-flex utilise Material UI qui s'appuie sur Grid qui est basé sur CSS Flexbox.
La documentation de Jupyter-flex est claire et comporte bien d'autres informations et options intéressantes, notamment pour la mise en page ou pour l'association Voilà et Jupyter-flex.
Note : à la date où nous écrivons, Jupyter-flex n'est pas compatible avec les dernières versions de Voilà ce qui devrait être rapidement résolu. Temps de lecture estimé à 5 minutes.
Cet article explique notre reflexion sur le choix de la technologie la plus adaptée entre React Admin et Refine pour refaire l'interface de notre cadriciel CubicWeb.
Le stage d'Arnaud Vergnet s'est déroulé sur le premier semestre 2022 et son objectif était de réaliser une interface d'administration pour CubicWeb en React, en remplacement de l'interface web générée par CubicWeb.
La communauté React est très active et on trouve de de nombreuses bibliothèques pour résoudre des problèmes récurrents, dont la réalisation d'interfaces d'administration. La première étape consistait donc à faire un état de l'art des différentes technologies disponibles pour réaliser de telles interfaces.
De nombreuses technologies sont disponibles, mais deux se sont démarquées par la richesse de leurs fonctionnalités et leur communauté active: Refine et React Admin. Cet article va donc présenter et comparer ces deux bibliothèques ainsi que présenter le choix qui a été fait pour la suite du stage.
Cette technologie est récente (créée en 2021). C'est une bibliothèque sans affichage (headless) de création d'interface d'administration. Cette technologie est donc indépendante de la bibliothèque de composants graphique utilisée et s'occupe seulement de la phase de récupération et modification de données grâce à des hooks React. L'avantage de cette méthode est qu'elle permet de créer plus que des interfaces d'administration car elle ne s'occupe que de la gestion des données. Il est donc possible de créer une interface complètement customisée.
Malgré le fait d'être découplée d'une bibliothèque graphique, cette technologie propose tout de même une intégration out-of-the-box avec la bibliothèque Ant Design. Ces composants sont donc directement utilisables avec Refine sans avoir à construire une couche de compatibilité. Ant Design propose de nombreux composants de haute qualité et possède une communauté très active.
Cette technologie est bien établie (créée en 2016) et propose une solution centrée sur la création d'interface d'administration. Ici de nombreux composants utilisant la bibliothèque MUI sont proposés, ainsi que de nombreux hooks React pour créer ses propres composants. MUI est une autre bibliothèque de composants React très populaire suivant les règles Material Design de Google. Grâce à cette intégration avec une bibliothèque de composants, il est possible de créer une interface d'administration en peu de temps et de lignes de code.
Comparaison
Les deux bibliothèques reposent sur le même principe: l'utilisateur doit écrire un objet appelé Data Provider décrivant les méthodes pour interagir avec le serveur de données, réalisant ainsi une couche d'abstraction sur les données. Les figures 1 et 2 présentent l'interface de ces objets pour Refine et React Admin et nous pouvons remarquer que ces interfaces sont similaires. Il serait donc possible de réutiliser tout ou une partie de cet objet entre les deux technologies, améliorant ainsi leur interopérabilité.
Figure 1 : Data Provider de React Admin

Figure 2 : Data Provider de Refine

Comme nous pouvons le voir en figure 3, en plus de cette ressemblance pour le Data Provider, Refine et React Admin gardent une approche semblable pour résoudre le problème de génération d'interface, simplifiant encore leur interopérabilité. La différence réside principalement dans les bibliothèques de composants graphiques compatibles et donc leur utilisation finale.
Figure 3 : Comparaison de Refine et React Admin
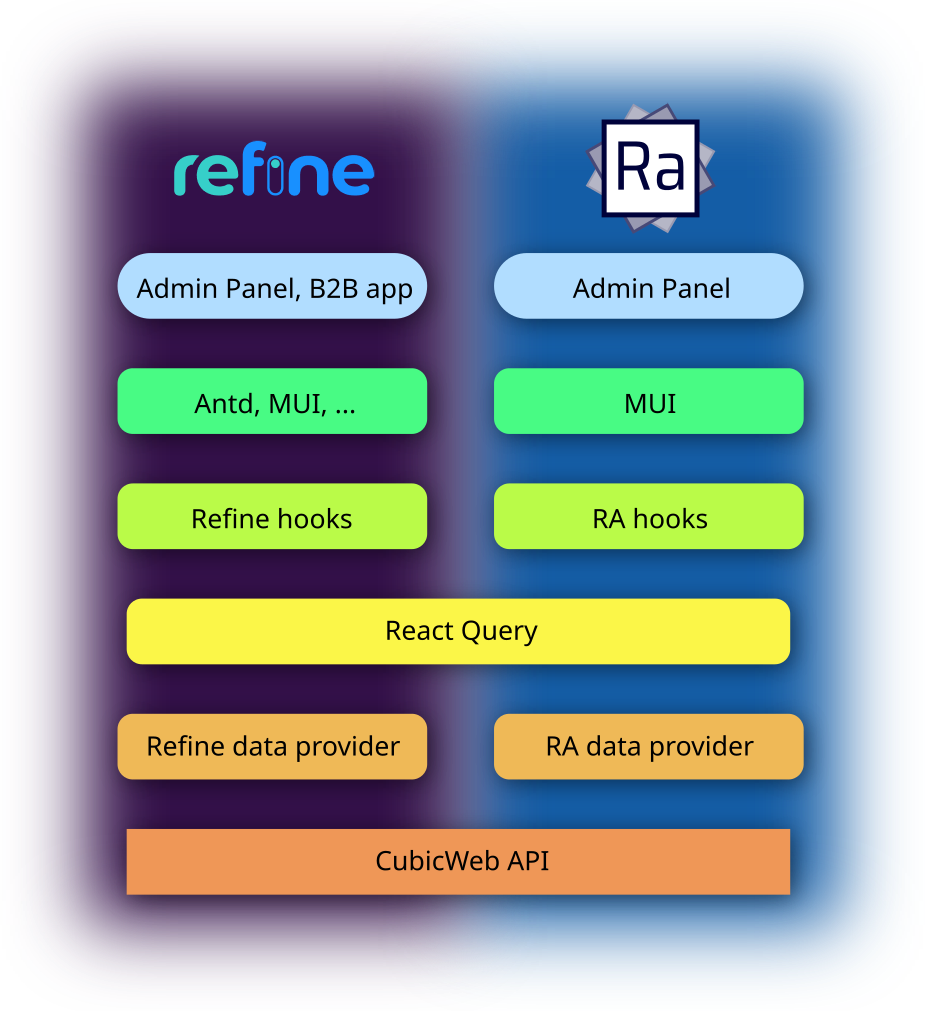
Dans les deux cas il est possible de gérer les permissions et l'authentification. Les deux supportent aussi TypeScript pour avoir un typage fort afin de détecter les erreurs rapidement. Ant Design et Material design sont tout deux des bibliothèques matures avec une grande richesse de composants.
Ces points communs rendent le choix de technologie non-trivial et expliquent pourquoi il a été décidé de se concentrer principalement sur ces deux bibliothèques. Malgré toutes ces similarités, certaines différences ont fait pencher la balance vers une des deux technologies.
La première différence est le support de ces bibliothèques. React Admin a été créé en 2016 (React lui-même datant de 2013) et les développeurs (l'entreprise Marmelab) le maintiennent et ajoutent toujours des fonctionnalités. La version 4 est sortie pendant le stage d'Arnaud et le support réagit dans de courts délais. Refine est aussi activement maintenu par l'entreprise Pankod, mais le projet est beaucoup plus récent (début 2021), il est donc plus difficile d'estimer si le projet durera dans le temps. React Admin est donc un choix plus adapté en termes de stabilité.
Une autre différence majeure est sur l'utilisation de bibliothèques de composants d'interface. React Admin est fait pour marcher avec MUI et il serait difficile d'utiliser une autre bibliothèque sans tout réécrire. Refine quand à lui fonctionne par défaut avec Ant Design mais peut fonctionner avec n'importe quelle bibliothèque de composants. Cette liberté peut être utile pour s'adapter à n'importe quelle situation et client. En revanche il devient alors plus complexe de réaliser de simples interfaces comparé à React Admin. Pour faire une interface d'administration moderne sans besoins particuliers de design, React Admin offre alors une plus grande facilité et rapidité de développement.
Suite à cet état de l'art, il a été choisi d'utiliser React Admin pour réaliser l'interface d'administration de CubicWeb auto-générée. Refine n'est tout de même pas abandonné. Grâce au système de data provider adopté par les deux technologies, il sera possible d'adapter la logique utilisée pour React Admin à Refine. Il sera ainsi possible d'utiliser Refine pour développer des applications utilisateurs plus complexes si le besoin se fait sentir.
Suite ?
Tous ces développements sont Open-Source et vous pouvez retrouver le code permettant d'adapter React Admin à CubicWeb sur la forge de Logilab. Temps de lecture estimé 10 minutes.
Dans un article précédent nous vous proposions une analyse de données à l’aide de la bibliothèque Pandas. Nous y avions construit une série de graphiques simples pour réaliser cette analyse. Dans cet épisode, nous allons aborder les widgets qui vont nous permettre de rendre ces graphiques dynamiques.
Il est conseillé d’avoir lu l’article précédent qui détaille la structure des données utilisées.
Qu’est-ce qu’un widget ?
Dans un calepin jupyter, le code peut facilement être édité et rejoué. Il est donc assez simple d’effectuer des changements. Il est toutefois possible que les utilisateurs finaux de l’application ne sachent pas programmer ou simplement qu’on préfère avoir un moyen simple d'interagir (sans avoir à relire le code Python et à le modifier). Dans de tels cas, les widgets constituent une bonne solution.
Les widgets sont des objets qui sont rendus dynamiquement dans les calepins Jupyter, et avec lesquels il est possible d’interagir.
La bibliothèque de base pour construire ces widgets est ipywidgets.
Dans l’exemple ci-dessous, la bibliothèque est importée puis un curseur glissant est construit.
>>> import ipywidgets as ipw
>>> ipw.IntSlider(min=0, max=20, step=2)
À l’exécution de la cellule Jupyter, le widget est affiché.

La connexion entre le widget affiché dans la page Web et l’objet python a été automatiquement définie. Cela signifie que si l’objet python est modifié, le rendu du widget est modifié et vice-versa. Dans le cas présent, l’attribut value du widget vaut 6.
À titre d’exemple, on peut construire un curseur glissant comme ceci :
>>> slider = ipw.IntSlider(min=0, max=20, step=2)
>>> slider
puis modifier dynamiquement la valeur de cet objet. Le rendu sera alors mis à jour.
>>> from time import sleep
>>> for i in range(0, 22, 2):
... sleep(1)
... slider.value = i

Les widgets deviennent très intéressants dès lors que l’on associe des fonctions python à des évènements. Dans l’exemple ci-dessous, nous avons défini deux widgets de type “curseur glissant” et un widget d’affichage. Nous voulons afficher dans ce dernier widget la somme des deux curseurs.
On construit un widget de type Bouton, et on associe le clic sur ce bouton à l’appel de la fonction compute_add qui somme les valeurs des deux curseurs et met à jour l’affichage.
>>> from IPython.display import clear_output
>>> sld1 = ipw.IntSlider(min=0, max=20)
>>> sld2 = ipw.IntSlider(min=0, max=20)
>>>
>>> out = ipw.Output()
>>> with out:
... print("0 + 0 = 0")
...
>>> def compute_add(evt):
... with out:
... clear_output()
... res = sld1.value + sld2.value
... print(f"{sld1.value} + {sld2.value} = {res}")
...
>>> btn = ipw.Button(description="Sum")
>>> btn.on_click(compute_add)
>>> ipw.HBox([ipw.VBox([sld1, sld2, btn]), out])
Le rendu est alors le suivant :

Utiliser un widget pour sélectionner les données à afficher
Dans l’épisode précédent, nous avions écrit une fonction pour charger toutes les données des licenciés inscrits dans les fédérations sportives pour les années 2012 à 2019. La fonction est la suivante :
>>> from pathlib import Path
>>> import pandas as pd
>>> DATA_DIR = Path().resolve() / "data"
>>> def load_data():
... year_dfs = []
... for year in range(2012, 2019):
... fname = f"sport_license_holders_{year}.csv"
... yr_df = pd.read_csv(
... DATA_DIR / fname,
... dtype={"dep_code": str},
... index_col=["dep_code", "dep_name", "fed_code", "fed_name", "gender", "age"],
... )
... yr_df.rename(columns={"lic_holders": str(year)}, inplace=True)
... year_dfs.append(yr_df)
... data = pd.concat(year_dfs, axis=1)
... return data
...
>>> d = load_data()
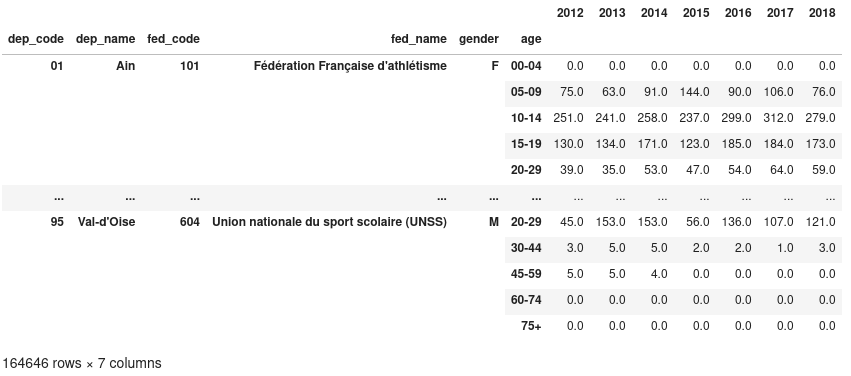
Le DataFrame résultant contient plus de 1.6 millions de lignes et 7 colonnes. Nous pouvons maintenant écrire une fonction très simple qui affiche l’évolution du nombre de licenciés de 2012 à 2019 pour les fédérations qui sont données en paramètre.
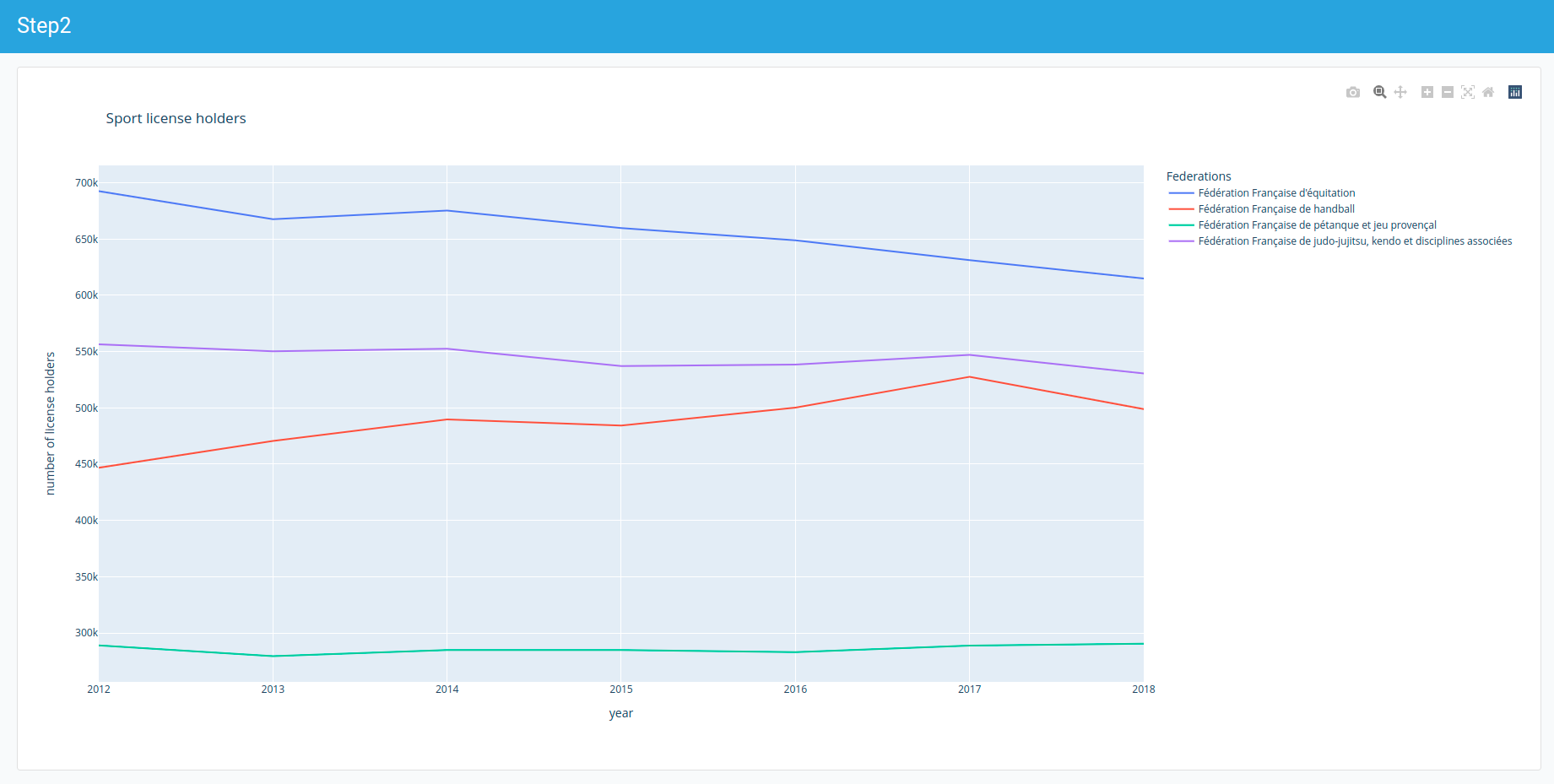
>>> pd.options.plotting.backend = "plotly" # Choose Plotly as the plotting back-end
>>> def plot_license_holders_evolution_by_sport(data, fed_codes):
... data_sports = data.groupby(level=["fed_code", "fed_name"]).sum()
... sel_data_sports = data_sports.loc[list(fed_codes)]
... sel_data_sports = sel_data_sports.droplevel(0)
... sel_data_sports.index.name = "Federations"
... fig = sel_data_sports.transpose().plot(title="Sport license holders")
... fig.update_layout(xaxis_title="year", yaxis_title="number of license holders")
... return fig
...
>>> plot_license_holders_evolution_by_sport(d, [109, 115, 242, 117])
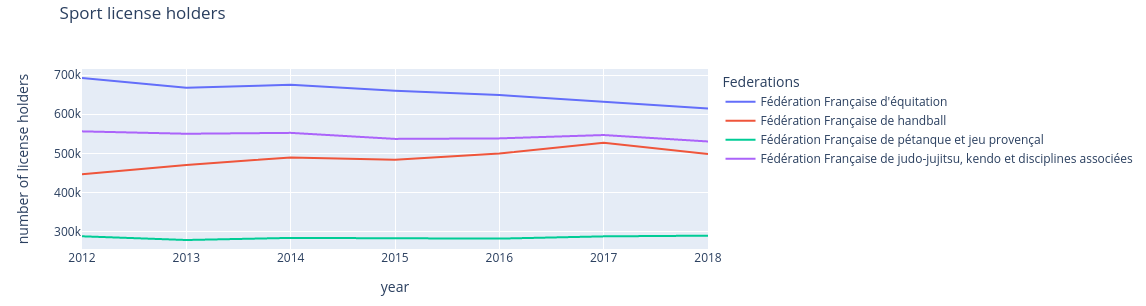
Nous souhaitons utiliser un widget proposant de sélectionner une ou plusieurs disciplines, puis afficher le graphique correspondant lorsque la sélection est validée.
La première chose que nous réalisons est un dictionnaire contenant en clef le nom des fédérations sportives et en valeur leur numéro associé. Ce dictionnaire pourra être fourni à un widget de type SelectMultiple.
Nous utilisons le code suivant pour obtenir le dictionnaire de correspondance :
>>> def extract_federation_names_codes(data):
... codes = data.index.get_level_values(
... "fed_code"
... ) # Extract all the values from the level ``fed_codes`` of the index
... names = data.index.get_level_values(
... "fed_name"
... ) # Extract all the values from the level ``fed_names`` of the index
... dic = {name: code for code, name in zip(codes, names)}
... return dic
...
Et finalement, la fonction suivante permet de construire l’interface souhaitée :
>>> from IPython.display import display
>>> def build_gui(data):
... fed_values = extract_federation_names_codes(data)
... fed_wdg = ipw.SelectMultiple(
... options=fed_values, description="Sport federations", rows=20
... )
... plt_btn = ipw.Button(description="Plot")
... out_wdg = ipw.Output()
... # Define the hook function that will be called each time the button is clicked
... def refresh_plot(evt):
... fed_codes = fed_wdg.value
... with out_wdg:
... clear_output()
... display(plot_license_holders_evolution_by_sport(data, fed_codes))
...
... plt_btn.on_click(refresh_plot)
... gui_wdg = ipw.HBox([ipw.VBox([fed_wdg, plt_btn]), out_wdg])
... return gui_wdg
...
>>> build_gui(d)
Nous venons ainsi de faire une fonction qui construit une interface utilisateur, composée d’un widget permettant de faire une sélection multiple. Lorsque la sélection est validée, la fonction d’affichage du graphique est rappelée, mettant ainsi le composant à jour. Le développement de cette interface utilisateur est bien plus simple que ce que nous aurions eu à faire avec d'autres solutions comme Qt, Tkinter ou même Flask + Javascript.
On voit que cela permet à tous les utilisateurs de faire leur propre analyse sans avoir à changer une seule ligne de code.
Dans le prochain épisode, nous présenterons Voila qui permet de transformer un calepin Jupyter en une petite application Web, utilisable sans aucune connaissance de Python. Nous utiliserons également jupyter-flex pour obtenir une jolie application Web dotée de bulles d’aides, d’onglets et d’un menu latéral. Temps de lecture 2 min (350 mots)
Chaque année, Logilab organise la conférence SemWeb.Pro. Cette conférence regroupe plusieurs acteurs du monde des technologies du Web Sémantique pour discuter de leur application dans le cadre d'activités commerciales et industrielles. Pour cela des responsables de projets dans des entreprises, des universitaires, des étudiants et étudiantes, des indépendantes et indépendants, viennent présenter leurs derniers travaux devant la communauté de semweb.pro.
Ces présentations ont plusieurs objectifs :
- démontrer des résultats obtenus avec des applications en production
- faire connaitre et confronter des idées novatrices et de nouveaux projets
- réfléchir et échanger collaborativement sur les évolutions du Web Sémantique dans le monde industriel
- créer un réseau de personnes travaillant sur et avec ces sujets afin de créer de nouvelles opportunités pour chacun et chacune
Dans ce cadre, SemWeb.Pro est devenue une référence, et est attendue chaque année. Malgré les contraintes imposées par la pandémie de ces dernières années, la conférence a continué à avoir lieu à travers des outils de visio-conférence et la communauté a poursuivi les échanges et les discussions.
L'édition 2022 aura lieu le 8 novembre à Paris près de Denfert-Rochereau et nous nous réjouissons de pouvoir retrouver tout le monde en personne plutôt que par écran interposé. Nous vous tiendrons informés, via ce blog et les réseaux sociaux, de l'appel à communication.
Cette année, l'Association Française en Intelligence Artificielle) a décidé de soutenir la conférence. Ce parrainage va se concrétiser en deux actions:
- les étudiants et les étudiantes pourront assister à la conférence gratuitement grâce à des subventions de l'AFIA (nous vous communiquerons les modalités pour obtenir ces subventions lorsqu'elles seront établies).
- l'AFIA va communiquer sur différents canaux l'appel à communication et à participation à la conférence, pour accroître encore l'audience et la taille de la communauté.
Nous remercions chaleureusement l'AFIA et plus particulièrement Catherine Roussey et Sylvie Desprès (coordinatrices du collège Ingénierie des Connaissances de l'AFIA) pour avoir proposé ce parrainage. Nous sommes très fier que SemWeb.Pro soit reconnue comme participant au rayonnement de l'Intelligence Artificielle française. Temps de lecture 2 min (350 mots)
La Plateforme Française en Intelligence Artificielle a lieu tous les ans. Cette plateforme regroupe le fleuron de la recherche scientifique concernant l’intelligence artificielle en France. Elle regroupe sept conférences différentes, toutes concernant une branche de l’intelligence artificielle :
Conférence Nationale sur les Applications Pratiques de l’Intelligence Artificielle (APIA)
Conférence Nationale en Intelligence Artificielle (CNIA)
Journées Francophones d’Ingénierie des Connaissances (IC)
Journées Francophones sur la Planification, la Décision et l’Apprentissage pour la conduite de systèmes (JFPDA)
Journées Francophones sur les Systèmes Multi-Agents (JFSMA)
Journées d’Intelligence Artificielle Fondamentale (JIAF)
Rencontre des Jeunes Chercheurs en Intelligence Artificielle (RJCIA)
Logilab, qui s’est spécialisée dans les technologies du Web Sémantique, participe régulièrement, comme auditrice ou autrice, à la conférence IC, puisque c’est dans celle-ci que sont discutées les avancées concernant le Web Sémantique et le Web de données liées.
On peut, par exemple, citer nos publications dans cette conférence en 2019, Un navigateur pour le Web des données liées, ou en 2020, CubicWeb : vers un outil pour des applications clé en main dans le Web Sémantique.
Nous apprécions les échanges que nous avons lors de cette conférence et c’est donc chaque année avec plaisir que nous y participons. De plus, la tenue au même moment et au même endroit des conférences connexes nous offre l’opportunité de découvrir de nouveaux sujets qui peuvent élargir notre horizon et nous donner des pistes à suivre lors de nos prochaines réalisations.
Après tous ces éloges pour la plateforme, il n’est pas surprenant que nous ayons décidé d’être sponsor de PFIA2022 qui se tiendra à l’École des Mines de St Etienne du 27 juin au 1er juillet. Il nous a paru naturel de soutenir une initiative qui nous semble centrale quant à l’évolution de la recherche scientifique française en intelligence artificielle.
Nous profitons de cet article pour annoncer que nous allons présenterons la suite de nos travaux de recherche lors de la session 9 de IC, le vendredi matin à 9h. Cette présentation s’intitule “OWL2YAMS : créer une application CubicWeb à partir d’une ontologie OWL”. Nous sommes impatients de pouvoir échanger sur ces sujets et de découvrir toutes les autres présentations.
On se donne rendez-vous à St Etienne ? Temps de lecture 2 min (400 mots)
Dans le cadre de son stage de fin d'étude à Logilab, Arnaud à été amené à travailler avec des projets JavaScript (CubicWebJS et react-admin-cubicweb) nécessitant un processus d'intégration continue (CI) qui s'exécute sur notre forge heptapod.
Pour éviter de répéter le code décrivant la CI, Arnaud a écrit plusieurs scripts à utiliser comme patrons dans les projets JavaScript. Ces scripts sont intégrés au projet gitlab-ci-templates. Ils supposent l'utilisation de nodejs et sont compatibles avec yarn et npm. La détection se fait automatiquement : si le fichier yarn.lock est présent à la racine du projet, yarn est utilisé, sinon c'est npm. L'image de base utilisée pour tous ces scripts est node:latest, si vous avez besoin d'une version spécifique, vous pouvez remplacer latest par la version de votre choix en surchargeant le script dans votre projet.
Voici un bref descriptif des différents scripts disponibles :
- js-install : installe les dépendances listées dans le fichier
package.json et génère un artifact avec le dossier node_modules (ou les dossiers si on est dans le cas d'un workspace yarn). Cette installation est utilisable par les étapes suivantes si elles incluent js-install en tant que dépendance.
- js-lint : lance la commande
lint spécifiée dans le fichier package.json.
- js-test : lance la commande
test spécifiée dans le fichier package.json.
- js-build : construit le projet avec la commande
build spécifiée dans le fichier package.json. Il peut être utile de générer un artifact avec le résultat du build pour le rendre utilisable lors d'une autre étape.
- npm-publish : publie le projet sur npmjs.com. Ce script n'est lancé que lorsqu'un tag est détecté et seulement si les scripts de test, lint et build précédents ont réussi (ces scripts étant optionnels). Si vous avez généré un artifact avec le résultat du build, il sera disponible ici pour publication. Ce script considère qu'il existe une variable d'enrivonnement
NPM_TOKEN contenant le token de connexion pour la publication. Il est possible de spécifier ce token comme variable cachée dans GitLab (et donc dans Heptapod).
- webpack-publish : compile le projet en utilisant webpack et génère un artifact avec le dossier
public pour préparer le déploiement sur les Gitlab pages. Ce script n'est executé que sur la branche default et seulement si les scripts de test, lint et build précédents ont réussi (ces scripts étant optionnels). Si vous avez généré un artifact avec le résultat du build, il sera disponible ici pour publication.
- gitlab-pages : Publie le contenu du dossier
public sur les Gitlab pages du projet. Ce script n'est executé que sur la branche default. Pour l'utiliser dans vos projets, vous aurez besoin de définir vous-même ses dépendances pour pouvoir publier les résultats de compilation.
Voici un exemple de l'utilisation de ces scripts dans le projet react-admin-cubicweb :

N'hésitez pas à utiliser ces scripts dans vos projets JavaScript, ils sont faits pour ça ! Temps de lecture ~1 min (100 mots)
Dans le cadre de ses formations, Logilab à créé jupyterlab-friendly-traceback, une extension JupyterLab qui permet d'utiliser friendly-traceback de façon interactive dans les calepins Jupyter.
Le but du module Friendly-traceback est de remplacer les messages d'erreurs standards de Python par des messages plus complets et plus faciles à comprendre. Ce module permet, entre autre, d'expliquer ce qui a provoqué la levée d'une exception dans un programme.
Les informations données par Friendly-traceback ont une grande valeur pédagogique et permettent aux développeurs Python débutants, voir confirmés, de mieux comprendre les erreurs présentes dans leur code.
Pour utiliser l'extension jupyterlab-friendly-traceback, il suffit de la pip-installer dans votre environnement de la façon suivante:
$> pip install jupyterlab-friendly-traceback
Il est ensuite possible d'activer et de désactiver l'extension JupyterLab en cliquant sur un bouton qui apparaît dans la barre d'outils du calepin Jupyter.
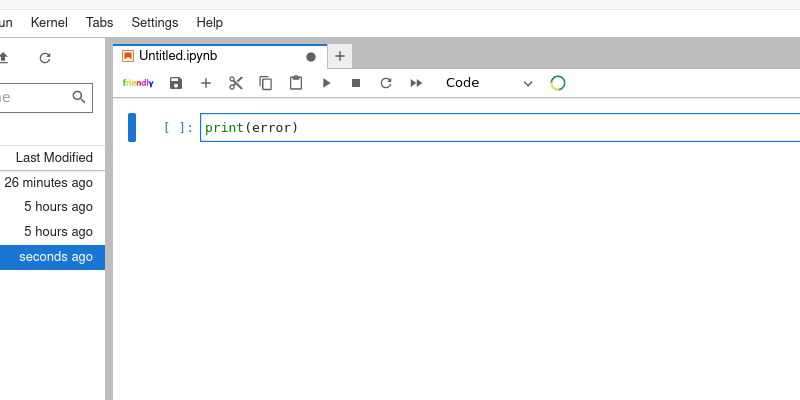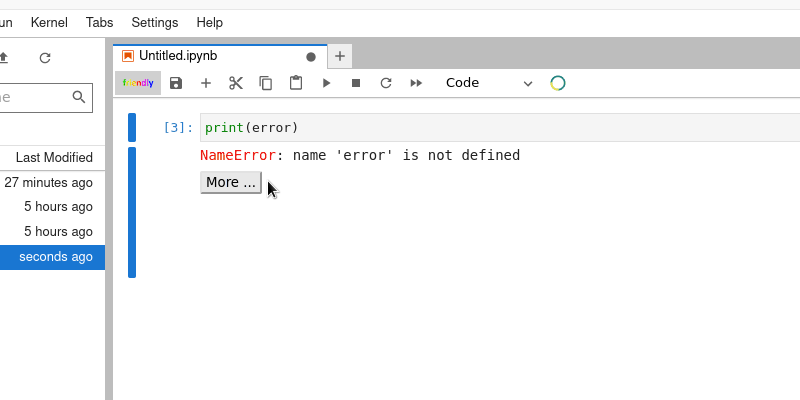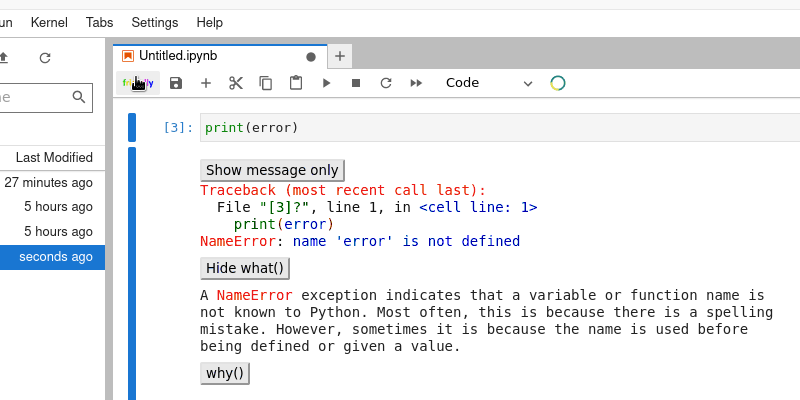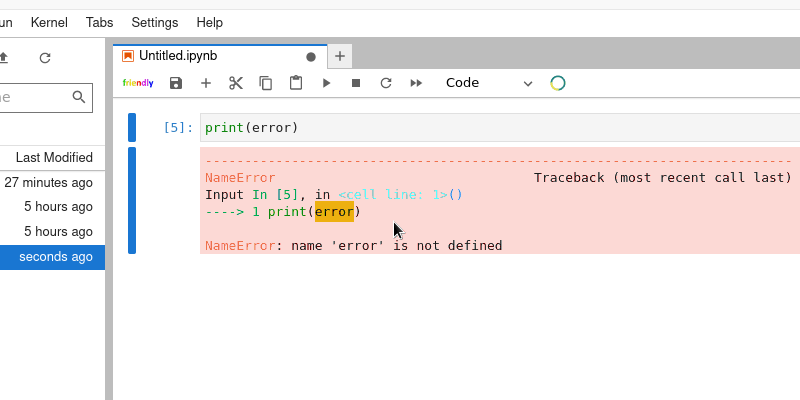
Temps de lecture 4min (~800 mots)
Nous poursuivons notre participation au libre en envoyant deux nouveaux logilabiens, Yoelis et Arnaud aux JDLL de Lyon, le rendez-vous annuel de celles et ceux qui sont curieux·ses et passionné·e·s de numérique libre et émancipé.
Ils y ont découvert l'actualité économique et les enjeux politiques inhérents à la pratique du libre. Ils ont également été surpris par la richesse de l'innovation qui se déploie dans ces espaces.
Ce week-end fût riche en idées et les résumer en quelques lignes n'est pas tâche aisée. Nous nous sommes concentrés sur quelques conférences, mais vous trouverez la liste complète de toutes les conférences.
Les différentes discussions auxquelles ont participé nos Logilabiens tournent autour de trois grandes questions.
Comment défendre nos droits et s'organiser en dehors des structures verticales et traditionnelle du pouvoir ?
Le collectif des chatons avait des choses à en dire. Les CHATONS, l'acronyme de Collectif des Hébergeurs Alternatifs, Transparents, Ouverts, Neutres et Solidaires, est un collectif d'hébergeurs citoyens. Ils permettent à chacun d'accéder à différents services hébergés (email, sites web, outils collaboratifs) près de chez eux afin que chacun puisse se réapproprier ses données et réduire sa dépendance aux GAFAM.
Les étudiants de Compiègne qui ont lancé Picasoft ont parlé de leur expérience de mise en œuvre d'un CHATONS et de la façon qu'ils ont eu de déconstruire progressivement au cours de cette expérience les structures classiques de l'organisation d'une association. Ils sont parvenus, non sans peine, à un mode de fonctionnement organique où celles et ceux qui font sont les décideurs, dans la bienveillance et l'écoute mutuelle.
Comment promouvoir la notion de commun, l'open-data et la réappropriation des données par les collectifs ?
Le langage n'est pas neutre et les dictionnaires sont imprégnés de la vision du monde de leurs auteurs et affectés par leurs conditions de production. S'il est le fruit d'un travail institutionnel, il y a un risque qu'il soit stoppé si les financements devaient s'arrêter ou si la situation politique changeait. La communauté est moins impliquée et le travail laissé à quelques sachants. La ligne éditoriale encourt un risque de censure et le contenu peut-être daté ou anachronique. Même si les projets issus de communautés ne sont pas concernés par ces problèmes, ils ont souvent du mal à atteindre les communautés érudites et ne sont pas toujours à la pointe en ergonomie et design.
Le Dictionnaire Des Francophones (DDF) a ainsi essayé de lier ces deux mondes. Basé sur les données du projet ouvert du Wiktionnaire (projet de la Fondation Wikimedia), le DDF est une initiative du ministère de la Culture pour représenter la diversité de la langue Française à travers toute la francophonie. Comparé au Wiktionnaire, le DDF possède une meilleure ergonomie et est plus facilement utilisable par d'autres applications grâce à la publication de ses données aux formats du Web Sémantique comme le RDF.
La métropole de Lyon a bien compris l'enjeu d'impliquer la communauté et mène un projet ambitieux d'ouverture de ses données. Cette initiative multiplie ainsi les possibilités de valorisation des données par les scientifiques et les journalistes. En revanche, contrairement au DDF, les données publiées ne sont pas au format du Web Sémantique, limitant les possibles utilisations. La perspective est tout de même envisagée sur le long terme.
Quels outils innovants pour l'ingénierie logicielle ?
En parallèle des conférences, nos logilabiens ont assisté à des ateliers techniques, tels que l'atelier d'initiation à Rust et à la conception d'un jeu avec Rust.
Rust est un langage de programmation à typage fort, garantissant l'absence d'erreurs de mémoire au moment de la compilation. Il est fortement inspiré de la famille du C avec une syntaxe moderne. Il permet différents styles de programmation, notamment fonctionnel. Contrairement au C et au C++, Rust utilise le gestionnaire de dépendances Cargo, similaire à Pip pour Python et NPM pour JavaScript. Rust est donc un langage système moderne possédant de nombreuses qualités pour simplifier le travail de ses utilisateurs, expliquant sa popularité en hausse.
Pijul est un nouveau système de contrôle de version ayant pour objectif de résoudre de multiples problèmes existants dans les solutions actuelles. Contrairement à Git et Mercurial qui se basent sur la théorie des snapshots, Pijul suit les pas de Darcs en s'appuyant sur la théorie des patchs. Historiquement, l'approche par snapshot possède de bien meilleures performances que celle par patchs, mais possède de nombreux problèmes lors d'opérations complexes (merge ambigus). L'objectif de Pijul est de résoudre les problèmes de performances présents chez Darcs pour créer un système performant à la Git, fiable et simple à utiliser à la Darcs.
Bilan
Participer à de tels événements est toujours une source d'inspiration pour nos logilabiens. La découverte de nouvelles technologies et de nouveaux projets libres est ce qui nourrit notre activité au quotidien. Grâce aux JDLL, Logilab sera sûrement amenée à utiliser une de ces technologies lors de projets. Nous avons hâte de retrouver tout ce joli monde à la prochaine édition ! (Titre en anglais: Learning Transformation Rules Between Bibliographical Formats Using Genetic Programming)
Temps de lecture 2 minute (~300 mots)
Nous avons l'honneur d'avoir été invités à parler de nos travaux à l'atelier RoCED qui aura lieu durant la conférence KGC 2022, en ligne, le 2 mai entre 9h et 12h EST (New-York) ou entre 15h et 18h heure française.
Cet atelier est spécialisé dans l'étude de la complexité, l'hétérogénéité, l'incertitude et l'évolution des données et des connaissances. Pour faire face à l'accroissement constant de la quantité de données et connaissances générées, il devient primordial d'appréhender ce volume pour pouvoir exploiter la connaissance sous-jacente. Cet atelier propose d'apporter des éléments de réponse à ce problème en explorant des applications d'apprentissage automatique, de fouille de données, ou de raisonnement sur des graphes de connaissance.
Dans ce cadre, Logilab (par l'intervention d'Élodie Thiéblin) présentera les résultats préliminaires d'une étude commanditée par la BnF (Bibliothèque nationale de France).
La BnF est actuellement en train de migrer son catalogue de données du format Intermarc (variante du MARC) vers le format Intermarc-NG (distingant notamment Oeuvre, Expression, Manifestation, Item). Cette migration est faite grâce à des règles écrites manuellement.
Pour préserver l'interopérabilité avec les applications qui ne traitent que le format Intermarc, il est envisagé d'apprendre la transformation inverse (Intermac-NG vers Intermarc) automatiquement. Comme la migration de données n'a pas eu complètement lieu, l'étude s'est concentrée sur l'apprentissage de règles de transformation de l'Intermarc vers le Dublin Core, basé sur un ensemble de notices bibliographiques disponibles dans les deux formats. Une preuve de concept a été développée en utilisant la programmation génétique, dont les résultats sont des règles plus ou moins complexes. Notre hypothèse est que cet apprentissage peut être appliqué à d'autres formats de données structurées.
Si vous souhaitez suivre cette présentation (et les autres présentations passionnantes prévues durant ces journées KGC) ne tardez pas à vous inscrire ici : https://www.knowledgegraph.tech/
Merci beaucoup à Nathalie Hernandez, Fathia Sais et Catherine Roussey de nous permettre de présenter nos travaux durant cet atelier.
Logilab been invited to participate in the RoCED workshop, occuring during KGC 2022.
This workshop focuses on contributions describing methods and uses-cases that rely on the application of reasoning and machine learning on complex, uncertain and evolving knowledge graphs.
We will present the preliminary results of a study commissioned by the National French Library (BnF).
The National French Library (BnF) is migrating its catalogue data from the Intermarc bibliographic format (similar to UniMARC) to Intermarc-NG with manually created rules.
To keep their data interoperable with applications which can only deal with Intermarc data for now, they would like to automatically learn the inverse transformation (Intermarc-NG to Intermarc).
The catalogue data has not been entirely migrated so far, therefore, the study focused on learning transformation rules from Intermarc to Dublin Core, based on a corpus of bibliographic records in both formats.
A proof of concept has been developed using genetic programming resulting in more or less complex rules.
We argue that this transformation rule learning algorithm could be applied to other structured data formats.
If you want to follow this presentation and other interesting talks, register here: https://www.knowledgegraph.tech/
We thank Nathalie Hernandez, Fathia Sais and Catherine Roussey for their invitation to this workshop.
|
 [
[ 