derniers billets - Carrefour de l'agrégation le 2 juin 2025
- Graphes sémantiques pour l'industrie (mars 2025)
- CapData Opéra présenté à SWIB24
- Retours sur SemWeb.pro 2024
- Forum Teratec 2024
- Forum entreprendre dans la culture en 2024
- Role Models à la radio - Le Retour
- 2ème Symposium Solid
- SemGraph pour transformer vos données en graphes sémantiques
- Logilab était au Capitole du libre 2023
- Retour sur SemWeb.Pro 2023
- Notre parcours de formation Web Sémantique
- CubicWeb 4 est disponible !
- Une journée SemWeb.pro à Toulouse !
- Retours sur la PyConFR 2023
- AFPYRo du 16 mars 2023
- CubicWeb dans le catalogue GouvTech
- SemWeb.Pro 2021 aura lieu le 9 décembre
- Négociation de contenu dans CubicWeb
- SemWeb.Pro 2019 : envoyez votre proposition avant samedi 31 août !
- Logilab soutient pgDay Lyon 2019
- La conférence Mercurial aura lieu mardi 28 mai, à Paris !
- Mini-sprint mercurial du 4 au 7 avril à Paris
- Logilab soutient pgDay Paris 2019
- Fosdem 2019, nous y étions !
- Logilab présent au Capitole du Libre 2018
- Logilab présent à Paris Open Source Summit
- Logilab soutien PyParis 2018 : consultez le programme et inscrivez-vous !
- SemWeb.Pro 2018 : utilisez le code de réduction SWEP et incrivez-vous !
- Logilab a une nouvelle adresse à Toulouse !
- Logilab présent au PyConFr 2018 !
- SemWeb.Pro 2018 : le programme est en ligne, inscrivez-vous !
- Logilab présent aux journées d'études "Documenter la production artistique : données, outils, usages"
- SemWeb.Pro 2018 : l'appel à proposition est ouvert !
- Mini-sprint mercurial du 21 au 25 mai chez Logilab
- Logilab sera présente au FOSDEM et au Config Management Camp 2018
- Meetup Nantes monitoring : netdata et sensu, c'est demain !
- Rencontres Régionales du Logiciel Libre 2017
- C'est nouveau : exposition de posters à SemWeb.Pro
- SemWeb.Pro, tarif à 67€ jusqu'au 3 novembre !
- Le meetup Python, c'est ce soir !
- Nous recrutons !
- Meetup salt, salt-cloud et formulas : jeudi 28 septembre
- SemWeb.Pro 2017
- Mise en ligne de FranceArchives.fr
- Atelier AFNOR usages du Web pour l'industrie
- PyParis 12/13 juin 2017
- Données de santé sur le Web - 23 mai 2017
- Appel à communication SemWeb.Pro 2017
- Week-end Debian de mai 2017
- Logilab vous donne rendez-vous au Paris Open Source Summit 2016
- Logilab fait maintenant partie du GT Système d'Information
- Le meetup Python Nantes monitoring c'est ce soir !
- Découvrez la présentation de Logilab aux Rencontres Régionales du Logiciel Libre
- Logilab aux Rencontres Régionales du Logiciel Libre
- Paris Web of Data - "les utilisations de schema.org" ce jeudi 06/10
- SemWeb.Pro 2016 : le programme est en ligne, inscrivez-vous !
- Paris Web of Data - les utilisations de schema.org le 6 octobre 2016
- Rencontres Régionales du Logiciel Libre - Toulouse 2016
- SemWeb.Pro 2016 : envoyez votre proposition avant vendredi 8 juillet !
- Nous avons été à Agile France 2016 !
- Nous ferons une présentation à la conférence Pydata à Paris
- Logilab soutient la conférence Pydata 2016
- Logilab vous attend sur son stand à la Convention Systematic.
- Le portail FEVIS a été lancé !
- SemWeb.Pro 2016 : l'appel à proposition est ouvert !
- Mercredi 11 mai : Paris Web of Data, les rencontres du Web de données
- Soirée Python à Nantes le 18 mai 2016
- Soirée Salt à Paris le 12 mai 2016
- Avancement du projet OpenDreamKit
- Logilab était à pgDay, à Paris !
- Logilab, un industriel du logiciel
- Libre Théâtre au Forum des Archivistes
- Présentation à Nantes Monitoring Meetup
- Raid Agile dans les Cévennes, on y a été !
- Découvrons les nouveautés de PostgreSQL 9.5 à Toulouse
- Nous avons été à FOSDEM et à Config Management Camp 2016
- [Présentation annulée] Pourquoi et comment Logilab investit dans la R&D ?
- Pourquoi et comment Logilab investit dans la R&D ?
- Logilab présente au FOSDEM et au Config Management Camp !
- Rejoignez-nous aux RRLL 2015 jeudi 3 décembre
- Bilan SemWeb.Pro 2015
- Les présentations Logilab à Paris Open Source Summit
- Capitole du Libre édition 2015 annulée
- Logilab présent à Paris Open Source Summit
- Système d'Archivage Électronique Mutualisé : prochaines présentations
- Rendez-vous aux Rencontres Régionales du Logiciel Libre à Toulouse
- Libre Théâtre : une bibliothèque numérique gratuite d'oeuvres théâtrales du domaine public se prépare
- SemWeb.Pro 2015 : Encore 2 jours pour bénéficier du tarif à 65€
- Logilab présent au Hackathon Code_TYMPAN
- 15 ans de Logilab
- SemWeb.Pro 2015 : découvrez le programme et inscrivez-vous !
- Logilab sera présent au meet-up Code_Tympan !
- Logilab fête ses 15 ans !
- Unlish, une application CubicWeb
- Lancement du blog Simulagora
- Lancement du projet OpenDreamKit
- Logilab présent à la conférence PyConFr 2015
- Logilab partenaire technique de Libre Théâtre
- Logilab au Salon du Bourget et Forum Teratec 2015
- SaltStack animera une formation du 2 au 4 septembre 2015 à Paris
- Logilab au Bibcamp 2015 de l'ADBU
- Logilab partenaire SaltStack pour assurer la formation, le support et la certification sur Salt en France et en Europe
- Logilab et l'Open Source Innovation Spring
- Sprint Salt le 4 mars 2015 à Logilab
- Nouvelle formation "Gestion de sources avec Git"
- Présentation des compétences Big Data
- Capitole du Libre - notre participation 2014
- Supports de présentation Battle OpenData - DataLab
- Logilab au Capitole du Libre les 14/15/16 novembre 2014 à Toulouse
- Logilab présente Saltstack le 3 novembre à la cantine Toulouse
- Battle des plate-formes Open Data - octobre 2014
- Conférence SemWeb.Pro le 5 novembre, programme et inscriptions
- Logilab à "Réutilisation et open data : quels enjeux pour les archives ?"
- Logilab aux Rencontres Régionnales du Logiciel Libre à Nantes
- Logilab à EuroSciPy 2014
- Logilab, une pépite du pôle Systematic
- Réunion Salt le 23 septembre 2014 à Paris
- Logilab participe à Debconf 2014
- Save the date : RRLL Toulouse le 14 novembre
- Convention Systematic 2014
- Code_TYMPAN au congrès Nafems 2014
- Test-Driven Infrastructure avec Salt à Solutions Linux 2014
- Réunion Salt le 19 mai 2014 à Paris
- Nouvelle formation "Développement de code par le scientifique"
- Prochaines sessions de formation
- Réunion Salt le 15 avril 2014 à Paris
- Python pour DevOps à Paris (mars 2014)
- Hackathon codes de mécanique (mars 2014)
- Barcamp OpenScience à Toulouse (fév 2014)
- Logilab au FOSDEM 2014
- Objectifs de Logilab en 2014
- Logilab officiellement membre d'Aerospace Valley
- Réunion Salt le 6 février 2014 à Paris
- Mini DebConf Paris 2014
- OpenCat - un catalogue de bibliothèque fondé sur data.bnf.fr
- Calendrier des sessions de formation du 1er semestre 2014
- Nouveau programme de formation Debian avancé
- Mise en ligne des données Brainomics/Localizer
- Défi CubicWeb pour la Nuit de l'info 2013
- Présentation CubicWeb à la communauté urbaine de Bordeaux
- Rencontres Régionales du Logiciel Libre et du Secteur Public
- AG actionnaires de Logilab - 2013
- Retour sur OpenWorldForum 2013
- Logilab sera présent demain au Barcamp Open Data Toulouse métropole
- Logilab sponsor du Capitol du Libre 2013 à Toulouse
- Logilab à l'OpenWorldForum 2013
- Logilab sponsor de DebConf13
- Coupure d'électricité
- Nouvelle formation "Apprentissage statistique et fouille de données avec Python"
- Nouvelles sessions de formation en rentrée 2013
- Nouvelle formation "Python pour l'analyse de données"
- Trophée de l’Excellence Documation - MIS 2013 « Data Intelligence » pour data.bnf.fr
- Nomination de Logilab aux Data Intelligence Awards 2013
- Nouvelles sessions de formation en juin / juillet 2013
- Session inter-entreprises de la formation "Développer une application avec CubicWeb"
- Prix Stanford de l'innovation pour data.bnf.fr
- CubicWeb lauréat de Dataconnexions 2013
- Logilab rejoint le cluster Digital Place
- CubicWeb à dataconnexions#2
- Calendrier formations 1er semestre 2013
- Logilab partenaire de l'IRILL
- Présentation conjointe Logilab / SNCF au séminaire NAFEMS
- Logilab participe à Agile Tour Nantes
- Stages Ingénieur 2012-2013
- Mini DebConf Paris 2012
- Nouveau catalogue de formations
- Logilab signe la Charte pour l'emploi logiciel libre
- data.bnf.fr - épisode II
- Logilab recrute à Toulouse
- Présentation à la conférence "La Fabrique de la Loi"
- Logilab au congrès Nafems 2012
- Revue de presse : Mini-interview de Sylvain Thénault sur midenews.com
- Logilab sponsor du Software Carpentry Project
- Logilab participe à la semaine de l'OpenData à Nantes
- Revue de presse : Logilab s'implante à Toulouse
- SemWeb.Pro 2012
- Lancement du projet OpenCat
- Lancement du projet ANR Niconnect
- Le site intitutionnel de Logilab fait peau neuve
- Mise à jour des formations Python numérique
- Logilab lance LibAster
- Inscrivez-vous à SemWeb.Pro 2011 - Paris
- SemWeb.Pro 2011 à Paris
- Formation CubicWeb
- Nouveaux locaux à Paris
- EuroScipy 2010 à Paris
- Lancement du projet CSDL - Complex System Design Lab
- Logilab à EuroSciPy 2009
- Logilab participe à PyconFR 2009
- CubicWeb 3.0
- Logilab à EuroPython 2008
- Logilab aux rencontres Ter@tec
- Logilab à Google I/O 2008
- Logilab participe à PyconFR
- Logilab publie LAX
- Logilab au Directoire de System@tic
- Augmentation de capital
- Livre blanc APRIL
- Annuaire 118000 et CubicWeb
- Logilab et Itaapy proposent une offre de TMA et de migration de Zope/CPS
- Sprint PyPy à Genève
- Conférence EuroPython 2006 - CERN Genève
- Paris capitale du Libre 2006
- Réunion annuelle CUPS
- Pôle de compétitivité System@tic Paris-Région
- Conférence de Logilab à XPDay France 2006
- Logilab à XPDay France 2006
- Logilab à Solutions Linux
- Sprint PyPy à Paris
- souscrire

|
BilletsLogilab était au Carrefour de l'agrégation, organisé par le Ministère de la Culture et la FEMS, qui s'est tenu le 2 juin 2025 au Mucem à Marseille. Voici notre résumé des nouvelles qui ont retenu notre attention.
La numérisation des bâtiments a commencé, avec la publication de modèles 3D, qui seront probablement consultables via une extension du protocole IIIF qui en cours de définition par le IIIF 3D community group.
Le ministère a publié une première version du profil d'application LIDO-MC accompagné d'un tableau de correspondance avec le format Joconde. Une nouvelle version sera disponible d'ici un an et ajoutera la description des données bibliographiques et de provenance, sachant que l'objectif à l'horizon 2030 est de multiplier par quatre la quantité de données par rapport à 2020.
La Plateforme Ouverte du Patrimoine (POP) a récemment bénéficié d'améliorations avec la séparation entre production et diffusion des données, des actions de sécurisation et une migration vers un cloud souverain, en l'occurence OVH. La moissonneuse de POP, qu'il n'est pour le moment pas prévu de publier en logiciel libre, nous a rappelé les fonctions de collecte de UData. UData est le logiciel libre développé et utilisé par data.gouv.fr. A Logilab nous avons une application similaire que nous utilisons par exemple pour CapData Opéra et pour GraphEthno dont nous avons justement présenté les dernières avancées lors de la journée.
Le ministère mène actuellement des actions d'accompagnement pour aider à la transformation numérique et la cybersécurité et a ouvert un guichet de financement pour les référentiels et la découvrabilité des contenus.
La conférence Europeana 2025 aura lieu les 11 et 12 juin 2025 à Varsovie et sera retransmise en ligne. C'est une bonne occasion de se tenir au courant des récentes évolutions de cet agrégateur européen des données culturelles et de l'espace européen des données patrimoniales.
Merci au Mucem pour l'invitation dans une salle de conférence avec vue sur la mer, nous y reviendrons avec plaisir ! Logilab a assisté à la mini-conférence « Graphe sémantique pour l’industrie », organisée à Paris par GrapheWise au mois de mars 2025.
Ce meetup était principalement dédié au domaine de la santé. Les intervenants ont présenté des solutions innovantes pour améliorer l'interopérabilité et l'exploitation des données dans le secteur de la santé.
Guillaume Rachez de Perfect Memory a souligné l'importance de la sémantisation des données pour les rendre accessibles et compréhensibles, en intégrant toutes les données, structurées ou non, et en les contextualisant. Il a insisté sur l'acceptation de la subjectivité des ontologies.
Chez Servier, Christopher Arnoll et Joffrey Cesbron ont montré comment ils utilisent des ontologies et des LLMs pour contextualiser les données R&D, notamment avec un graphe de connaissances et la possibilité de requêter ce graphe en langage naturel.
Thierry Dart et Yann Briand de l'Agence du Numérique en Santé ont présenté leur serveur multi-terminologie pour faciliter l'interopérabilité sémantique. Ils ont mis en avant l'importance des ressources sémantiques pour structurer et harmoniser les données de santé, permettant ainsi une meilleure exploitation des référentiels médicaux par les acteurs du secteur, par exemple au travers du Référentiel unique d'interopérabilité du médicament.
Amel Raboudi a présenté les travaux qu’il mène chez Fealinx pour concevoir une ontologie adaptée au domaine de la psychiatrie.
Ces diverses présentations mettent en lumière l'importance des graphes de connaissances et des ontologies pour structurer et harmoniser les données de santé, permettant ainsi une meilleure exploitation et interopérabilité.
Si ces sujets vous intéressent, explorez les archives avec Le web sémantique au service du bon usage du médicament, SemBot pour le bon usage des médicaments et le Serveur Multi-Terminologie et ne manquez pas la prochaine conférence semweb.pro le 27 novembre 2025 à Paris ! Nous avons présenté les résultats du projet CapData Opéra lors de la conférence Semantic Web In liBraries en novembre dernier (SWIB24). Le support de présentation et l'enregistrement vidéo sont disponible sur la page du programme intitulée CapData Opéra: ease data interoperability for opera houses.
Le projet CapData Opéra a appliqué les principes exposés par notre approche SemGraph
qui tente de généraliser la transformation de données en graphes sémantiques grâce à une méthodologie claire et des outils sous licence logiciel libre. Ces outils modulaires, qui reposent sur les standards du W3C pour l'échange de données RDF, se combinent pour construire une solution adaptée à chaque cas client.
La même approche est en ce moment utilisée pour le projet GraphEthno, mené par la Fédération des écomusées et des musées de société, qui a été présenté lors des rencontres professionnelles 2025. Nous remercions vivement tous les participants de cette dernière édition 2024, qui ont participé aux discussions et présenté leurs travaux !
Cette édition 2024 a subi un léger lifting: nous avons modifié le format de la conférence en réduisant le nombre de présentations au profit de plus de temps pour les échanges pendant une session poster ouverte par des présentations éclairs (moins de 3 min pour présenter son sujet et donner au public l'envie d'en savoir plus).
Comme chaque année depuis 2020, Pierre-Antoine Champin est venu faire le bilan des avancées des différents groupes de travail de l'écosystème Data and Knowlegde du W3C.
Nous espérons que ce nouveau format vous aura plu !
Pour tous ceux qui n'ont pas pu être présent, vous retrouverez les supports des présentations et les vidéos SemWeb.Pro 2024 et sur PeerTube.SemWeb.Pro.
La prochaine édition de la conférence SemWeb.Pro, qui se tiendra en novembre 2025, est déjà en préparation. Si vous souhaitez recevoir les annonces, abonnez-vous à la liste de diffusion en envoyant un mail à contact at semweb.pro ou bien suivez le compte mastodon.logilab.fr/@semwebpro ! Nous avions un stand sur le boulevard de l'IA lors du Forum Teratec 2024.
Nous y avons parlé d'Onyxia, un logiciel libre
qui permet d'offrir, via un navigateur web, des environnements de traitement
et de manipulation de données tels que Jupyter, OpenRefine, etc.
Nous envisageons d'en faire le successeur de notre JupyterApps que nous utilisons
pour diverses applications, dont la formation.
Nous y avons aussi présenté une démo d'utilisation d'un modèle de langue pour
interroger en RQL le site SemWeb.Pro.
Les techniques de RAG se révèlent en effet efficaces pour générer des requêtes RQL à partir d'une base d'exemples bien construite. Mi-juin 2024, nous étions invités au forum entreprendre dans la culture, qui a réuni pendant trois jours divers professionnels engagés dans la valorisation du secteur culturel, en particulier avec des moyens numériques.
L'événement a mis en lumière des problématiques communes, notamment en matière d'indexation de contenu, mais aussi aux différents aspects de l'usage des techniques d'intelligence artificielle. Entre impact environnemental, modification du processus de création et aide à la reconnaissance d'image et de texte, ces outils désormais incontournables changent le paradigme des données dans la culture.
Nous avons participé à l'atelier sur les défis et enjeux de la mutualisation des données, qui a mis en avant des projets de fusion de données hétérogènes auxquels nous collaborons, tels que Cap Data Opéra et FranceArchives.
L'INA a animé un atelier sur l'indexation automatique de leurs contenus vidéo et a abordé entre autres des problématiques d'alignement avec des référentiels externes, tels que Wikidata, que nous connaissons bien pour les traiter nous aussi sur de très gros volumes de données au sein de FranceArchives ou de Data.BnF. Logilab a participé en mai 2024 à l'émission "Libre à vous" sur radio Cause Commune, pour y parler des résultats du projet Role Models, qui étudie les modèles d'organisation ouverts dans les entreprises du logiciel libre.
Pour en savoir plus, vous pouvez écouter le podcast depuis la page de l'émission 209 du 28 mai 2024 ou bien lire la transcription. Nous étions les 2 et 3 mai 2024 à Louvain, en Belgique, pour le second symposium sur Solid, qui a réunit une centaine de personnes d'une vingtaine de nationalités au sein d'une université multi-centenaire pour discuter du futur des applications web.
Solid (SOcial LInked Data) est un projet initié par Tim Berners Lee, l'inventeur du Web. Le projet Solid vise à définir, sous l'égide du W3C, un ensemble de protocoles pour gérer l'authentification, l'authorisation et l'accès au données dans les applications web, en permettant aux trois aspects d'être séparés et donc conjugués à partir de fournisseurs différents pour chacun d'eux.
Grâce aux avancées dans ce domaine, les applications du web social de demain vous permettront du vous authentifier à partir du fournisseur d'identité de votre choix (pensez à ces boutons "login with google", "login with facebook", mais intégrés directement dans votre navigateur et sans se limiter aux GAFAM) et d'utiliser votre propre espace de stockage qui n'exposera que les données auxquelles vous accorderez l'accès (pensez à une sorte de Google Drive ou de NextCloud avec des permissions avancées et des données structurées telles que des personnes ou des événements, partagées par toutes les applications que vous utilisez). Avec Solid, fini les recopies d'un silo à l'autre !
Merci à tous les participants pour des discussions enrichissantes et rendez-vous l'an prochain pour la suite. D'ici là, passez nous voir à SemWeb.Pro en novembre à Paris si vous vous intéressez à Solid.

Nous venons de mettre en ligne un site vitrine dédié à notre offre centrée sur la construction de graphes sémantiques, que nous avons nommée SemGraph.
En s'appuyant sur les standards du Web et une architecture décentralisée, les outils indépendants de la suite SemGraph se complètent pour permettre la mise en réseau de données issues de multiples applications disjointes.
Les graphes de connaissances ainsi constitués apportent une valeur inégalée en faisant apparaître des relations auparavant invisibles et en servant de base à de multiples applications d'intelligence artificielle. Nous avons eu le plaisir les 18 et 19 novembre 2023 de participer au Capitole du Libre, que ce soit en tant qu'orateur que visiteur.
Le Capitole du Libre regroupe chaque année sur le campus de l'ENSEEIHT de Toulouse de nombreux passionnés et entreprises autour de conférences sur les logiciels libres et leur impact sur la société. En tant que développeur et utilisateur de logiciels libres depuis plus de vingt ans, Logilab participe régulièrement à cet événement Toulousain.
Cette année Élodie a réalisé une présentation pour vulgariser le Web de données, l'histoire de ses standards ainsi que son utilité pour l'interopérabilité des données et la décentralisation. La conférence a été filmée et la vidéo est disponible sur la chaîne Youtube de l'événement.
Nous avons aussi assisté à de nombreuses autres conférences tout le weekend ce qui nous a permis de découvrir de nouvelles technologies ou solutions libres.
Nous participerons, bien entendu, à la prochaine session du Capitole du libre. Nous avons déjà hâte de vous y rencontrer ! Cette année encore, Logilab a eu le plaisir de vous convier à la conférence SemWeb.pro 2023.
Nous remercions chaleureusement tous les participants et participantes, ainsi que les présentateurs et présentatrices et les membres du comité de programme de cette édition 2023.
Cette édition était riche de 13 présentations aussi intéressantes et animées les unes que les autres. Certains ont pris le risque de la démo et s'en sont sortis avec succès !
Les sujets abordés permettent de se rendre compte de l'air du temps concernant l'utilisation des
technologies du Web Sémantique dans un cadre professionnel. Les travaux présentés concernaient le milieu de l'agriculture, des statistiques, de l'édition d'ouvrages scolaires ou encore des archives.
Tous ces exemples permettent de se rendre compte de l'impact de ces technologies dans de nombreux domaines. Cette année, une place de choix a été accordée à l'utilisation des grands modèles de langues, qui apportent déjà un vent de nouveauté dans les techniques de traitement des données.
Toutes les vidéos des présentations sont accessibles sur https://peertube.semweb.pro/w/p/af3G6oBrS74CyPb6WDwq4U/ si vous souhaitez voir ou revoir certaines explications et démonstrations.
Nous invitons toutes les personnes présentes à répondre au questionnaire qu'elles ont reçu dans notre dernière lettre d'information.
Vu les riches échanges qui ont eu lieu durant cette édition, nous sommes convaincus que cette journée a son utilité et nous allons lancer l'organisation de la session 2024.
En vous abonnant à notre lettre d'information ou en suivant notre compte https://mastodon.logilab.fr/@semwebpro , vous vous tiendrez au courant du prochain appel à communication et des dates clés de l'événement.
En espérant vous croiser à la prochaine édition fin 2024. 400 mots: ~3min
Après une décennie d'accompagnement de grandes institutions culturelles dans la gestion et la publication de leurs données, Logilab propose un parcours complet de formation pour découvrir et contribuer au Web des données (ou Web sémantique).
Le Web sémantique est l'ensemble des technologies et standards pour rendre des données accessibles sur la toile de manière décentralisée et les lier entre elles. Les données publiées de cette façon se complètent les unes les autres, comme les articles qui se référencent mutuellement sur le Web via des liens hypertexte. A l'instar du Web des documents où tout un chacun peut publier des pages Web et y placer des liens vers les pages déjà existantes, les standards du W3C pour le Web sémantique permettent de publier des données en y insérant des liens vers les autres données déjà existantes.
Une première formation permet de découvrir pas à pas les notions du Web des données, en allant de l'hypertexte du Web des documents jusqu'aux ontologies du Web Sémantique et en passant par le cycle de vie des données et les standards de publication et d'interrogation. L'objectif de la formation est de repartir avec des points de repères clairs sur le sujet.
Une deuxième formation est dispensée afin d'apprendre à contribuer au Web des données dans le respect des standards du W3C. Les principales techniques de description de ressources et de publication sont abordées sous un angle concret avec des exercices de mise en pratique. L'objectif étant d'apprendre à passer d'un ensemble de données CSV à un entrepôt SPARQL contenant des triplets RDF de ces données et de les interroger en SPARQL.
Une troisième formation complète le parcours en abordant la réalisation d'un projet mettant en place les techniques du Web des données. Le but est de fournir des principes servant de boussole pour garder le cap d'un projet de ce type et ne pas passer à côté des caractères différenciant qui font l'intérêt du Web Sémantique.
À l'issue de ces formations, qui ont déjà été suivies par plusieurs dizaines de personnes, les participantes et participants seront à même de proposer à l'institution ou l'entreprise qui les emploie une stratégie adaptée à ses objectifs de valorisation et de diffusion et de les mettre en œuvre en publiant des données sur le Web sémantique. 480 mots - 3 minutes de lecture
Logilab est spécialisée dans le développement d’applications Web pour la publication de données ouvertes et dans la gestion de connaissances. Pour cela, nous maintenons, depuis maintenant près de 20 ans, le cadriciel de développement CubicWeb. Nous utilisons ce cadriciel comme base dans la majorité de nos projets, car il nous permet d’avoir accès à un grand nombre de fonctionnalités bien intégrées entre elles et nous évite une continuelle réinvention de la roue.
Depuis les premières versions de CubicWeb, nous avons voulu permettre la génération de l’interface utilisateur à partir du modèle de données pour que les modifications apportées à ce dernier soient facilement reportées dans les affichages qui n’ont pas besoin d’être faits sur-mesure.
Cette pratique était depuis quelques années dépassée, puisque les interfaces utilisateurs du web sont maintenant très souvent de véritables applications exécutées dans le navigateur plutôt que des pages produites par le serveur.
Afin de suivre cet élan et de permettre aux développeurs et développeuses utilisant CubicWeb de bénéficier des outils devenus standards pour les interfaces utilisateurs dynamiques, nous avons produit cette version majeure de CubicWeb qui extrait dans un composant (le cube web) la partie en charge de la génération des pages à partir du modèle de données. CubicWeb devient ainsi ce que l’on appelle un système de gestion de données “sans tête”.
Chacun peut donc développer une ou plusieurs interfaces graphiques en utilisant la technologie qui lui convient (React, Angular, Vue.JS, etc.) et profiter des dernières évolutions techniques côté client, tout en conservant les avantages de CubicWeb côté serveur.
Pour exposer les fonctionnalités du serveur, un cube API a été développé. Ce cube offre une API HTTP publique, qui respecte OpenAPI et permet d’accéder à toutes les fonctionnalités de CubicWeb. La route principale est l’accès à l’interrogation en RQL.
Afin de faciliter encore plus le développement de la partie cliente, nous développons des bibliothèques JavaScript qui implémentent la partie générique des interactions avec un serveur CubicWeb. La bibliothèque @cubicweb/client permet d’établir une connexion avec une instance CubicWeb et @cubicweb/react-form-utils facilite l’écriture de formulaire s’appuyant sur React Hook Form et rendent accessible côté client le modèle de données du serveur et ses types. D’autres outils arriveront dans les prochains mois. Par exemple CubicWeb React Admin peut être utilisé pour avoir une interface d’administration générique sur toute instance de CubicWeb, un peu comme ce que fournissait le cube web en CubicWeb 3.
L’objectif de CubicWeb étant de favoriser la publication de données ouvertes, nous avons profité de la version 4 pour rapprocher encore plus ce cadriciel des technologies du Web Sémantique qui l’ont inspiré, en utilisant notamment la notion de négociation de contenu pour publier du RDF. L’URL d’une entité donne accès soit à une page HTML de base qui affiche les données avec très peu de mise en page, soit aux données en RDF dans l’un des différents formats de sérialisation disponibles.
La liste complète des changements apportés à cette version se trouve dans la documentation. Bon développement ! Un nouvel événement dédié au Web Semantique dans la ville rose s'organise !
Nous avons le plaisir de vous annoncer le programme de la journée d'atelier SemWeb.Pro que nous organisons le 13 Juin prochain à Toulouse.
Cette journée aura lieu le 13 Juin à Toulouse, dans l'espace de coworking et de réunion O'Local, dans une belle bâtisse typiquement toulousaine, avec comme objectif de favoriser au maximum les interactions.
Pensez à vous inscrire !
Le programme de cette journée s'articule en deux temps, le matin une session de présentations et l'après-midi dédié aux échanges autour des thématiques et des questions ayant animé le débat le matin même. Une restitution rapide des ateliers clôturera la journée.
Au programme :
| Créneau |
Titre de la présentation |
Intervenant |
| 10h00-10h30 |
Création automatique d'ontologies à partir de documents techniques |
M. Lalanne (Airbus) |
| 10h30-11h00 |
Intérêt des Systèmes d'Informations pilotés par des ontologies. Illustration avec OpenSilex |
P. Neuveu (INRAE - MISTEA) |
| 11h30-12h00 |
Génération d'un contexte JSON-LD à partir d'un méta-modèle : exemple avec Asset Administration Shell |
É. Thiéblin (Logilab) |
| 11h30-12h00 |
En cours de définition ... |
|
Tous les détails relatifs à l'inscription sont sur le site SemWeb.pro Attention, le nombre de places est limité.
Nous espérons que cet événement tiendra ses promesses en rassemblant et vous permettra d'entretenir votre réseau tout en découvrant un large spectre des possibilités du web sémantique. 500 mots - 3 minutes
La PyConFR est le rendez-vous immanquable de la communauté Python en France. Hébergé cette année par l'Université de Bordeaux, cet évènement a rassemblé des développeurs, novices et expérimentés, pendant quatre jours autour de sprints, conférence et ateliers. Après presque trois ans d'attente, nous étions contents de pouvoir enfin retrouver la communauté Python.
Sprint ReservoirPy
Les jeudi et vendredi 15 et 16 étaient consacrés aux sprints, ces ateliers qui rassemblent plusieurs personnes pour faire avancer des projets choisis au préalable.
Nous avons pu contribuer à reservoirpy, une bibliothèque de Reservoir Computing développée à l'INRIA. Nous avons travaillé sur la publication automatique via l'intégration continue (GitHub Actions en l'occurrence) de nouvelles versions de la bibliothèque sur Pypi et sur un entrepôt Anaconda.
Pour en savoir plus sur le Reservoir Computing, vous pouvez regarder cette vidéo d'introduction captée à Dataquitaine en février 2022).
Conférences
Le programme des conférences était très riche et nous avons apprécié la diversité des thématiques (généralistes, web, science des données, devops, ...). Nous n'avons pas pu aller voir toutes les conférences, mais voici un échantillon de celles qui ont particulièrement retenu notre attention.
NucliaDB, une base de données pour le machine learning et les données non-structurées
Éric Bréhault (Nuclia) a présenté NucliaDB qui est une base de données vectorielle, c'est-à-dire qu'elle permet d'associer des données à des vecteurs situés dans un espace ayant de nombreuses dimensions. Adaptée à un usage en machine learning, cette base de données propose une API permettant d'indexer des données non structurées, de faire des recherches sémantiques, etc.
À la découverte de Polars (ou pourquoi vous pourriez quitter pandas)
Cette présentation de Olivier Hervieu nous a fait découvrir une alternative à Pandas pour le traitement de données tabulaires, nommée Polars. Cette bibliothèque est utilisable en Rust et en Python. Nous avons retenu sa capacité à charger des données de manière paresseuse à partir de fichiers.
Python moderne et fonctionnel pour des logiciels robustes
La présentation de Guillaume Desforges (Tweag) a mis en avant les avantages de la programmation fonctionnelle et son applicabilité au langage Python. Elle s'est terminée par une présentation de l'architecture en oignon appliquée à une application Flask.
Psycopg, troisième du nom
Durant cette conférence, Denis Laxalde (Dalibo) a présenté l'historique de la bibliothèque Psycopg. Nous avons également pu découvrir le protocole de communication utilisé pour parler avec un cluster PostgreSQL. Enfin, nous avons observé comment Psycopg s'appuie sur la bibliothèque libpq pour proposer une API haut niveau aux développeurs Python. La version 3 de Psycopg apporte de nombreuses améliorations dont le support de async/await, le support du mode pipeline ou encore le typage statique. Nous sommes fiers à Logilab d'avoir contribué à son financement.
Conclusion
Les PyConFR sont toujours un grand moment partagé avec la communauté Python. Que ce soit pendant les sprints ou entre les conférences, nous avons eu l'opportunité de rencontrer des développeurs de tous horizons et d'échanger avec eux sur des problématiques communes. Rendez-vous dans un an pour la prochaine édition et le 16 mars dans nos locaux parisiens pour un Afpyro. Les AFPYRo reprennent et le prochain aura lieu dans nos locaux parisiens entre Denfert Rochereau et la Place d'Italie !
Un AFPYRo est un événement organisé par l’AFPy − Association Francophone Python − pour regrouper des personnes souhaitant discuter du langage de programmation Python dans un cadre convivial. Après une ou deux présentations (vous pouvez proposer la vôtre), nous échangerons autour de quelques pizzas.
Le prochain AFPYRo sera donc à Logilab, au 104 Boulevard Auguste Blanqui 75013 Paris, le 16 mars 2023 de 19h à 21h et nous offrirons les pizzas.
N’hésitez pas à vous inscrire et à passer nous voir ! Fort de ses références au sein des établissements publics et de l'administration française, notamment à la Bibliothèque nationale de France avec data.bnf.fr, aux Archives de France avec France Archives et dans plusieurs équipes de recherche en humanités numériques, le logiciel libre CubicWeb a été ajouté au catalogue GouvTech des outils numériques utilisés par les services publics.
La prochaine édition de SemWeb.Pro aura lieu en ligne le jeudi 9 décembre.

Nous vous invitons à soumettre vos propositions de présentation en répondant à l'appel à communication avant le 5 novembre 2021. CubicWeb est un cadriciel libre de gestion de
données sur le Web développé et maintenu par Logilab
depuis 15 ans. Il est utilisé depuis 2010 dans des applications d'envergure
telles que DataBnF ou
FranceArchives. Basé sur les principes du web
sémantique depuis sa création, il adopte à son rythme les standards du W3C pour
faciliter la publication de données sur le Web de données liées
(LOD).
CubicWeb vient de franchir une nouvelle étape avec la version 3.28 sortie le 24
juin 2020, qui met à disposition la négociation de contenu HTML / RDF.
Cette fonctionnalité a fait l'objet d'un article
scientifique
et d'une démonstration lors de la conférence d'Ingénierie de Connaissance de la Plateforme Française d'Intelligence Artificielle.
Nous allons maintenant présenter CubicWeb, les principes de la négociation de
contenu en général, les choix faits pour la mettre en oeuvre dans CubicWeb et
comment personnaliser le RDF généré.
Présentation de CubicWeb
CubicWeb fonctionne par composants, appelés
cubes, qui peuvent être combinés pour créer
une application (qui est elle-même un cube réutilisable).
Un cube est composé:
-
1- d'un schéma (ou modèle données) exprimé en
YAMS,
un langage qui permet d'exprimer un modèle entité-association et les
permissions associées en python ;
-
2- d'une logique applicative ;
-
3- de vues (interfaces graphiques ou fonctions d'export de données).
Lorsqu'une application est "instanciée", le schéma YAMS est compilé en un schéma
SQL et une base de données Postgresql est initialisée pour stocker le modèle et
les données de l'application.
La logique de l'application, écrite en Python, interagit
avec la base de données par le biais du schéma YAMS et du langage de requête
RQL. Il
n'y a donc pas besoin d'écrire des requêtes SQL et de se préoccuper du schéma
physique de la base relationnelle sous-jacente.
L'introduction d'une séparation nette entre l'obtention des données via une
requête RQL et leur mise en forme par une vue permet d'offrir à l'utilisateur
une grande liberté dans son exploration de la base.
S'il n'y a pas de vue personnalisée prévue pour une entité du modèle YAMS, une
vue est générée automatiquement, ce qui assure que toutes les données sont
visibles et manipulables, ne serait-ce qu'au travers d'une interface minimale
qui permet aux utilisateurs autorisés d'ajouter, éditer et supprimer les entités
de l'application.
Dans cette architecture, offrir une représentation RDF d'une ressource/entité
consiste à définir une vue spécifique, qui traduira dans le vocabulaire RDF
choisi les entités définies par le modèle YAMS.
Présentation de la négociation de contenu
La négociation de contenu permet d'obtenir plusieurs représentations d'une même ressource à partir d'une même URL.
Une personne visitant la ressource http://cubicweb.example.com/person/123 avec
son navigateur souhaite généralement obtenir la version HTML pour la lire.
Dans le Web de données, un robot ou un programme sera plus intéressé par la
représentation RDF de cette ressource pour en traiter les données.
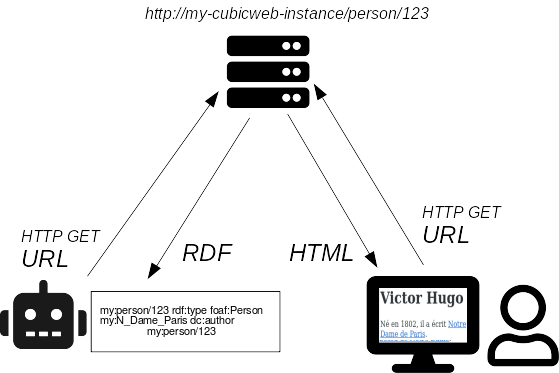
La même ressource abstraite est donc mise à disposition par le serveur sous deux représentations distinctes : le RDF et le HTML.
Le mécanisme de négociation de contenu permet de servir ces représentations
depuis la même URL, qui pourra ainsi être partagée entre ces deux mondes : humain
et robot.
Implémentation de la négociation de contenu
La négociation de contenu passe par les différents en-têtes Accept* d'une
requête HTTP. Elle peut concerner la langue avec Accept-Language, le jeu de
caractères avec Accept-Charset, l'encodage avec Accept-Encoding ou encore le
format avec Accept.
C'est l'en-tête Accept qui est utilisée par le client pour spécifier qu'il
souhaite la représentation RDF d'une ressource dans un format donné, en
utilisant l'un des types
MIME
suivants :
-
· application/rdf+xml
-
· text/turtle
-
· text/n3
-
· application/n-quads
-
· application/n-triples
-
· application/trig
-
· application/ld+json
Lorsqu'une requête est envoyée au serveur avec l'en-tête Accept et un type MIME de la liste ci-dessus, le serveur peut répondre de plusieurs façons.
Il peut indiquer au client, via une redirection intermédiaire (303 See Other), l'URL où se trouve la ressource dans la bonne représentation. C'est le choix fait par Virtuoso.

Il peut également répondre en envoyant directement la description RDF dans le format correspondant au type MIME de la requête.

C'est le choix que nous avons fait dans CubicWeb, pour éviter une seconde
requête et gagner en efficacité.
Description RDF des entités CubicWeb
Dans la version 3.28, CubicWeb fournit une représentation en RDF par défaut de
ses entités, qui contient deux «types» de triplets :
-
· ceux qui décrivent les relations et attributs du schéma YAMS. Ils utilisent le préfixe http://ns.cubicweb.org/cubicweb/0.0/, abrégé en cubicweb.
-
· ceux qui décrivent des relations Dublin Core.
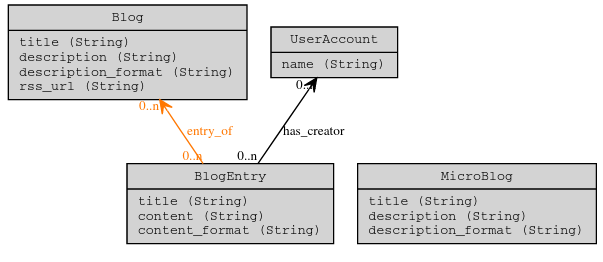
Par exemple, si vous avez une instance qui héberge des articles de blog
(CustomBlogEntry), vous pourrez exécuter :
curl -iH "Accept: text/turtle" http://cubicweb.example.com/customblogentry/2872
qui retournera :
@prefix cubicweb: <http://ns.cubicweb.org/cubicweb/0.0/> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
@prefix dc: <http://purl.org/dc/elements/1.1/> .
# triplets Cubicweb (générés par cw_triples())
<http://cubicweb.example.com/902> cubicweb:wf_info_for <http://cubicweb.example.com/901> .
<http://cubicweb.example.com/901> a cubicweb:CustomBlogEntry ;
cubicweb:content "Ceci est le contenu de mon billet de blog" ;
cubicweb:content_format "text/plain" ;
cubicweb:creation_date "2020-07-09T07:59:09.339052+00:00"^^xsd:dateTime ;
cubicweb:entry_of <http://cubicweb.example.com/900> ;
cubicweb:modification_date "2020-07-09T07:59:29.300045+00:00"^^xsd:dateTime ;
cubicweb:title "Mon billet de blog" .
# triplets Dublin Core (généré par dc_triples())
dc:language "en" ;
dc:title "Mon billet de blog" ;
dc:type "Blog entry" .
Personnaliser le RDF généré
Pour personnaliser la représentation RDF d'un type d'entité, il faut créer une
classe héritant de EntityRDFAdapter, puis redéfinir sa méthode triples qui
doit, comme son nom l'indique, renvoyer un ensemble de triplets. Les triplets
sont formés avec rdflib.
Par défaut, la méthode triples appelle les méthodes cw_triples et
dc_triples de EntityRDFAdapter pour récupérer respectivement les triplets
CubicWeb et les triplets Dublin Core. Ces méthodes peuvent être surchargées si
nécessaire.
Le code ci-dessous montre un exemple d'adaptateur RDF pour la classe BlogEntry.
La fonction _use_namespace permet de relier un préfixe à son namespace dans
le graphe RDF généré, en l'ajoutant au dictionnaire NAMESPACES du module cubicweb.rdf.
from rdflib import URIRef, Namespace
from cubicweb.entities.adapters import EntityRDFAdapter
from cubicweb.rdf import NAMESPACES
NAMESPACES["sioct"] = Namespace("http://rdfs.org/sioc/types#")
class BlogEntryRDFAdapter(EntityRDFAdapter):
__select__ = is_instance("BlogEntry")
def triples(self):
SIOCT = self._use_namespace("sioct")
RDF = self._use_namespace("rdf")
yield (URIRef(self.uri), RDF.type, SIOCT.BlogPost)
Exemple de triplets personnalisés
Dans la version 1.14.0 du cube blog sortie le 24 juin 2020, l'ontologie SIOC (Semantically-Interlinked Online Communities) a été utilisée pour décrire les entités relatives aux blogs.
Voici le résultat obtenu pour un billet de blog :
curl -iH "Accept: text/turtle" https://www.logilab.fr/blogentry/2872
qui renverra:
@prefix dcterms: <http://purl.org/dc/terms/> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix sioc: <http://rdfs.org/sioc/ns#> .
@prefix sioct: <http://rdfs.org/sioc/types#> .
@prefix xml: <http://www.w3.org/XML/1998/namespace> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
<http://www.logilab.fr/2872> a sioct:BlogPost ;
dcterms:date "2019-06-28T15:28:31.852530+00:00"^^xsd:dateTime ;
dcterms:format "text/markdown" ;
dcterms:modified "2020-06-19T13:26:20.750747+00:00"^^xsd:dateTime ;
dcterms:title "SemWeb.Pro 2019 : envoyez votre proposition avant samedi 31 août !" ;
sioc:container <http://beta.logilab.fr1377> ;
sioc:content """La prochaine édition de SemWeb.Pro aura lieu mardi 3 décembre à Paris.\r
\r
\r
\r
Nous vous invitons à soumettre vos propositions de présentation en [répondant à l'appel à communication](<http://www.semweb.pro/semwebpro-2019.html>) **avant le 31 août 2019**.\r
\r
Pour être tenu informé de l'ouverture de la billetterie, envoyez un courriel à contact at semweb.pro en demandant à être inscrit à la liste d'information.""" .
Les prochaines étapes pour CubicWeb
Permettre la négociation de contenu est une étape de nos travaux actuels pour faire de CubicWeb une brique à part entière du LOD.
Nous travaillons déjà à la génération d'archive RDF pour faciliter l'export, mais également à la possibilité d'interroger la base en SPARQL, en plus du RQL.
La prochaine édition de SemWeb.Pro aura lieu mardi 3 décembre au FIAP
Jean Monnet, à Paris.
Nous vous invitons à soumettre vos propositions de présentation en répondant à l'appel à communication avant le 31 août 2019.
Pour être tenu informé de l'ouverture de la billetterie, envoyez un courriel à contact@semweb.pro en demandant à être inscrit à la liste d'information. Nous avons eu le plaisir de soutenir l'organisation du pgDay Lyon 2019 aux côté des spécialistes de Postgresql et d'autres sociétés qui en font un usage intensif.
Le programme montre que Postgresql est une base de données très flexible, qui allie performances et très grandes quantités de données ! Co-organisée par Logilab, Octobus & RhodeCode la conférence Mercurial aura lieu mardi 28 mai au siège de Mozilla, à Paris.
Mercurial est un système de gestion de contrôle de code source distribué gratuitement qui offre une interface intuitive pour gérer efficacement des projets de toutes tailles. Avec son système d'extension puissant, Mercurial peut facilement s'adapter à n'importe quel environnement.

Cette première édition s'adresse aux entreprises qui utilisent déjà Mercurial ou qui envisagent de passer d'un autre système de contrôle de version, tel que Subversion.
Assister à la conférence Mercurial permettra aux utilisateurs de partager des idées et des expériences dans différents secteurs. C'est aussi l'occasion de communiquer avec les principaux développeurs de Mercurial et d'obtenir des mises à jour sur le flux de travail et ses fonctionnalités modernes.
Inscrivez-vous !
Mozilla : 16 bis boulevard Montmartre 75009 - Paris Logilab co-organise avec la société Octobus, un mini-sprint Mercurial qui aura lieu du jeudi 4 au dimanche 7 avril à Paris.
Logilab accueillera le mini-sprint dans ses locaux parisiens les jeudi 4 et vendredi 5 avril. Octobus s'occupe des samedi et dimanche et communiquera très prochainement le lieu retenu pour ces jours-là.
Afin de participer au sprint, remplissez le sondage et indiquez votre nom et les dates auxquelles vous souhaitez participer.
Vous pouvez aussi remplir le pad pour indiquer les thématiques que vous souhaitez aborder au cours de ce sprint : https://mensuel.framapad.org/p/mini-sprint-hg
Let's code together! Nous avons le plaisir de soutenir l'organisation du pgDay Paris 2019 aux côté des spécialistes de Postgresql et d'autres sociétés qui en font un usage intensif.
Consulter le programme, il est montre que Postgresql est une base de données très flexible, qui allie performances et très grandes quantités de données ! 
Retrouvez-nous au stand C6-D5 du salon
5 & 6 décembre au Dock Pullman, plaine Saint-Denis
Nous vous accueillerons avec plaisir au salon Paris Open Source Summit pour parler logiciel libre, données ouvertes et Web sémantique.
Et ne ratez pas la présentation de Arthur Lutz : Retour d'expérience sur la mise en place de déploiement continu qui aura lieu dans la matinée du mercredi 5 décembre, track Devops.
Demandez votre badge d'accès gratuit ! Depuis son lancement, Logilab soutien PyParis : deux jours de conférence qui réuni des utilisateurs et des développeurs du langage de programmation Python.

À cette occasion, Arthur Lutz présentera "Python tooling for continuous deployment". Il expliquera comment au sein de Logilab nous avons migré les processus de génération et de déploiement vers un modèle de distribution continue, les conséquences d'un tel changement en termes de technologie, au sein des équipes et de gestion de projet avec les clients. Cette présentation portera sur les outils Python qui ont permis de réaliser un tel changement, mais également sur les changements humains qu’il nécessite.
Consultez le programme et inscrivez-vous ! Pionnier du langage Python en France, Logilab est mécène de PyConFr, conférence annuelle des pythonistes francophones qui aura lieu du jeudi 4 au dimanche 7 octobre, à Lille.

Un codage participatif aura lieu les jeudi 4 et vendredi 5 octobre. Des développeuses et des développeurs de différents projets open source se rassembleront pour coder ensemble. C'est l'occasion de participer au développement de son projet préféré !
Durant le week-end, auront lieu des présentations sur des sujets variés, autour du langage Python, de ses usages, des bonnes pratiques, des retours d'expériences, des partages d'idées.
Cette année, deux ingénieurs de notre équipe sont au programme :
- Arthur Lutz présentera Déployer des applications python dans un cluster openshift et aussi Faire de la domotique libriste avec Python
Et
- Julien Tayon présentera La cartographie c'est simple et "complexe"
La billetterie en ligne est fermée ! Pour plus d'informations, rapprochez-vous de l'association organisatrice. 
Mardi 6 novembre au FIAP Jean Monnet, à Paris
Consultez le programme et inscrivez-vous dès à présent afin de bénéficier du tarif à 70€ (passage à 120€ après le 15 octobre).
Vous pouvez assister à cette journée dans le cadre d'une formation professionnelle (donnant lieu à l'établissement d'une convention de formation). Dans ce cas, le tarif applicable est de 250€.
Suivez nos actualités sur Twitter @semwebpro mais aussi avec le hashtag #semwebpro
Pour plus d'informations, contactez-nous : contact@semweb.pro Du 4 au 6 juin ont lieu les journées d'études Documenter la production artistique : données, outils, usages autour des plateformes ReSource et Artefactory qui se déroulent à la Villa Arson, à Nice.
À cette occasion, Adrien di Mascio présentera Désilotation et publication de données culturelles : un retour d’expérience.
Cette présentation expliquera de manière simple les notions d’échelle de qualité des données, d’ontologies, de référentiels, d’identifiants pérennes et d’alignements. Adrien montrera quelques retours d’expériences concrets de projets réalisés par Logilab comme data.bnf.fr, francearchives.fr ou Biblissima pour illustrer les différents concepts et processus mis en jeu pour publier des données patrimoniales.
Rendez-vous demain, mercredi 6 juin à partir de 10h45 à l'amphi 3 de la Villa Arson. Organisée par Logilab, avec le soutien de l'INRIA, SemWeb.Pro est une journée de conférences dédiée au Web Sémantique, qui réunit chaque année de 100 à 150 personnes depuis la première édition en 2011.
Participer à SemWeb.Pro c'est l'occasion d'échanger avec les membres de la communauté du Web Sémantique, ainsi qu'avec des sociétés innovantes et des industriels qui mettent en œuvre les nouvelles techniques du Web des données.
Nous vous invitons à soumettre dès à présent vos propositions de présentation afin de partager votre savoir-faire et votre expérience. Chaque présentation durera 20 minutes (hors Questions-réponses). La langue principale est le français, mais les présentations en anglais sont acceptées.
Procédure de soumission
Pour soumettre au comité de programme votre proposition de présentation, veuillez envoyer un courrier électronique à contact@semweb.pro avant le vendredi 15 juin 2018 en précisant les informations suivantes :
- titre,
- description en moins de 400 mots,
- auteur présenté en quelques phrases
- liens éventuels vers des démos, vidéos, applications, etc.
Critères de sélection
- l'utilisation effective des standards du Web Sémantique est indispensable,
- nous privilégierons les présentations de projets qui sont déjà en production ou qui concernent de nouveaux domaines d'application les démonstrations et vidéos seront appréciées.

Call for proposal
Organized by Logilab, with the support of INRIA, SemWeb.Pro is a one-day conference focused on the Semantic Web, which has been gathering between 100 to 150 persons each year since its first edition in 2011.
Attending SemWeb.Pro is a unique occasion to discuss with members of the Semantic Web community and with innovative companies and industrials implementors of the Web of Linked Data.
We invite you to send your proposal to share your experience and know-how. Each talk will last 20 minutes (excluding questions). The main language is French, but English talks are welcome.
Submission procedure
To submit your talk proposal to the program committee, please send an email to contact@semweb.pro before Friday June 15th, 2018 including the following information :
- title,
- description in less than 400 words,
- bio of the author in a few sentences,
- links to demos, videos, web applications, etc.
Selection criteria
- actual use of some of the Semantic Web standards is mandatory, we favor projects that are already at the production stage or that open new application domains
- demonstrations and videos are valued.
FOSDEM est une conférence qui réunit chaque année des milliers de développeurs de logiciels libres et open source du monde entier à Bruxelles.
Cette année ce rendez-vous incontournable aura lieu samedi 3 et dimanche 4 février à l'Université Libre de Bruxelles (ULB Solbosch Campus).

Logilab participera ensuite au Config Management Camp qui aura lieu du lundi 5 au mercredi 7 février à Gent.

Nous vous donnons rendez-vous mardi 6 février dans la Community Room Salt B.3.036.
Consultez le programme et rencontrons-nous sur place !
Suivez nos actualités sur ce blog ou sur Twitter :
Demain, mardi 16 janvier, Arthur Lutz vous invite au meetup Nantes monitoring où netdata et sensu sont à l'ordre du jour :
• netdata pour la collecte et la visualisation de la métrologie

• sensu pour la supervision

Ce meet-up aura lieu de 19:00 à 22:00 au VA Solutions situé au 3 rue du Tisserand · Saint-Herblain (5 minutes à pied de l'arrêt de tram François Mitterrand sur la ligne 1).
INSCRIVEZ-VOUS ! 
Pour la 5ème édition de ce rendez-vous, les Rencontres Régionales du Logiciel Libre s'installent cette année à l'Hippodrome de Toulouse, et pour la toute première fois à Montpellier.
Ces rencontres s'adressent aussi bien aux services informatiques qu'aux directions métiers qui trouveront des réponses à leurs problématiques techniques et besoins fonctionnels.
Les RRLL sont ainsi l'occasion de diverses rencontres telles que des administrations, collectivités, industries et entreprises ayant déployé des solutions libres, ainsi que les prestataires locaux. Les Rencontres Régionales du Logiciel Libre sont une série d'évènements dans toute la France organisés sous l'égide du Conseil National du Logiciel Libre (CNLL).
Les RRLL de Toulouse sont inscrites dans le cadre de la manifestation Capitole du Libre organisée tous les ans par l' Association Toulibre.
À cette occasion, Logilab présentera "Tirer parti du Web des données pour améliorer l'efficacité des administrations et des entreprises".
Consultez les programmes :

Pour cette sixième édition de SemWeb.Pro, des posters seront exposés dans le hall de la conférence. Rendez-vous mercredi 22 novembre au FIAP Jean Monnet, à Paris.
Participer à SemWeb.Pro c'est l'occasion d'échanger avec les membres de la communauté du Web Sémantique ainsi qu'avec des utilisateurs, issus de l'industrie ou de la culture, qui mettent en œuvre les nouvelles techniques du Web des données.
Consultez le programme et inscrivez-vous
Twitter @semwebpro #semwebpro
Pour plus d'informations, contactez-nous : contact@semweb.pro
|
 [
[ 
