
| [CubicWeb](https://cubicweb.readthedocs.io) est un cadriciel libre de gestion de données sur le Web développé et maintenu par [Logilab](https://logilab.fr) depuis 15 ans. Il est utilisé depuis 2010 dans des applications d'envergure telles que [DataBnF](https://data.bnf.fr) ou [FranceAr... | |
| 1170 |
CubicWeb est un cadriciel libre de gestion de données sur le Web développé et maintenu par Logilab depuis 15 ans. Il est utilisé depuis 2010 dans des applications d'envergure telles que DataBnF ou FranceArchives. Basé sur les principes du web sémantique depuis sa création, il adopte à son rythme les standards du W3C pour faciliter la publication de données sur le Web de données liées (LOD).
CubicWeb vient de franchir une nouvelle étape avec la version 3.28 sortie le 24 juin 2020, qui met à disposition la négociation de contenu HTML / RDF.
Cette fonctionnalité a fait l'objet d'un article scientifique et d'une démonstration lors de la conférence d'Ingénierie de Connaissance de la Plateforme Française d'Intelligence Artificielle.
Nous allons maintenant présenter CubicWeb, les principes de la négociation de contenu en général, les choix faits pour la mettre en oeuvre dans CubicWeb et comment personnaliser le RDF généré.
Présentation de CubicWeb
CubicWeb fonctionne par composants, appelés cubes, qui peuvent être combinés pour créer une application (qui est elle-même un cube réutilisable). Un cube est composé:
-
1- d'un schéma (ou modèle données) exprimé en YAMS, un langage qui permet d'exprimer un modèle entité-association et les permissions associées en python ;
-
2- d'une logique applicative ;
-
3- de vues (interfaces graphiques ou fonctions d'export de données).
Lorsqu'une application est "instanciée", le schéma YAMS est compilé en un schéma SQL et une base de données Postgresql est initialisée pour stocker le modèle et les données de l'application.
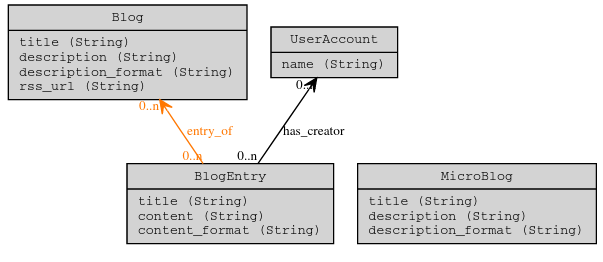
La logique de l'application, écrite en Python, interagit avec la base de données par le biais du schéma YAMS et du langage de requête RQL. Il n'y a donc pas besoin d'écrire des requêtes SQL et de se préoccuper du schéma physique de la base relationnelle sous-jacente.
L'introduction d'une séparation nette entre l'obtention des données via une requête RQL et leur mise en forme par une vue permet d'offrir à l'utilisateur une grande liberté dans son exploration de la base.
S'il n'y a pas de vue personnalisée prévue pour une entité du modèle YAMS, une vue est générée automatiquement, ce qui assure que toutes les données sont visibles et manipulables, ne serait-ce qu'au travers d'une interface minimale qui permet aux utilisateurs autorisés d'ajouter, éditer et supprimer les entités de l'application.
Dans cette architecture, offrir une représentation RDF d'une ressource/entité consiste à définir une vue spécifique, qui traduira dans le vocabulaire RDF choisi les entités définies par le modèle YAMS.
Présentation de la négociation de contenu
La négociation de contenu permet d'obtenir plusieurs représentations d'une même ressource à partir d'une même URL1.
Une personne visitant la ressource http://cubicweb.example.com/person/123 avec
son navigateur souhaite généralement obtenir la version HTML pour la lire.
Dans le Web de données, un robot ou un programme sera plus intéressé par la
représentation RDF de cette ressource pour en traiter les données.
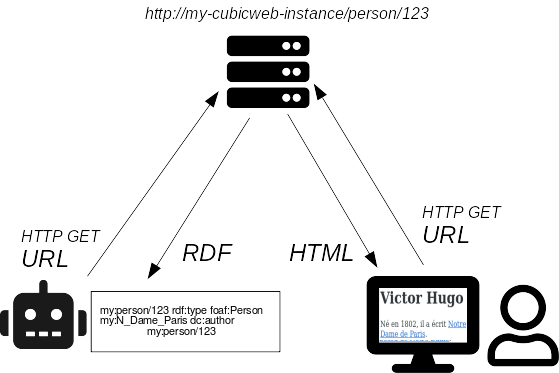
La même ressource abstraite est donc mise à disposition par le serveur sous deux représentations distinctes : le RDF et le HTML. Le mécanisme de négociation de contenu permet de servir ces représentations depuis la même URL, qui pourra ainsi être partagée entre ces deux mondes : humain et robot.
Implémentation de la négociation de contenu
La négociation de contenu passe par les différents en-têtes Accept* d'une
requête HTTP. Elle peut concerner la langue avec Accept-Language, le jeu de
caractères avec Accept-Charset, l'encodage avec Accept-Encoding ou encore le
format avec Accept.
C'est l'en-tête Accept qui est utilisée par le client pour spécifier qu'il
souhaite la représentation RDF d'une ressource dans un format donné, en
utilisant l'un des types
MIME
suivants :
-
· application/rdf+xml
-
· text/turtle
-
· text/n3
-
· application/n-quads
-
· application/n-triples
-
· application/trig
-
· application/ld+json
Lorsqu'une requête est envoyée au serveur avec l'en-tête Accept et un type MIME de la liste ci-dessus, le serveur peut répondre de plusieurs façons.
Il peut indiquer au client, via une redirection intermédiaire (303 See Other), l'URL où se trouve la ressource dans la bonne représentation. C'est le choix fait par Virtuoso.

Il peut également répondre en envoyant directement la description RDF dans le format correspondant au type MIME de la requête.

C'est le choix que nous avons fait dans CubicWeb, pour éviter une seconde requête et gagner en efficacité.
Description RDF des entités CubicWeb
Dans la version 3.28, CubicWeb fournit une représentation en RDF par défaut de ses entités, qui contient deux «types» de triplets :
-
· ceux qui décrivent les relations et attributs du schéma YAMS. Ils utilisent le préfixe
http://ns.cubicweb.org/cubicweb/0.0/, abrégé encubicweb. -
· ceux qui décrivent des relations Dublin Core.
Par exemple, si vous avez une instance qui héberge des articles de blog
(CustomBlogEntry), vous pourrez exécuter :
curl -iH "Accept: text/turtle" http://cubicweb.example.com/customblogentry/2872
qui retournera :
@prefix cubicweb: <http://ns.cubicweb.org/cubicweb/0.0/> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
@prefix dc: <http://purl.org/dc/elements/1.1/> .
# triplets Cubicweb (générés par cw_triples())
<http://cubicweb.example.com/902> cubicweb:wf_info_for <http://cubicweb.example.com/901> .
<http://cubicweb.example.com/901> a cubicweb:CustomBlogEntry ;
cubicweb:content "Ceci est le contenu de mon billet de blog" ;
cubicweb:content_format "text/plain" ;
cubicweb:creation_date "2020-07-09T07:59:09.339052+00:00"^^xsd:dateTime ;
cubicweb:entry_of <http://cubicweb.example.com/900> ;
cubicweb:modification_date "2020-07-09T07:59:29.300045+00:00"^^xsd:dateTime ;
cubicweb:title "Mon billet de blog" .
# triplets Dublin Core (généré par dc_triples())
dc:language "en" ;
dc:title "Mon billet de blog" ;
dc:type "Blog entry" .
Personnaliser le RDF généré
Pour personnaliser la représentation RDF d'un type d'entité, il faut créer une
classe héritant de EntityRDFAdapter, puis redéfinir sa méthode triples qui
doit, comme son nom l'indique, renvoyer un ensemble de triplets. Les triplets
sont formés avec rdflib.
Par défaut, la méthode triples appelle les méthodes cw_triples et
dc_triples de EntityRDFAdapter pour récupérer respectivement les triplets
CubicWeb et les triplets Dublin Core. Ces méthodes peuvent être surchargées si
nécessaire.
Le code ci-dessous montre un exemple d'adaptateur RDF pour la classe BlogEntry.
La fonction _use_namespace permet de relier un préfixe à son namespace dans
le graphe RDF généré, en l'ajoutant au dictionnaire NAMESPACES du module cubicweb.rdf.
from rdflib import URIRef, Namespace
from cubicweb.entities.adapters import EntityRDFAdapter
from cubicweb.rdf import NAMESPACES
NAMESPACES["sioct"] = Namespace("http://rdfs.org/sioc/types#")
class BlogEntryRDFAdapter(EntityRDFAdapter):
__select__ = is_instance("BlogEntry")
def triples(self):
SIOCT = self._use_namespace("sioct")
RDF = self._use_namespace("rdf")
yield (URIRef(self.uri), RDF.type, SIOCT.BlogPost)
Exemple de triplets personnalisés
Dans la version 1.14.0 du cube blog sortie le 24 juin 2020, l'ontologie SIOC (Semantically-Interlinked Online Communities) a été utilisée pour décrire les entités relatives aux blogs.
Voici le résultat obtenu pour un billet de blog :
curl -iH "Accept: text/turtle" https://www.logilab.fr/blogentry/2872
qui renverra:
@prefix dcterms: <http://purl.org/dc/terms/> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix sioc: <http://rdfs.org/sioc/ns#> .
@prefix sioct: <http://rdfs.org/sioc/types#> .
@prefix xml: <http://www.w3.org/XML/1998/namespace> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
<http://www.logilab.fr/2872> a sioct:BlogPost ;
dcterms:date "2019-06-28T15:28:31.852530+00:00"^^xsd:dateTime ;
dcterms:format "text/markdown" ;
dcterms:modified "2020-06-19T13:26:20.750747+00:00"^^xsd:dateTime ;
dcterms:title "SemWeb.Pro 2019 : envoyez votre proposition avant samedi 31 août !" ;
sioc:container <http://beta.logilab.fr1377> ;
sioc:content """La prochaine édition de SemWeb.Pro aura lieu mardi 3 décembre à Paris.\r
\r
\r
\r
Nous vous invitons à soumettre vos propositions de présentation en [répondant à l'appel à communication](<http://www.semweb.pro/semwebpro-2019.html>) **avant le 31 août 2019**.\r
\r
Pour être tenu informé de l'ouverture de la billetterie, envoyez un courriel à contact at semweb.pro en demandant à être inscrit à la liste d'information.""" .
Les prochaines étapes pour CubicWeb
Permettre la négociation de contenu est une étape de nos travaux actuels pour faire de CubicWeb une brique à part entière du LOD. Nous travaillons déjà à la génération d'archive RDF pour faciliter l'export, mais également à la possibilité d'interroger la base en SPARQL, en plus du RQL.