|
| Logilab a l'honneur d'avoir été invité à présenter ses travaux sur le projet NOÉMIE le 2 mai à l'atelier RoCED de la conférence KGC (https://www.knowledgegraph.tech/). Ce projet utilise des algorithmes génétiques pour permettre la transformation du format Intermac-NG vers du Intermarc. | | 536 |
(Titre en anglais: Learning Transformation Rules Between Bibliographical Formats Using Genetic Programming)
Temps de lecture 2 minute (~300 mots)
Nous avons l'honneur d'avoir été invités à parler de nos travaux à l'atelier RoCED qui aura lieu durant la conférence KGC 2022, en ligne, le 2 mai entre 9h et 12h EST (New-York) ou entre 15h et 18h heure française.
Cet atelier est spécialisé dans l'étude de la complexité, l'hétérogénéité, l'incertitude et l'évolution des données et des connaissances. Pour faire face à l'accroissement constant de la quantité de données et connaissances générées, il devient primordial d'appréhender ce volume pour pouvoir exploiter la connaissance sous-jacente. Cet atelier propose d'apporter des éléments de réponse à ce problème en explorant des applications d'apprentissage automatique, de fouille de données, ou de raisonnement sur des graphes de connaissance.
Dans ce cadre, Logilab (par l'intervention d'Élodie Thiéblin) présentera les résultats préliminaires d'une étude commanditée par la BnF (Bibliothèque nationale de France).
La BnF est actuellement en train de migrer son catalogue de données du format Intermarc (variante du MARC) vers le format Intermarc-NG (distingant notamment Oeuvre, Expression, Manifestation, Item). Cette migration est faite grâce à des règles écrites manuellement.
Pour préserver l'interopérabilité avec les applications qui ne traitent que le format Intermarc, il est envisagé d'apprendre la transformation inverse (Intermac-NG vers Intermarc) automatiquement. Comme la migration de données n'a pas eu complètement lieu, l'étude s'est concentrée sur l'apprentissage de règles de transformation de l'Intermarc vers le Dublin Core, basé sur un ensemble de notices bibliographiques disponibles dans les deux formats. Une preuve de concept a été développée en utilisant la programmation génétique, dont les résultats sont des règles plus ou moins complexes. Notre hypothèse est que cet apprentissage peut être appliqué à d'autres formats de données structurées.
Si vous souhaitez suivre cette présentation (et les autres présentations passionnantes prévues durant ces journées KGC) ne tardez pas à vous inscrire ici : https://www.knowledgegraph.tech/
Merci beaucoup à Nathalie Hernandez, Fathia Sais et Catherine Roussey de nous permettre de présenter nos travaux durant cet atelier.
Logilab been invited to participate in the RoCED workshop, occuring during KGC 2022.
This workshop focuses on contributions describing methods and uses-cases that rely on the application of reasoning and machine learning on complex, uncertain and evolving knowledge graphs.
We will present the preliminary results of a study commissioned by the National French Library (BnF).
The National French Library (BnF) is migrating its catalogue data from the Intermarc bibliographic format (similar to UniMARC) to Intermarc-NG with manually created rules.
To keep their data interoperable with applications which can only deal with Intermarc data for now, they would like to automatically learn the inverse transformation (Intermarc-NG to Intermarc).
The catalogue data has not been entirely migrated so far, therefore, the study focused on learning transformation rules from Intermarc to Dublin Core, based on a corpus of bibliographic records in both formats.
A proof of concept has been developed using genetic programming resulting in more or less complex rules.
We argue that this transformation rule learning algorithm could be applied to other structured data formats.
If you want to follow this presentation and other interesting talks, register here: https://www.knowledgegraph.tech/
We thank Nathalie Hernandez, Fathia Sais and Catherine Roussey for their invitation to this workshop. | Intégrer les données et les modèles dans l'industrie grâce à l'interopérabilité sémantique obtenue en utilisant les standards du domaine" est le titre à rallonge du dernier article que nous avons co-présenté à la conférence I-ESA 2022. | | 274 |
Temps de lecture 1 minute (~250 mots)
La onzième conférence pour l'interopérabilité des systèmes et applications d'entreprise, I-ESA 2022 a eu lieu en mars 2022 à Valence en Espagne.
Logilab y a co-présenté, avec les partenaires du projet TotalEnergies Semantic Framework, un article intitulé "Intégrer les données et les modèles dans l'industrie grâce à l'interopérabilité sémantique obtenue en utilisant les standards du domaine" (New ways of using standards for semantic interoperability towards integration of data and models in industry).
Le résumé de cet article est le suivant.
De récents groupements européens du programme H2020, des projets collaboratifs dans le domaine industriel et des avancées des organisations de standardisation convergent vers de nouvelles utilisations des standards internationaux pour intégrer les données et permettre de nouveaux types de collaboration le long des cycles de vies et au sein des écosystèmes des produits et installations industrielles.
Dans cet article, nous décrivons l'approche innovante adoptée par TotalEnergies pour pallier le manque d'interopérabilité entre les données produites au cours du cycle de vie d'une installation industrielle. Le résultat est le TotalEnergies Semantic Framework, qui se fonde sur des standards pour formaliser la sémantique des données échangées entre les partenaires et s'assurer que chacun peut opérer à son tour et dans ses propres applications les traitements associés à son rôle dans le processus global de conception, construction, exploitation, maintenance et démantellement des installations.
Une architecture centrée sur des données décentralisées partagées par de multiples acteurs ayant chacun une spécialité et un point de vue sur un système complexe ? C'est bien évidemment un cas d'usage idéal pour les techniques du Web sémantique que maîtrise Logilab !
Vous pourrez lire l'article complet ici | Le 10 mars 2022, l'IFREMER a présenté les résultats du projet http://resourcecode.info/ devant plus d’une centaine de parties prenantes. | | 378 |
400 mots - Temps de lecture 2 min
Le 10 mars 2022 a eu lieu le lancement de la « boite-à-outils Resourcecode » devant plus d’une centaine de partenaires du projet. Logilab est fière d’avoir pu participer à ce projet.
Resourcecode est un projet visant à soutenir les investissements et la croissance dans le secteur de l’énergie houlomotrice et maréomotrice par la création d’une boîte à outils intégrée de données marines.
Concrètement, des données décrivant l’état de la mer (vitesse du vent, hauteur des vagues, direction du courant, etc) sont enregistrées par des bouées de l’IFREMER (Institut Français de Recherche pour l'Exploitation de la Mer) et de ses partenaires. Des données de 1994 à 2020 sont disponibles pour des milliers de points de l’océan Atlantique et de la mer du Nord avec une résolution temporelle de l’ordre de l’heure. Une fois ces données enregistrées, elles peuvent être interpolées sur les points d’un maillage triangulaire.
Logilab a remporté un appel d’offre, déposé par l’Ifremer, dans le cadre de ce projet. Nous avons eu la charge de réaliser :
- une application web resourcecode.ifremer.fr permettant la visualisation des points où les données sont accessibles et proposant des outils statiques ou interactifs basés sur des calepins Jupyter afin d’étudier la mer au point considéré.
- produire une bibliothèque python resourcecode permettant de télécharger localement les données d’un point sous forme de
DataFrame Pandas. L'intégration continue de la forge GitLab de l'IFREMER génère avec Sphinx la documentation de cette bibliothèque.
- intégrer à cette bibliothèque des codes de calculs écrits par l’IFREMER et ses partenaires (codes écrits en R, MATLAB ou Python)
- mettre en place une architecture permettant à l’IFREMER et ses partenaires de construire des nouveaux outils (statiques ou interactifs). Ces outils sont développés et maintenus par l’IFREMER et ses partenaires, et automatiquement intégré à l’application web. Ils sont développés sur l’instance GitLab de l’Ifremer.
Lors de cet événement de lancement de Resourcecode, une démonstration en direct a pu être effectuée auprès du public : la bibliothèque a été installée et un dépôt de code contenant un calepin Jupyter a été cloné puis exécuté. Cela a permis de démontrer la facilité d'utilisation de cet outil, ainsi que la répétabilité offerte par ce type d’architecture, qui correspond aux attentes actuelles en matière de science ouverte (Open Science).
| |
| Cette année, comme l'année dernière, en février, Logilab était présente au [FOSDEM](https://fosdem.org/) (Free and Open Source Software Developers' European Meeting), qui est la conférence européenne des développeurs de logiciels libres et open-source. | | 593 |
Temps de lecture = 3 minutes (~ 600 mots)
Cette année, comme l'année dernière, le FOSDEM s'est déroulé intégralement en ligne en s'appuyant sur une infrastructure technique constituée de logiciels libres :
- matrix qui est un outil décentralisé de communication en temps réel qui repose sur un standard ouvert. Chaque session thématique avait son propre salon de discussion Matrix. Vous pouvez créer votre compte matrix sur joinmatrix.org.
- jitsi qui est une application libre et multiplateforme de visioconférence, VoIP et messagerie instantanée. Vous pouvez utiliser le service offert par un des chatons.
Au cours de cette édition du FOSDEM, nous avons participé aux sessions concernant Python et les plateformes de tests et d'intégration, au cours desquelles nous avons eu la chance de présenter CubicWeb et notre utilisation de GitLab.
CubicWeb: bootstraping a web-application from RDF data
Voici la page, le support
Le Web s'est d'abord développé comme un ensemble de documents connectés par des liens hypertexte, mais depuis quelques années, on assiste à une explosion du nombre de jeux de données publiées sur le Web en utilisant le standard RDF et les URLs pour désigner les objets représentés.
Publier ces données en permettant la négociation de contenu pour obtenir soit les données, soit du HTML à la même adresse (URL) est rarement effectué. Selon nous, cela s'explique par le fait qu'il n'existe pas de solution toute prête, ni d'interface d'administration de données RDF offrant les opérations CRUD habituelles associées à la définition fine de permissions.
CubicWeb est un système de gestion de contenu sémantique pour le Web de données liées, qui répond à ce besoin en offrant les fonctionnalités attendues d'un CMS et en rendant accessibles les données et pas uniquement une interface de consultation.
Nous avons présenté au FOSDEM l'utilisation de OWL2YAMS pour initialiser une nouvelle application CubicWeb à partir d'une ontologie OWL. L'application est ensuite directement utilisable pour publier les données RDF et l'ontologie utilisée, mais aussi pour parcourir, visualiser et administrer ces données avec une interface autogénérée.
How to improve the developer experience in Heptapod/GitLab
Voici la page, le support et la vidéo de cette présentation.
Logilab utilise depuis maintenant deux ans Heptapod, un fork amical de GitLab en achetant du support à Octobus.
Dans notre instance d'Heptapod, nous maintenons CubicWeb, les sous-composant les «cubes», nos projets clients, nos projets open-sources et nos projets internes.
Nous avons plusieurs centaines de projets dépendants les uns des autres dans Heptapod. À cette échelle, il nous paraît impossible d'assurer une cohérence des bonnes pratiques sans avoir recours à l'automatisation.
Dans cette présentation, nous avons détaillé les outils d'automatisation qui nous aident pour maintenir l'ensemble de nos projets, en particulier AssignBot et Code-Doctor. Certains de ces outils sont spécifiques à Mercurial, mais la plupart peuvent être utilisés avec Git dans GitLab.
Ils nous permettent de :
- Créer des demandes de fusion automatiquement dans les dépôts en fonction de certaines règles, comme les avertissements de dépréciation (un peu comme dependabot).
- Choisir un reviewer pour les demandes de fusion en fonction des préférences des développeurs.
- S'assurer de commiter, tagger, mettre à jour le changelog, publier sur PyPi lors de la sortie d'une nouvelle version.
- Mutualiser les configurations GitLab CI avec des templates.
- Héberger des images docker sur la forge.
- Avoir des sites web statiques, de la documentation ou des applications web à jour.
Chaque cas d'utilisation peut être résolu facilement, mais c'est en les combinant que l'on facilite vraiment la vie des développeurs et que l'on gagne vraiment en efficacité.
Le mot de la fin
Merci beaucoup à toutes les personnes qui ont aidé à organiser cette nouvelle édition ! | Logilab a participé à l'édition 2021 de la conférence SWIB (Semantic Web in Librairies), dédiée à l'étude des technologies du Web Sémantique appliquées aux bibliothèques, pour y présenter deux projets qui ont reçu des retours positifs.
Temps de lecture = 3 min (650 mots) | | 550 |
Temps de lecture = 3 min (650 mots)
Logilab a participé à l'édition 2021 de la conférence SWIB (Semantic Web in Librairies), dédiée à l'étude des technologies du Web Sémantique appliquées aux bibliothèques, pour y présenter deux projets qui ont reçu des retours positifs.
SparqlExplorer
Elodie Thiéblin a présenté la dernière version de SparqlExplorer. L'enregistrement est disponible sur youtube.
Le projet SparqlExplorer permet d'explorer un entrepôt SPARQL en appliquant des vues qui s'adaptent au type de la ressource à afficher.
Chaque ressource étant identifiée par une URI, il est possible de récupérer le type d'une resource en cherchant dans l'entrepôt SPARQL un triplet RDF de la forme <uri_ma_ressource> rdf:type <uri_du_type>. Une fois le type connu, le SparqlExplorer sélectionne parmi toutes les vues fournies par un serveur de vues, la vue la plus adaptée pour afficher la resource. Cette vue sélectionnée récupère les données nécessaires dans l'entrepôt SPARQL et génère un morceau de page HTML qui est inséré dans l'affichage du SparqlExplorer. Lorsqu'un lien vers l'URI d'une autre ressource est suivi, le processus est appliqué de nouveau pour obtenir le type, détermier la vue la plus adaptée puis calculer l'affichage de la ressource. Il est ainsi possible de naviguer d'une ressource à une autre au sein d'un entrepôt SPARQL en suivant des liens dans des pages HTML plutôt qu'en écrivant des requêtes SPARQL.
En mettant à disposition des vues adaptées aux vocabulaires standardisés du domaine des bibliothèques, le SparqlExplorer devient un outil générique qui permet naviguer dans de multiples catalogues publiés sous forme d'entrepôts RDF interrogeables en SPARQL, sans qu'il soit nécessaire de développer une application web spécifique à chacun de ces catalogues en ligne.
OWL2YAMS
La deuxième intervention était un atelier pratique animé par Fabien Amarger et consacré à OWL2YAMS, lequel permet de publier des données RDF facilement avec CubicWeb.
Le cadriciel CubicWeb est utilisé dans la majorité des projets à Logilab. Son développement a toujours été orienté pour profiter au maximum des concepts du Web Sémantique. Depuis plusieurs années, CubicWeb se positionne comme un cadriciel de développement d'application pour le Web de données liées. La négociation de contenu est par exemple disponible par défaut dans CubicWeb, ce qui permet, pour chaque ressource, de télécharger les données au format RDF avec une simple requête HTTP.
L'outil OWL2YAMS permet de créer une application CubicWeb à partir d'une ontologie OWL avec une seule commande. Il suffit ensuite de déployer cette application pour publier cette ontologie en ligne. Un script générique permet d'importer dans l'application des données RDF utilisant le vocabulaire de cette même ontologie.
A notre connaissance, OWL2YAMS et CubicWeb constituent la méthode la plus simple et la plus directe pour mettre en ligne des données liées sur le web en utilisant les standards du Web sémantique et en disposant d'une application web moderne qui permet à la fois l'affichage et la navigation en HTML, le téléchargement du RDF par négociation de contenu et l'utilisation d'une interface d'administration pour la gestion du contenu et des droits d'accès.
Conclusion
Nous sommes très contents d'avoir pu proposer ces deux outils durant la conférence SWIB21. Les retours ont été très positifs et nous confortent dans l'idée que, autant le SparlExplorer que CubicWeb, représentent des solutions efficaces qui répondent à de réels besoins, en particulier dans le domaine de la gestion documentaire ou patrimoniale et des archives. | Open Source Experience (https://www.opensource-experience.com) a eu lieu le 8 et 9 novembre 2021 à Paris. Nous y avons présenté notre travail lors des sessions Could DevOps et Full Stack Web. | | 324 |
Temps de lecture = 2 min (~ 300 mots)
Open Source Experience est le rendez-vous européen de la communauté Open Source qui a eu lieu le 8 et 9 novembre 2021 à Paris. Au programme, il y eut des conférences, tables rondes et sessions plénières riches en retours d’expérience et en innovations réunissant la communauté de l'Open Source et du Logiciel Libre, ainsi que les entreprises utilisatrices en recherche d’informations.
Nous y avons présenté notre travail lors des sessions Could DevOps et Full Stack Web.
FranceArchives, les archives sur une infrastructure du 21e siècle
Le site FranceArchives développé par Logilab pour le Service interministériel des Archives de France (SIAF) permet aux professionnels et aux amateurs d'explorer les archives publiques de France.
Arthur Lutz et Carine Dengler ont présenté notre dernier grand chantier en date pour ce site, à savoir, la migration vers Kubernetes, en détaillant la pile technique et en résumant notre retour d'expérience.
L'enregistrement vidéo est disponible: FranceArchives sur Kubernetes (avec l'original sur youtube).
Transformation continue des applications en production
Certains considèrent qu’une application a une durée de vie de quelques années et qu’à ce terme, l’application doit être réécrite avec les outils du moment. Nous préférons faire évoluer en continu nos applications en production et préserver l’investissement qu’elles constituent.
Nicolas Chauvat a décrit ce processus de transformation qui touche à tous les aspects des projets: la gouvernance du logiciel libre sous-jacent, l’architecture des applications, les bibliothèques et composants libres employés, le stockage des données, l’interface utilisateur, l’API externe, les langages de programmation utilisés, les méthodes de test et de déploiement, les outils de supervision, etc.
Il a terminé en présentant nos innovations en cours, qui visent à augmenter la fréquence des déploiements sans compromettre la qualité, grâce à une automatisation croissante des processus, y compris pour la modification du code source.
L'enregistrement vidéo est disponible: Transformation continue des applications (avec l'original sur youtube).
Rendez-vous à la fin de l'année 2022 pour la prochaine édition ! | Nous avons introduit le typage python dans la bibliothèque RQL qui est au cœur de CubicWeb et voici ce que nous avons appris en le faisant. | | 640 |
Temps de lecture = 4 min (~700 mots)
Contexte
Le projet RQL est l'implémentation d'un parser pour un langage de requête du même nom permettant d'interroger une base de données qui a été créée avec un schéma YAMS. Ce langage de requête est au coeur de CubicWeb.
Le cadriciel CubicWeb est très largement utilisé dans nos projets à Logilab, et donc nous continuons à maintenir CubicWeb et ses dépendances en le faisant évoluer suivant nos besoins. Parfois ce besoin concerne le langage d'interrogation RQL lui-même. Nous aimerions par exemple ajouter les chemins de propriétés qui existent en SPARQL (voir SPARQL property paths) ou encore la possibilité d'avoir des propriétés calculées dans les attributs de projection.
Mise en oeuvre
Pour faciliter ces évolutions, nous avons décidé de profiter des progrès récents de Python et d'enrichir la base code avec des annotations de type et de nous appuyer sur MyPy pour valider nos remaniements.
Le projet de typage de RQL a été un projet de longue haleine. Nous pensions que quelques semaines suffiraient mais il a été nécessaire d'y passer plusieurs mois pour arriver à un résultat satisfaisant. Typer l'ensemble d'un projet nécessite de comprendre son fonctionnement global, ce qui peut très vite être chronophage, surtout quand les pratiques de développement ont bien évolué.
Au lieu de s'attaquer au monolithe d'un seul coup, nous avons commencé par typer les modules séparémment les uns des autres, en ajoutant des commentaires #type: ignore aux endroits ne pouvant pas encore être typés, et sans forcémment essayer de détailler les interactions entre les différents modules. Les # type: ignore ont ensuite peu a peu disparu.
Problèmes rencontrés
Le typage aura permis de déceler des soucis de conception du projet RQL et de voir les limites du typage en Python.
Ce principe dit qu'une sous-classe doit pouvoir être utilisée là où une classe parente est attendue. Celui-ci n'est pas toujours respecté dans RQL. Par exemple, la méthode copy de la classe Insert ne prend pas d'argument alors que la même méthode sur la classe BaseNode en prend un. Cette différence de signature pourrait causer des problèmes dans du code client.
Le problème a été signalé par mypy:
rql/stmts.py:1283: error: Signature of "copy" incompatible with supertype "BaseNode" [override]
rql/stmts.py:1283: note: def copy(self, stmt: Optional[Statement] = ...) -> BaseNode
rql/stmts.py:1283: note: def copy(self) -> Insert
Found 3 errors in 1 file (checked 1 source file)
Mixins difficilement typables
L'implémentation de l'arbre syntaxique qui a été choisie utilise beaucoup de mixins. Ces mixins ne sont pas typables de manière élégante.
Prenons par exemple le mixin OperatorExpressionMixin suivant:
class OperatorExpressionMixin:
...
def is_equivalent(self: Self, other: Any) -> bool:
if not Node.is_equivalent(self, other):
return False
return self.operator == other.operator
...
Il ne s'applique que sur des classes qui héritent de BaseNode et qui ont un attribut "operator" mais ce type ne peut pas être exprimé, car on aurait besoin de l'intersection de deux types, dont un classe, ce qui n'existe pas en Python (https://github.com/python/typing/issues/213).
En Typescript par exemple on aurait écrit:
type Self = BaseNode & {operator: string}
Covariance/Contravariance/...
Les types génériques, List par exemple, sont définis comme acceptant des paramètres de type. Lorsqu'on déclare ces paramètres de type (en utilisant TypeVar), il faut être attentif à choisir la variance appropriée, ce qui n'est pas trivial quand on vient de langages où ce n'est pas nécessaire (ni Typescript, ni C++, ni Java n'y font référence).
Conclusion
Nous avons publié une version 0.38 de RQL qui contient l'ajout des types et ne casse pas l'API utilisée. Ceci va nous aider à ajouter de nouvelles fonctionnalités et à remanier le code pour le simplifier. L'introduction du typage nous a également permis de déceler du code buggé ou jamais utilisé et de mieux documenter le code de RQL.
Merci à Patrick pour le temps qu'il a consacré à ce sujet important. Vous pouvez consulter son article de blog sur ce sujet ici | Nous proposons une série de quelques articles où nous allons analyser les licences sportives en France à l’aide de Pandas, et nous réaliserons une interface utilisateur avec des widgets. | | 1957 |
Temps de lecture estimé 10 minutes.
Nous proposons une série de quelques articles où nous allons utiliser la
bibliothèque Pandas pour analyser les licences sportives en France. En chemin,
nous réaliserons une interface utilisateur avec des widgets.
Cette série sera découpée en trois articles. Dans le premier, nous allons
explorer le jeu de données à notre disposition en utilisant la bibliothèque
Pandas. Dans le second, nous introduirons Jupyter et les ipywidgets qui
nous permettront de faire une interface utilisateur. Nous terminerons la série
en présentant Voilà ainsi que le thème jupyter-flex.
Pandas, jupyter, ipywidgets, voilà ? De quoi parle-t-on ?
- Pandas est une bibliothèque Python très connue,
qui permet d’analyser et d’étudier des jeux de données. Elle est conçue pour
traiter des jeux de données tabulaires (ceux pouvant être lus par un tableur).
Les données peuvent être de différents types (nombres, dates, chaînes de
caractères, etc). Pandas est, comme nous le verrons, très efficace. Les
fonctions coûteuses de Pandas sont généralement écrites en C, et Python est
utilisé pour manipuler et appeler ces fonctions.
- Jupyter est une plateforme, utilisable dans un
navigateur web qui permet d’exécuter des calepins (notebooks). Un calepin
est un fichier qui combine des cellules de différents types : du code
exécutable, du texte, des visualisations, etc.
- Les Ipywidgets sont des
éléments graphiques interactifs que l’on peut ajouter à des calepins
Jupyter. Ils vont nous permettre de proposer aux utilisateurs de choisir un
fichier, choisir un élément dans une liste, cliquer sur un bouton, etc.
Chacune des actions de l’utilisateur peut être associée à une fonction Python,
et donc rendre le calepin interactif.
- Voilà est une application qui
permet d’exécuter des calepins, mais sans afficher le code source − qui est
visible par défaut dans Jupyter. L’énorme intérêt à cela est qu’un calepin
Jupyter devient alors une application web à part entière, utilisable dans le
navigateur, et seuls les éléments indispensables à son utilisation sont
visibles.
Après cette petite phase de présentation, découvrons les données que nous allons
manipuler aujourd’hui.
Présentation des données
Dans cette série d’articles nous utilisons des données issues de
https://data.gouv.fr. Il s’agit du nombre de licences
sportives, par sexe, par catégorie d’âges, par municipalité pour les années 2012
à 2018. Les données brutes peuvent être téléchargées
ici.
Nous avons réalisé une opération de nettoyage sur ces données, afin de nous
assurer d’avoir une structure cohérente pour chaque année. Nous avons également
remplacé les municipalités par leur département, ce qui permet d’alléger les
données à manipuler. Au final, nous obtenons six fichiers csv, un par année,
dont la structure est la suivante :
dep_code,dep_name,fed_code,fed_name,gender,age,lic_holders
01,Ain,101,Fédération Française d'athlétisme,F,00-04,0
01,Ain,101,Fédération Française d'athlétisme,F,05-09,75
01,Ain,101,Fédération Française d'athlétisme,F,10-14,251
01,Ain,101,Fédération Française d'athlétisme,F,15-19,130
01,Ain,101,Fédération Française d'athlétisme,F,20-29,39
01,Ain,101,Fédération Française d'athlétisme,F,30-44,105
01,Ain,101,Fédération Française d'athlétisme,F,45-59,105
01,Ain,101,Fédération Française d'athlétisme,F,60-74,23
01,Ain,101,Fédération Française d'athlétisme,F,75+,0
01,Ain,101,Fédération Française d'athlétisme,M,00-04,0
01,Ain,101,Fédération Française d'athlétisme,M,05-09,106
01,Ain,101,Fédération Française d'athlétisme,M,10-14,278
[…]
| Nom de colonne |
Description |
dep_code |
Code (unique) du département |
dep_name |
Nom du département |
fed_code |
Code (unique) de la fédération sportive |
fed_name |
Nom de la fédération sportive |
gender |
Genre (peut être M ou F) |
age |
La tranche d’âge considérée (peut être 00-04, 05-09, 10-14, 15-19, 20-29, 30-44, 44-59, 60-74, 75+) |
lic_holders |
Le nombre de licenciés dans le département, enregistrés dans cette fédération, de ce genre et de cette tranche d’âge. |
Chargement de données pour une année
Pandas offre un nombre important de fonctions permettant de charger des données
depuis différents formats: CSV, Excel, tableaux HTML, JSON, bases SQL, HDF5, etc.
Nous allons utiliser la fonction read_csv. Cette fonction utilise les éléments
de la première ligne comme noms de colonnes. Pandas essaie également de détecter
les types de colonnes à utiliser (nombre, date, chaîne de caractères) en se
basant sur les premiers éléments lus. Nous spécifions donc à Pandas que la
colonne dep_code est de type str, pour prendre en compte les départements
Corse (2A et 2B), sans quoi Pandas émettra un avertissement.
from pathlib import Path
import pandas as pd
DATA_DIR = Path().resolve() / "data" # en supposant que les données sont dans le dossier data
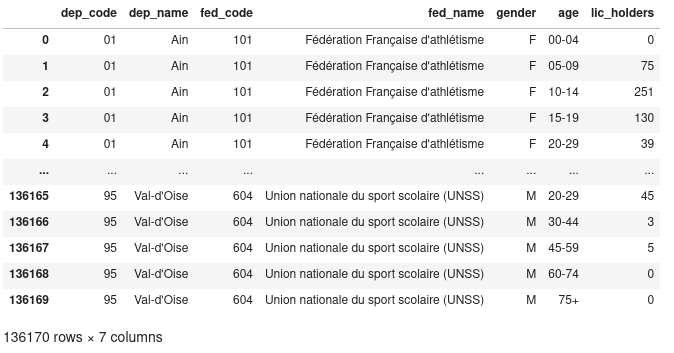
d2012 = pd.read_csv(
DATA_DIR / "sport_license_holders_2012.csv", dtype={"dep_code": str}
)
Nous obtenons alors la DataFrame suivante :
Premières analyses
À partir de là, nous pouvons commencer à étudier le jeu de données. Par exemple,
en demandant le nom de chaque fédération :
>>> d2012["fed_name"].unique()
array(["Fédération Française d'athlétisme",
"Fédération Française des sociétés d'aviron",
'Fédération Française de badminton',
'Fédération Française de basketball',
'Fédération Française de boxe',
'Fédération Française de canoë-kayak',
'Fédération Française de cyclisme',
"Fédération Française d'équitation",
"Fédération Française d'escrime",
[…],
'Fédération française de pentathlon moderne',
'Fédération Française de javelot tir sur cible',
'Fédération Flying Disc France', 'Fédération Française Maccabi',
'Fédération Française de la course camarguaise',
'Fédération Française de la course landaise',
'Fédération Française de ballon au poing'], dtype=object)
Nous pouvons facilement compter le nombre total, toutes catégories
confondues, de licenciés :
>>> d2012["lic_holders"].sum()
12356101
Une des forces de Pandas réside dans la possibilité de créer des filtres, ou des
groupes simplement. Par exemple, pour compter le nombre de licenciés hommes, nous
pouvons créer un masque (True si le genre est M et False sinon), puis
appliquer ce masque à notre DataFrame.
>>> mask_male = d2012["gender"] == "M"
>>> d2012[mask_male]["lic_holders"].sum()
7806235
Ainsi, en 2012, il y avait 7 806 235 licenciés masculins de sport en France.
Combien y a-t-il de licenciés, en 2012, par tranche d’âge ? Pour répondre à
cette question, nous utilisons la méthode groupby de Pandas, en donnant le nom
de la colonne sur laquelle nous souhaitons faire le groupe :
>>> d2012.groupby("age")["lic_holders"].sum()
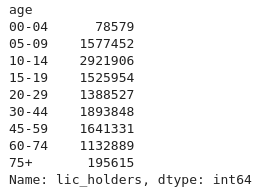
Cette méthode permet de constituer des groupes, selon une clé (généralement le
nom d’une ou plusieurs colonnes), puis d’appliquer sur chaque groupe partageant
la même clé une fonction d’agrégation. Dans notre exemple, la clé de chaque
groupe est l’âge, et la fonction d’agrégation la somme sur la colonne
lic_holders.
Nous pouvons effectuer le même type de calcul, mais en groupant cette fois-ci
sur le genre et l’âge, ce qui donne le résultat suivant :
>>> d2012.groupby(["gender", "age"])["lic_holders"].sum()
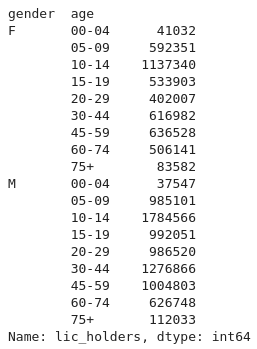
Les deux résultats que nous venons d’obtenir sont ce qu’on appelle des Series.
C’est-à-dire, des DataFrames mais constituées d’une seule colonne.
On observe que les groupes sont directement constitués par l’index. Dans le cas
d’un groupby() avec une seule colonne, nous avons un index simple et dans le
cas où plusieurs colonnes sont utilisées, nous obtenons ce qu’on appelle un
index multiple ou un index hiérarchique. Nous allons étudier cela un peu
plus en profondeur dans la suite.
Créer un index sur mesure
Dans la DataFrame que nous avons chargée, de très nombreuses données sont
répétées et ne sont utilisées que pour définir des groupes (dep_code,
dep_name, gender, age etc). Nous allons mettre toutes ces données dans
l’index de la DataFrame. Cela permet d’avoir dans l’index les données de
chaque groupe, et dans la DataFrame les données desdits groupes (ici le nombre
de licenciés sportifs).
Pour ce faire, nous utilisons la méthode set_index :
>>> d2012.set_index(
["dep_code", "dep_name", "fed_code", "fed_name", "gender", "age"], inplace=True
)
>>> d2012
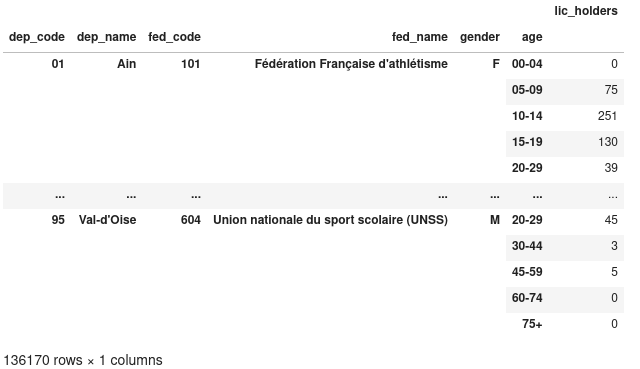
Nous avons ainsi une DataFrame à une seule colonne, et avec un index à six
niveaux. Nous pouvons toujours grouper par genre et par âge, en utilisant le
mot-clé level, indiquant qu’il faut grouper en utilisant l’index :
>>> d2012.groupby(level=["gender", "age"]).sum()
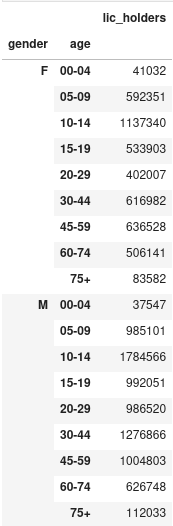
Dans quels départements la course camarguaise est-elle pratiquée ?
La course camarguaise est un sport traditionnel dans lequel les participants
tentent d'attraper des attributs primés fixés au frontal et aux cornes d'un
bœuf. Pour savoir dans quels départements ce sport est le plus pratiqué, nous
allons :
- Filtrer sur l’index pour n’avoir que les enregistrements correspondant à ce
sport (le code de la fédération est 215) ;
- Grouper par code et nom de département, et compter le nombre de licenciés ;
- Afficher les groupes triés par ordre décroissant de licenciés.
>>> d2012_camarg = d2012.xs(
215, level="fed_code"
) # Only keep the rows with index equal to 215 at level ``fed_code``
>>> d2012_camarg_depts = d2012_camarg.groupby(
["dep_code", "dep_name"]
).sum() # Group the data by department (only keep departments with non-null values)
>>> d2012_camarg_depts.sort_values(
by="lic_holders", ascending=False
) # Sort the data in decreasing order
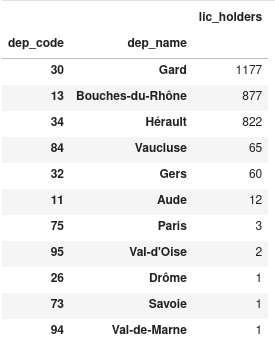
Sans trop de surprise, on observe que c’est le Gard (où est la Camargue), les
Bouches-du-Rhône, l’Hérault et le Vaucluse (départements qui entourent le Gard)
qui ont le plus de licenciés dans ce sport.
Quels sont les sports les plus pratiqués par les femmes ?
Nous allons :
- Sélectionner les enregistrements correspondant à
gender = 'F' ;
- Grouper par fédération et compter le nombre de licenciées ;
- Afficher les dix sports avec le plus de licenciées.
>>> d2012_females_top_10 = d2012.xs("F", level="gender")
.groupby(["fed_code", "fed_name"])
.sum()
.nlargest(10, "lic_holders")
>>> d2012_females_top_10

Pandas permet également de faire des graphiques. Par défaut c’est la
bibliothèque matplotlib qui est utilisée. Nous
pouvons par exemple utiliser un diagramme en bâtons pour afficher le top 10 des
sports pratiqués par les femmes :
>>> d2012_females_top_10.plot(
kind="bar",
legend=False,
xlabel="Sport federation",
ylabel="Number of license holders",
color="#CC0066",
title="Female sport license holders in 2012 (top 10)",
)
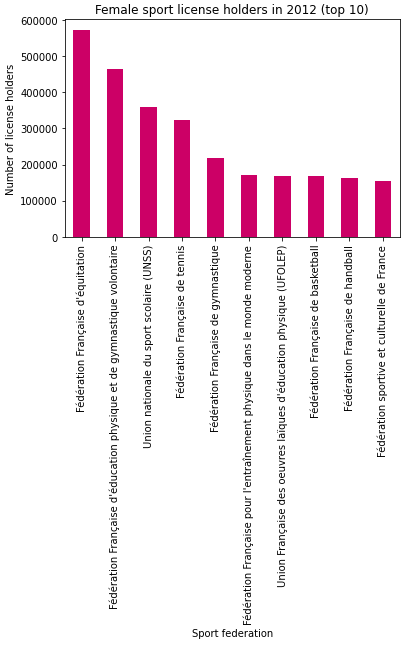
Charger les données pour toutes les années
Dans la section précédente, nous avons chargé uniquement les données de l’année
2012. Mais nous avons bien plus de données que cela. Nous allons donc charger
chaque fichier, puis renommer la colonne lic_holders en fonction de l’année en
cours. Nous aurons ainsi une DataFrame, avec en colonne le nombre de licenciés
par année, et en index les différents groupes.
Nous allons faire une liste years_dfs qui va contenir toutes les DataFrames,
une par année, puis nous allons simplement les concaténer. Cela donne donc :
>>> years_dfs = []
>>> for year in range(2012, 2019):
... fname = f"sport_license_holders_{year}.csv"
... yr_df = pd.read_csv(
... DATA_DIR / fname,
... dtype={"dep_code": str},
... index_col=["dep_code", "dep_name", "fed_code", "fed_name", "gender", "age"],
... )
... yr_df.rename(columns={"lic_holders": str(year)}, inplace=True)
... year_dfs.append(yr_df)
>>>
On concatène toutes les DataFrames, en fonction de l’index (axis=1) :
>>> data = pd.concat(years_df, axis=1)
>>> data
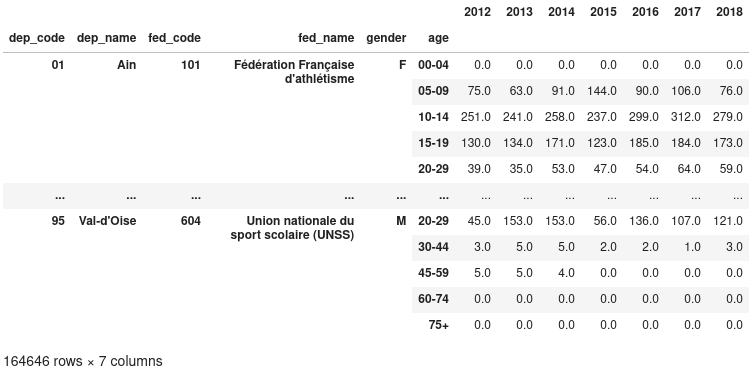
Nous avons ainsi une DataFrame avec plus de 1.6 million de lignes, et 7
colonnes.
On peut maintenant afficher, par exemple, les 10 sports les plus pratiqués en
fonction des années :
>>> data_sport = data.groupby(level=["fed_code", "fed_name"]).sum()
>>> data_sport.nlargest(10, "2012")
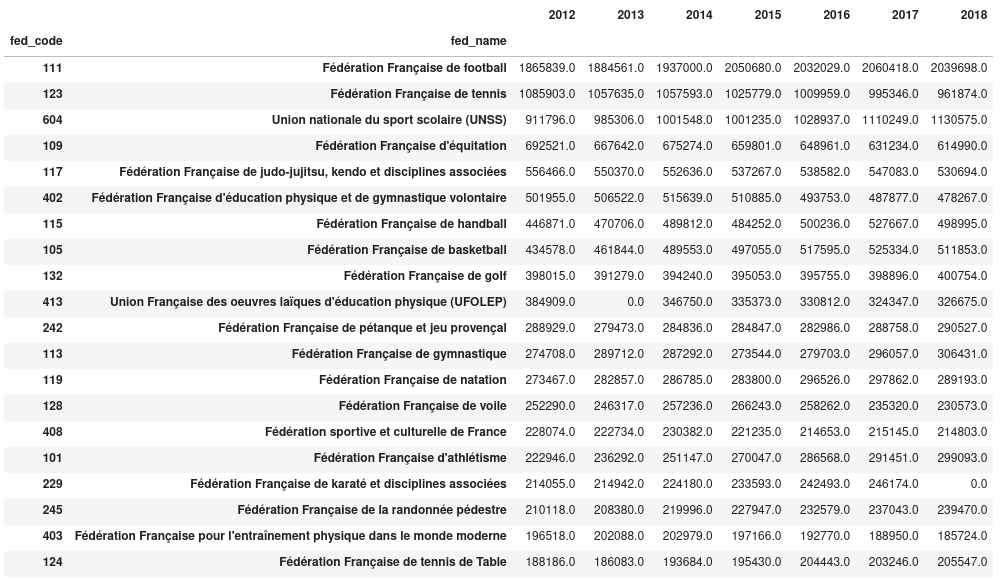
Nous avons ainsi le nombre de licenciés, par fédération et par année pour les
10 plus grosses fédérations de 2012. Le tri est effectué par rapport aux données
de 2012.
On notera qu’en 2018 il y a 0 licencié de Karaté. Cela est probablement une
erreur dans les données, ce qui peut arriver.
Tracer l'évolution du nombre de licenciés avec Plotly
Nous pouvons maintenant suivre l’évolution du nombre de licenciés dans certaines
disciplines. Nous sélectionnons les sports dont le code de fédération est 109,
115, 242, 117.
>>> sel_data_sports = data_sports.loc[
... [109, 115, 242, 117]
... ] # Select the rows whose value at the first level of the index (``fed_code``)
... # is one of the list items
>>> # Drop the first level of the index (``fed_code``)
>>> sel_data_sports = sel_data_sports.droplevel(0)
>>> # Will be used as the title of the legend
>>> sel_data_sports.index.name = "Federations"
>>> sel_data_sports.transpose().plot(
... title="Sport license holders", xlabel="year", ylabel="number of license holders"
...) # Transpose to have the years as the index (will be the X axis)
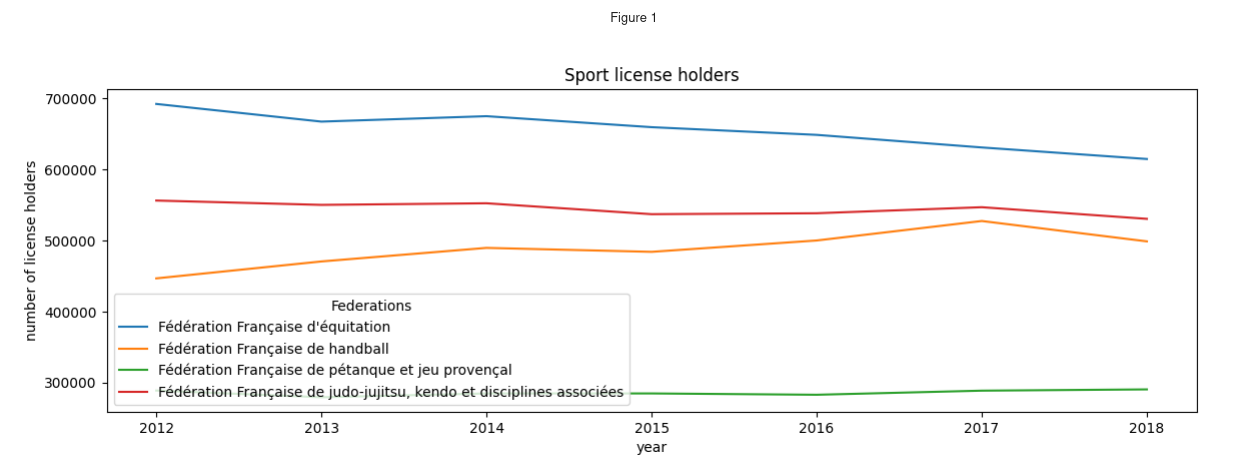
Comme nous le disions, par défaut Pandas utilise la bibliothèque matplotlib
pour générer les graphiques. La figure produite ici est statique, elle peut
facilement être insérée dans un rapport par exemple, mais cela présente des
difficultés lors de la phase d’exploration.
Depuis quelque temps maintenant, Pandas est compatible avec plusieurs
bibliothèques de visualisation. Il y a notamment
Plotly, qui permet de faire des graphiques
interactifs utilisables dans le navigateur web.
Pour utiliser Plotly, il est nécessaire de changer la bibliothèque utilisée
par défaut.
# Choose Plotly as the plotting back-end
# this has to be done only once, usually at the begining of the code
>>> pd.options.plotting.backend = "plotly"
Une fois Plotly configurée, nous pouvons retracer le graphique, comme
précédemment :
>>> fig = sel_data_sports.transpose().plot(title="Sport license holders")
>>> fig.update_layout(xaxis_title="year", yaxis_title="number of license holders")
>>> fig
Dans un environnement Jupyter, la figure produite est celle-ci, et il est
possible de sélectionner/désélectionner les courbes à afficher :
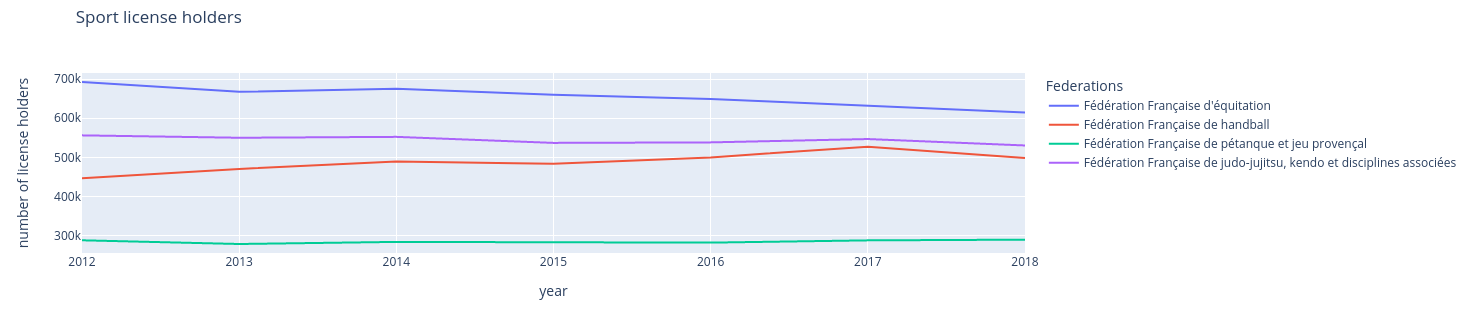
Quelle est la prochaine étape ?
Nous avons dans ce premier article, chargé avec Pandas des données textuelles au
format CSV.
Nous avons vu comment et pourquoi utiliser un index multiple. Cela nous a permis
de calculer quelques statistiques simples sur des groupes d’individus. Nous
avons également produit des visualisations avec matplotlib et avec Plotly.
Dans le prochain article, nous utiliserons des widgets Jupyter pour manipuler
dynamiquement les données à afficher sur les graphiques. | |
| Fort de ses références au sein des établissements publics et de l'administration française, le logiciel libre CubicWeb a été ajouté au catalogue des outils numériques utilisés par les services publics. | | 56 |
Fort de ses références au sein des établissements publics et de l'administration française, notamment à la Bibliothèque nationale de France avec data.bnf.fr, aux Archives de France avec France Archives et dans plusieurs équipes de recherche en humanités numériques, le logiciel libre CubicWeb a été ajouté au catalogue GouvTech des outils numériques utilisés par les services publics.
| La prochaine édition de SemWeb.Pro aura lieu en ligne le jeudi 9 décembre 2021.
Nous vous invitons à soumettre vos propositions de présentation en répondant à l'appel à communication https://2021.semweb.pro/ | | 33 |
La prochaine édition de SemWeb.Pro aura lieu en ligne le jeudi 9 décembre.

Nous vous invitons à soumettre vos propositions de présentation en répondant à l'appel à communication avant le 5 novembre 2021. | FranceArchives est un portail du service interministériel des archives de France développé par Logilab. Il utilise des technologies du Web sémantique. | | 2954 |
Chloë Fize (Service interministériel des Archives de France), Elodie
Thiéblin (Logilab)
Présentation générale de FranceArchives
Qu'est-ce que c'est les archives?
Selon le code du patrimoine, les archives sont l'ensemble des
documents, y compris les données, quels que soient leur date, leur forme
et leur support matériel, produits ou reçus par toute personne
physique ou morale, et par tout organisme public ou privé, dans
l'exercice de leur activité. Ces documents sont soit conservés par
leurs créateurs ou leurs successeurs pour faire la preuve d'un droit ou
d'un événement, soit transmis à l'institution d'archives compétente en
raison de leur valeur
historique...

Elementaire non ?
Les archives sont plus simplement des documents, divers et variés !




Dans notre imaginaire, en général, les archives ne sont que de vieux
papiers poussiéreux, rédigés dans des langues obscures et à première vue
indéchiffrables, jalousement cachés au fond de sombres et froids
placards... Et dans le pire des cas, elles sont cachées dans les
sous-sols ou les greniers... Un petit peu comme ça :

Mais détrompez-vous, les documents d'archives sont partout et peuvent
être bien plus agréables à admirer que vous ne l'imaginez. En France,
plus de 4 000 kilomètres linéaires d'archives sont conservés dans
plus de 500 services d'archives nationales, régionales,
départementales et municipales sans compter les services d'archives
privés (entreprises, associations, etc). On regroupe les documents en
fonds.\
Voici des fonds, bien proprement rangés dans leurs cartons... C'est
quand même plus sympathique ?

Mais comment s'y retrouver ? Comment savoir que LE document que je
recherche est bien dans cette boite nommée simplement par des lettres et
des chiffres ? Pour cela, il faut les décrire et ensuite les communiquer
à qui veut les consulter. Car la vocation première des archives, c'est
que tout le monde puisse en effet les consulter... Oui, oui, y compris
vous !
Ressources en ligne des archives
Les archivistes ont toujours cherché à exploiter les technologies les
plus en pointe pour communiquer à tous les publics les documents qu'ils
conservent : microfilms, numérisation, site web... Et de fait, depuis
plus de 20 ans, les services d'archives mettent à disposition de
tous des inventaires avec ou sans documents numérisés, consultables
directement en ligne sur plus de 300 sites internet.

La raison? Que tout le monde puisse y avoir accès ! Eh oui, les
archives c'est comme la bonne humeur, ça se commmunique, et par tous les
moyens !

C'est là toute la vocation du portail FranceArchives :
-
Permettre aux chercheurs, étudiants, curieux, amateurs de généalogie
ou qui que vous soyez, de repérer les ressources de nombreux
services d'archives publics et privés pour, dans un second temps,
les consulter sur les sites web ou dans les salles de lecture de ces
services.
-
Valoriser les fonds et services d'archives des quatre coins de la
France.
-
Mettre à disposition des ressources archivistiques professionnelles
ou des textes de loi.
Comment y accéder?
L'accès et la recherche sur le portail sont construits pour être les
plus intuitifs possible et pour mener le chercheur, amateur ou expert à
trouver son bonheur dans cette caverne aux merveilles... Suivez le guide
!
FranceArchives
FranceArchives : qu'est-ce que c'est ?
Le portail est porté par le Ministère de la Culture et a été mis en
ligne au mois de mars 2017. Il est géré et maintenu par le service
interministériel des archives de France (SIAF).
FranceArchives en chiffres :\
Au mois de mars 2021, la 105ème convention d\'adhésion au
portail FranceArchives a été signée. Vous pouvez donc consulter les
fonds de 2 ministères, 4 services à compétences nationales (Archives
nationales, Archives nationales du monde du travail, Archives nationales
d\'Outre-Mer et la Médiathèque de l\'architecture et du patrimoine), 63
archives départementals, 19 archives municipales, 13 établissements
publics, 4 associations ou entreprises.
Plus de 57 000 instruments de recherche sont consultables et
réutilisables. Ils contiennent près de 13 000 000 de descriptions.
FranceArchives : comment ça fonctionne ?
Effectuer une requête simple

Tout en s'aidant de l'autocomplétion
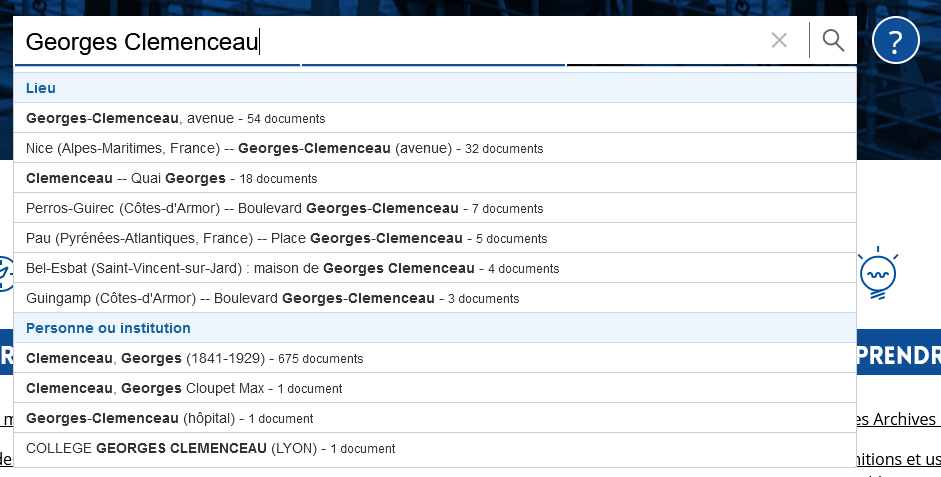
Et enfin affiner sa recherche grâce aux facettes
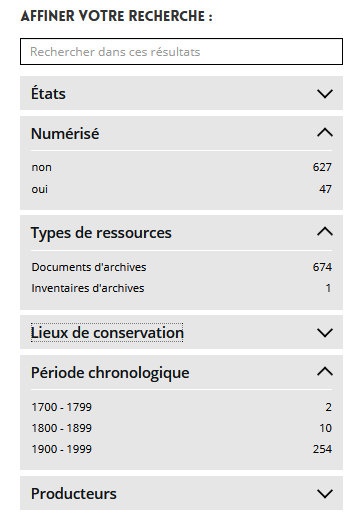
Les archives et leurs métadonnées
Vous avez réussi à trouver votre bonheur ? Parfait ! Mais vous n'avez
pas trouvé de documents d'archives numérisés ? C'est normal, seulement
5% des archives conservées en France sont numérisées. Le reste est
accessible en ligne uniquement grâce aux descriptions ou métadonnées et
doit être consulté dans les salles de lecture des services qui les
conservent.
Le document d'archives numérisé est une photographie du document. Sur
FranceArchives, vous pourrez trouver certains documents numérisés, à
l'image du célèbre exemple qui suit :

Mais vous ne trouverez la plupart du temps que des métadonnées, à savoir
le contenu de la lettre, son auteur, son destinataire, sa date, des
remarques sur sa forme et/ou son fond. C'est là qu'est la différence
entre un document numérisé et une métadonnée numérique.
Vous voulez un exemple? Très bien, les métadonnées numériques c'est...
ça :

Avouez que ça vous fait rêver ! Eh bien cette belle lettre que vous avez
vu précédemment peut être transformée en données et donc ressembler à...
ces lignes en couleurs et comportant plein d'informations pouvant
paraitre incompréhensibles. N'ayez pas peur on va tout vous expliquer.
Mais alors d'où viennent les métadonnées et à quoi ressemblent-elles?
Les services d'archives décrivent leurs fonds dans des instruments de
recherche. Ce sont ces instruments qui sont mis en ligne sur
FranceArchives et consultables par tout un chacun. Ils ne donnent pas
accès au document numérisé, comme nous l'évoquions plus haut, mais à sa
description. Ces éléments permettent de décrire avec précision les
documents que l'on va retrouver dans le fonds et donc de répondre à vos
multiples questionnements sans sortir le document de son joli carton de
protection. Quand vous consultez une notice sur le portail, il vous est
ensuite possible d'accèder directement au site web du service qui
conserve le document décrit grâce au bouton Accéder au site.
Alors où sont passées les données que nous avons vu plus haut ? Elles
sont là, partout, juste sous vos yeux. Vous les voyez ? Regardez...
Voici ce que vous voyez lorsque vous requêtez FranceArchives:
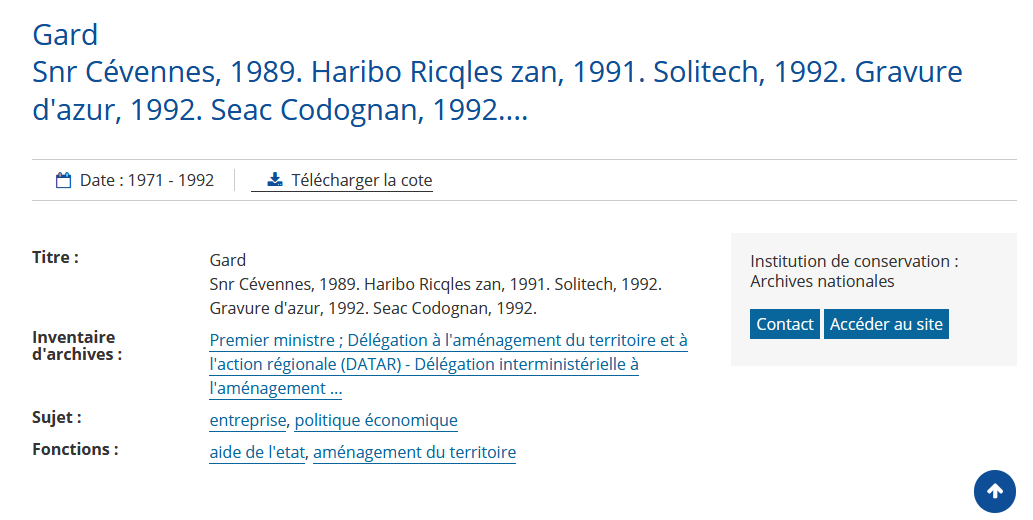
Voici ce que nous traitons :
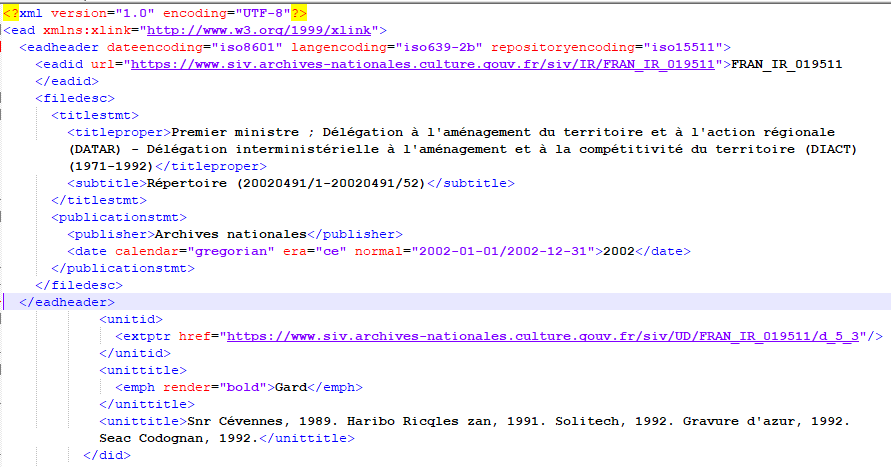
Les métadonnées sont bien là. Cet intermédiaire invisible pour
l'utilisateur permet de mettre en forme de façon lisible les
informations.
Mais alors comment êtes-vous parvenu jusqu'à ce résultat ? Comment,
parmi les milliers de résultats, les seuls qui vous ont été proposés
ont-ils été choisis ?
Vous avez vu les nombreux liens cliquables en bleu et soulignés que vous
trouvez un peu partout... Ce souvent des noms de lieux, de personnes ou
des thèmes, eh bien tous ces termes sont des autorités qui sont
extraites des instruments de recherche pour être groupées avec leurs
semblables et alignées sur de plus gros portails de données tels que
Data.BnF ou Wikidata.
Quelle en est l'utilité ?
L'identification de ces ressources permet de lever l'ambiguïté sur un
nom : être sûr qu'on parle bien de la même personne ; ou relier
plusieurs noms à une même ressource.
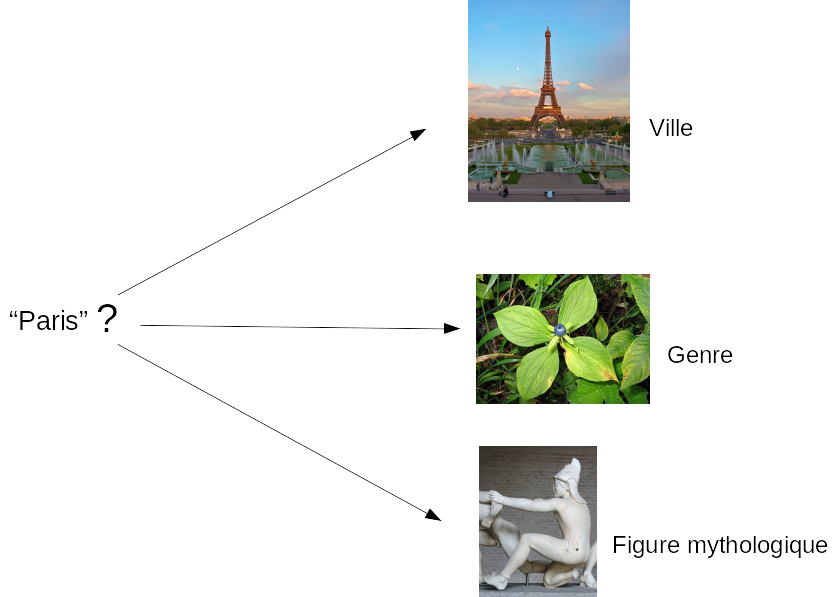
Prenons un exemple : "Paris" c'est à la fois le nom de la capitale
française, d'un genre de plante et d'une figure mythologique : 3
ressources différentes (donc 3 URI) portent le même nom. Paris a beau
être une ville fleurie et mythique, il est tout de même important de
pouvoir différencier tous ces éléments lors d'une requête.
Mais certains éléments peuvent présenter un cas inverse : l'autrice
Dominique Aury est également connue sous plusieurs pseudonymes très
différents les uns des autres : Anne Cécile Desclos et Pauline Réage.
Ici il y a donc une seule ressource (1 URI) qui porte ces 3 noms. Pour
que vous trouviez toujours le même résultat, ces 3 noms doivent être
tous rattachés à la même personne et ne pas figurer comme étant 3
éléments différents et distincts.
Cette différentiation ou ce regroupement est réalisé grace à l'URL (vous
savez les liens incompréhensibles écrits dans votre barre de
navigation...Eh bien en réalité ils ont un sens !)\
L'utilisation d'URL pour identifier les ressources est la base du Web
sémantique (ou Web de données).
--> https://www.wikidata.org/wiki/Q90 (Capitale de France)\
--> https://www.wikidata.org/wiki/Q162121 (Genre de Plante)\
--> https://www.wikidata.org/wiki/Q167646 (Figure mythologique)
3 "liens" différents, pour 3 thèmes complètement différents, mais qui
sont tous requêtables avec le même mot.
Le Web sémantique
Le Web sémantique a été inventé par Tim Berners-Lee, le fondateur du
Web.
Son idée est d'utiliser les technologies du Web pour y faire transiter
non seulement des documents (pages Web, comme c'est le cas aujourd'hui)
mais aussi des données.
Comme dans le Web que nous connaissons tous, le protocole HTTP visible
dans l'URL (on vous avait dit que ça avait un sens!) est utilisé pour
faire voyager les données. Les ressources quant à elles sont identifiées
par des URL (Uniform Resource Location) appelées aussi URI pour mettre
l'accent sur le côté identification (Uniform Resource Identifier).
Alors, cela étant dit, qu'est-ce que cela implique concrètement ? Nous y
venons.
Pourquoi "sémantique" ?
Le Web sémantique, aussi appelé Web de données, porte ce nom car il
permet aux machines de "comprendre" le contenu du Web (sémantique \<-->
sens).
Dans le Web de documents, nous (les humains) voyons et comprenons les
informations suivantes :
en HTML
<h1>Les berlingots Eysséric</h1>
<p>La fabrique Eysséric produit des berlingots dans le
<a href="https://www.vaucluse.fr/">Vaucluse</a>.
</p>
l'ordinateur, lui, comprend :
<h1>??? ??????????</h1>
<p>?? ???????? ???????? ??????? ??? ?????????? ???? ??
<a href="https://www.vaucluse.fr/">????????</a>.
</p>
Nous aimerions qu'il puisse comprendre:
Nom Produit Localisation
Fabrique Eysséric berlingots Vaucluse
Nous souhaiterions que l'ordinateur comprenne les relations entre les
éléments et la nature de ces éléments, comme nous en somme.
Pour cela, les données transmises doivent être structurées et
identifiées (nous l'avons vu plus haut, grâce aux URI).
Données structurées
 Le W3C (World Wide Web Consortium) définit des standards pour le Web
(encore un morceau de votre barre de navigation décrypté !).
Le W3C (World Wide Web Consortium) définit des standards pour le Web
(encore un morceau de votre barre de navigation décrypté !).
Pour représenter les données dans le Web sémantique, on utilise ces
standards et le Resource Description Format (RDF). Ce dernier consiste
à représenter les données sous forme de triplets utilisant des URI,
comme des phrases très simples : sujet - prédicat (verbe) - objet.
Les données structurées de notre exemple deviennent alors :
https://monUrl.fr/FabriqueEysseric https://monUrl.fr/produit https://monUrl.fr/Berlingot.
https://monUrl.fr/FabriqueEysseric https://monUrl.fr/localisation https://monUrl.fr/Vaucluse.
Et parce qu'on sait bien qu'un joli dessin vaut mille mots, on peut
aussi représenter les triplets bout à bout sous forme de graphe.

En récupérant les données relatives aux autres ressources du Web, on
peut étendre le graphe de données, tant qu'il y a des données.\
À l'instar du Web de documents où les documents sont interconnectés
grâce aux liens hypertexte, les ressources sont reliées les unes aux
autres dans le Web de données.
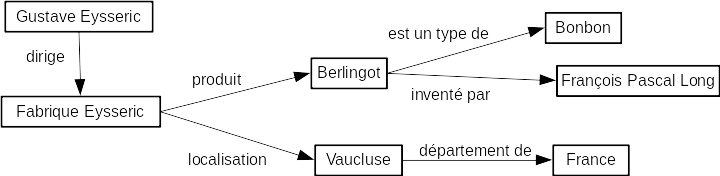
Pourquoi utiliser le Web sémantique dans FranceArchives ?
Besoin FranceArchives Réponse Web sémantique
Désambiguïser les autorités Utilisations d'URI comme identifiants
Données accessibles Protocole HTTP
Référencement par moteurs généralistes Contribution au google graph
Alignements référentiels nationaux Ontologies, alignements
Enrichissement des données propres à FA Geonames, data.bnf, wikidata
Limiter la responsabilité de maintenance des données Décentralisation
Parmi les besoins de FranceArchives, nous avons déjà vu que
l'utilisation d'URL comme identifiants (ce qui en fait des URI) répond
au problème de désambiguïsation des autorités.
De même, le protocole HTTP, base du Web, permet de rendre les données
disponibles sur le Web sans application tierce.
Maintenant que nous avons tous ces éléments, il ne reste plus qu'à
chercher !
Référencement par les moteurs de recherche généralistes
Certains moteurs de recherche (dont le plus connu de tous) se mettent au
RDF !
Ils utilisent des données en RDF insérées dans le code d'une page Web
pour mieux comprendre de quel sujet elle traite.
Grâce à cette compréhension, ils peuvent afficher certains résultats
sous des formes personnalisées... Exemple !
Le moteur de recherche utilise les triplets RDF pour afficher les
recettes de pâte à crêpes sous forme de petites cartes :\
Ainsi, vous n'avez même pas besoin de chercher LA meilleure recette de
pâte à crêpes, votre ami le moteur de recherche l'a fait pour vous. Et
comme il sait que vous n'aimez pas perdre votre temps et que vous aimez
quand même bien quand il y a de jolies images qui vous mettent l'eau à
la bouche, il vous propose de ne pas utiliser la molette de votre souris
et de cliquer directement sur la carte que vous préférez.
Alignement vers des référentiels
Il y a plusieurs avantages à lier les données que nous publions sur le
Web de données à des référentiels nationaux (ou internationaux).
Ontologie de référence
Une ontologie (ou un vocabulaire) est un ensemble d'URI que l'on va
utiliser pour représenter les prédicats (ou flèches en version graphe)
du RDF. L'ontologie définit les types de ressources présentes dans les
données et les relations qui peuvent exister entre elles.
C'est un peu le schéma d'une base de données relationnelle ou la liste
des noms de colonnes d'un tableur.
Si on compare les données au langage, l'ontologie serait la grammaire
ainsi qu'une partie du vocabulaire.
Le fait d'utiliser des ontologies standards dans ces données RDF permet
de se "brancher" plus facilement avec d'autres graphes de données.
Sources de données de référence
En liant ses données à d'autres bases de données sur le Web,
FranceArchives y trouve plusieurs avantages.
Tout d'abord, cela lui permet d'enrichir ses propres données.\
En effet, un document d'archives implique toujours des lieux et/ou des
personnes. On tente de normaliser les pratiques de nommage de ces
entités (dans quel sens on met quelle information) afin d'aider
davantage au liage des données : Charles, de Gaulle (1890-1970) ou
de Gaulle, Charles ou Général de Gaulle (Charles, 1890-1970). De
même pour les noms de lieux : Sumène, Sumène (Gard - 30),
Sumène (Gard), etc.
Dans les notices, seuls figurent généralement le nom du lieu (avec son
département) et le nom de la personne. En liant les données de
FranceArchives à d'autres bases, on peut ainsi étendre le graphe de
données et enrichir les informations que nous avions au départ. Comme
nous l'avons vu, plus il y a de mentions permettant de désambiguiser un
terme (à placer au Scrabble), meilleure sera la qualité de la donnée et
donc plus performant sera le schéma RDF et au final les résultats de
recherche.
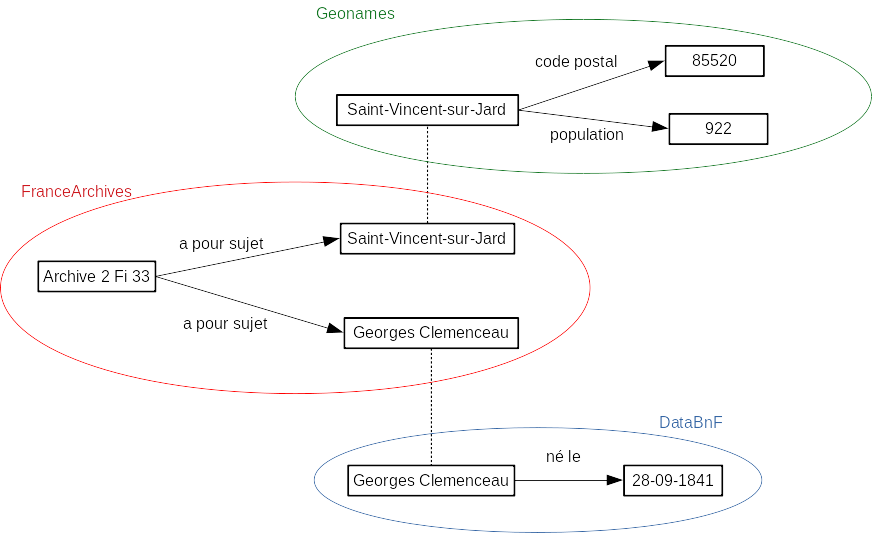
Ce schéma montre l'exemple de la notice Sur la plage de
Saint-Vincent-sur-Jard...
dont la description
RDF
peut être obtenue en ajoutant à l'url le suffixe /rdf.xml ou
/rdf.ttl.
Cette notice parle notamment de Georges Clemenceau et de la commune de
Saint-Vincent-Sur-Jard. Initialement, il y avait peu d'informations sur
ces deux ressources. En liant Saint-Vincent-sur-Jard à son pendant dans
Geonames,
une base de données regroupant des lieux, nous avons pu enrichir les
données en récupérant notamment le code postal et la population. De la
même manière, en liant Georges Clemenceau à son pendant dans
DataBnF, nous
avons pu enrichir les données en récupérant notamment sa date de
naissance et quelques éléments biographiques notables.
Le second avantage qu'apporte l'alignement (c'est-à-dire le fait de lier
sa base avec une autre) est de limiter la maintenance des données :
moins on les manipule, mieux elles se portent.
FranceArchives peut profiter d'informations libres et ouvertes sur les
personnes, les thèmes, les lieux pour valoriser ses données tout en se
concentrant sur la publication et la maintenance des données d'archives
uniquement.
data.bnf
Le projet data.bnf a pour but de rendre
les données de la BnF utiles et exploitables sur le web. Elles
permettent notamment de rassembler des informations sur les ressources
conservées au sein de la BnF : documents, ouvrages, auteurs, thèmes,
etc. Les pages sont indexées par les moteurs de recherche : les
données disponibles et requêtables sont souvent invisibles lors d'une
recherche classique car [enfouies dans les données et
métadonnées]{.underline} des ressources BnF.
Sur FranceArchives, ces liens permettent d'ajouter des informations sur
un sujet donné.
Wikidata
Wikidata est une base open source, gratuite,
collaborative et qui, de la même manière que DataBnF, met à
disposition des [données compréhensibles aussi bien par les humains
que par les machines]{.underline}. Cette base de données aide
Wikipédia en facilitant la maintenance des fameuses boites
d'informations que nous consultons tous dès que nous cherchons des
informations sur la célébre encyclopédie.
De la même manière que la précédente, les renvois vers Wikidata ajoutent
une plus-value aux données consultables sur FranceArchives.
 height="350"}
height="350"}
Geonames
Geonames est une base de données
libres et ouvertes sur les données géographiques.
DataCulture
DataCulture : le Ministère de la
Culture publie un référentiels de sujets classés hiérarchiquement (en
thésaurus). Les thèmes de FranceArchives sont alignés sur les ressources
de DataCulture.
Axes futurs d'amélioration
FranceArchives utilise déjà des technologies du Web sémantique. Pour
aller plus loin, les chantiers suivants sont envisagés.
Interrogation en SPARQL : SPARQL (oui il faut le lire comme un mot
prononcé SparKeul et ne pas le jouer au scrabble celui-là sauf si on
joue en anglais, car ça fait un jeu de mot pétillant avec to sparkle)
est le langage d'interrogation du RDF. Rendre possible l'interrogation
des données produites dans ce langage permet aux utilisateurs et
utilisatrices de rechercher très précisément les informations voulues.
Utilisation de l'ontologie
RiC-O : cette
ontologie (Records in Contexts - Ontology) est développée et maintenue
par le Conseil International des Archives. Elle est en passe de devenir
un standard pour le monde archivistique. L'utiliser pour décrire les
données de FranceArchives permettra de se brancher plus facilement aux
données d'autres services d'archives qui en font aussi usage.
I have a dream...
... that one day tout le monde pourra rechercher simplement et
trouvera du premier coup toutes les informations désirées !
Dans le monde numérique, ce qui est bien c'est qu'on peut rêver, et
rêver grand ! Alors que diriez-vous de pouvoir faire une requête telle
que : Je cherche les archives concernant le village de naissance du
général de Gaulle et la période 1945-1962 et que le moteur de recherche
vous remonte directement les documents qui traitent exactement de ce
dont vous, humain, vous parlez ? Imaginez un monde où l'on pourrait
interroger les bases de données en langage naturel.
Nous pouvons conclure cet article rédigé à l'occasion des Journées du
Logiciel Libre 2021, sur le thème des Utopies concrètes et accessibles
par cette proposition d'amélioration : un accès unique à toutes les
données du web, requêtables en langage naturel et sans bruit
documentaire... Un International Knowledge Portal ! | |
| *Elodie Thiéblin, développeuse chez Logilab et spécialiste du Web sémantique*
Du 3 au 6 novembre, j'ai participé à la conférence [ISWC (International Semantic
Web Conference)](https://iswc2020.semanticweb.org/), qui est une
des références internationales dans le domaine du Web Sémanti... | | 798 |
Elodie Thiéblin, développeuse chez Logilab et spécialiste du Web sémantique
Du 3 au 6 novembre, j'ai participé à la conférence ISWC (International Semantic
Web Conference), qui est une
des références internationales dans le domaine du Web Sémantique. On y parle
des problématiques du web de données liées et de réprésentation des
connaissances. Je partage ici mes notes sur les sujets qui m'ont le plus marquée.
Débriefing général de la conférence
Cette année, il y a eu de nombreux articles
consacrés à SHACL (Shape Constraint Language).
L'idée de remettre l'utilisateur des données et technologies du Web sémantique
au centre des innovations à venir a été répétée à plusieurs reprises.
L'intervention de Miriam Fernandez sur la diversité des données était
enrichissante. Elle invite les producteurs de données à se poser la question du
biais de leurs données et de la représentation du monde qu'elles renferment.
Des données biaisées peuvent provoquer de désastreux effets sociaux.
Elle cite notamment cet
article
qui présente les résultats d'une étude comparant les blessures des femmes et des
hommes avec une ceinture de sécurité lors d'accidents de la route entre 1998
et 2008. La différence de 47% entre les deux sexes serait imputable
aux mannequins de test de l'industrie automobile dimensionnés sur des hommes.
Résumé de présentations
Deux papiers ont retenu mon attention pour faciliter l'utilisation des
technologies du Web sémantique par les développeuses et les développeurs Web.
ON2TS: Typescript generation from OWL ontologies and SHACL
ON2TS est un prototype permettant de générer des classes et interfaces
TypeScript à partir d'ontologies OWL et de règles en SHACL. Les développeurs
peuvent donc utiliser directement les classes et interfaces générées pour
valider la structure et la forme de leurs données lors de l'exécution.
Ce prototype utilise la bibliothèque @ldflex/comunica, le moteur de requêtes
pour langage LDflex, qui est décrit ci-dessous.
Pour plus de détails, lisez l'article.
LDflex: a Read/Write Linked Data Abstraction for Front-End Web Developers
LDflex est un langage dédié qui fait
apparaîtr les données liées du Web comme des structures de données en
JavaScript. La vidéo de la présentation
est en ligne et il est possible d'expérimentation dans un
bac à sable.
Selon Ruben Verborgh, une des grandes différences entre les applications Web et
le Web sémantique est la "prédicabilité" : la structure et l'emplacement des données
sont prédéfinis dans une application Web (souvent choisie par les développeurs
de ladite application), tandis que dans le cas du Web sémantique, les ontologies
sont hétérogènes et les données sont distribuées.
Le but de LDflex est de simplifier la gestion des différents formats
et modes d'interrogation des serveurs de Web de données liées: des données
en RDF peuvent être récupérées depuis le Web puis interrogées localement en SPARQL.
Avec LDflex il est possible de manipuler une structure de données locale, qui
est mise en correspondance avec les données RDF d'origine au moyen d'un contexte.
Par exemple, le contexte suivant permet d'écrire user.friends pour
récupérer les individus ayant un lien foaf:knows vers user.
"@context": {
"@vocab": "http://xmlns.com/foaf/0.1/",
"friends": "knows",
"label": "http://www.w3.org/2000/01/rdf-schema#label",
}
Si le modèle évolue, il peut suffire de modifier le contexte pour adapter
l'application, ce qui en simplifie la maintenance.
LDflex semble donc à première vue une bonne alternative à rdflib.js. Comme
cette dernière, elle dépend toutefois des bibliothèques d'authentification Solid
qui prennent une taille non négligeable
(~500ko) dans le
bundle final.
La bibliothèque ldflex inclut le langage LDflex et doit être accompagnée de
@ldflex/comunica, son moteur de requêtes sur le Web.
Un rapide test sur logilab.fr (avec l'extension CORS Everywhere
activée) a suffit à montrer qu'on peut utiliser LDflex pour interroger les
instances de Cubicweb en version 3.28
Autres tests et remarques :
- Test sur http://dbpedia.org/resource/Paris
→ Mixed Blocked depuis le bac à sable en HTTPS
- Test sur https://aims.fao.org/aos/agrovoc/c_30969
→ 301 Moved Temporarily mais pas de requête sur l'URL cible (en HTTP)
- Test sur https://www.wikidata.org/entity/Q535
→ redirection à travers les différentes URL pour obtenir le RDF est gérée et fonctionne
→ requêtage en SPARQL ne fonctionne pas car l'entité est décrite en HTTP et non HTTPS dans le RDF
Il sera intéressant de suivre l'évolution de ce projet pour répondre aux
questions suivantes:
- Comment gérer plusieurs contextes simultanément (récupérer
foaf:name et
schema:name à la fois par exemple) ?
- Comment contourner le problème des requêtes Mixed Blocked en gardant les
données distribuées sur le Web ?
Conclusion
Cette expérience a été très enrichissante, comme chaque année. Je suis contente
qu'il y ait de plus en plus d'initiatives pour rendre le Web sémantique agréable
et accessible aux développeuses et aux développeurs Web. Cela va peut-être encourager
la valorisation des entrepôts de données liées dans des applications en production.
Un des sujets resté sans réponse est la gestion des configurations des serveurs
sur le Web de données liées pour notamment la gestion des erreurs
CORS, Mixed
Blocked,
etc.
Rendez-vous l'année prochaine pour vérifier ces hypothèses. | |
| A Logilab, dans un esprit d'amélioration continue, nous consacrons du temps à développer des projets qui facilitent notre travail au
quotidien. Dernièrement le projet AssignBot a été développé par Simon Chabot. | | 982 |
A Logilab, dans un esprit d\'amélioration continue, nous consacrons du
temps à développer des projets qui facilitent notre travail au
quotidien. Dernièrement le projet
AssignBot a
été développé par Simon Chabot. Afin d\'en savoir plus sur sa création
nous lui avons posé quelques questions :
- Bonjour Simon, peux-tu tout d\'abord te présenter en quelques mots ?
En quelques mots : j'ai étudié l'informatique à l'Université de
Technologie de Compiègne, puis je suis allé à Nice, entre autre, faire
une thèse sur la simulation numérique des séismes, avant de rejoindre
Logilab fin 2018.
- Peux-tu nous expliquer ce qu\'est AssignBot et à quel besoin il
répond ?
Lorsqu'on écrit du code, une des bonnes pratiques (peut être l'une des
plus importante ?), est la relecture par les pairs. L'objectif de la
relecture est d'améliorer la qualité du code produit, de favoriser la
collaboration et de faire en sorte que les connaissances soient
partagées.
À Logilab, nous avons plusieurs centaines de projets dans notre forge.
Certains sont des logiciels écrits spécifiquement pour nos clients,
généralement avec une équipe dédiée, et d'autres sont « communs ». Il
peut s\'agir de briques de base utiles à différents projets, d\'outils
internes (intranet, des tableaux de bords), ou de logiciels libres
développés avec des tiers (comme CubicWeb et ses nombreux cubes).
AssignBot est un petit robot dont la mission est d'organiser cette
relecture, notamment pour nos projets « communs ». Lorsqu'une personne
propose un changement elle envoie sur notre forge une merge request.
AssignBot va alors choisir une personne volontaire pour s'occuper de
cette merge request. Je dis "volontaire", parce qu\'un des objectifs
d'AssignBot est de laisser aux relecteurs la possibilité de régler le
nombre de relectures qu'ils veulent bien faire par jour / semaine, afin
de permettre aux personnes qui le souhaitent de participer, même si leur
emploi du temps est chargé.
- N\'existait-il pas des solutions équivalentes que tu aurais pu
utiliser ?
Pour être honnête, je n'ai pas vraiment cherché avant d\'écrire
AssignBot. Suite à diverses discussions avec des collègues, nous sommes
arrivés à la conclusion que ce petit outil pourrait nous aider, et... je
trouvais ça rigolo. Un soir, ça m'a démangé et AssignBot est né. Dans
l'histoire de Logilab, un tel logiciel a déjà existé, mais il a été
petit à petit abandonné car il était trop rigide je crois.
- Avec quelle(s) technologie(s) l\'as-tu fait et pourquoi celle(s)-ci
?
AssignBot est écrit en Python. C'est le langage qui accompagne Logilab
depuis ses débuts et qui est connu par toute l'équipe. Pour trouver les
nouvelles merge requests, AssignBot utilise la bibliothèque Python
gitlab, qui permet d'interagir avec notre forge, basée sur Heptapod (un
fork de Gitlab qui permet de gérer des entrepôts Mercurial). Le code
est en réalité très court grâce à cette bibliothèque. Il suffit
simplement de demander les merge requests non-assignées, et de choisir
une personne dans la liste en fonction des préférences qu'elle a
définies (en terme de nombre de relectures par jour/semaine).
AssignBot utilise également un petit fichier d'historique, pour pouvoir
respecter ces préférences. Ce fichier est quand à lui placé sur notre
serveur de stockage S3.
- Est-il actuellement utilisé ? As-tu eu des retours des personnes
utilisatrices ?
AssignBot est utilisé aujourd'hui par une dizaine de personnes à Logilab
(j'espère d'ailleurs que cet article permettra d'augmenter ce nombre
:smile:)
Oui, j'ai eu quelques retours. Principalement positifs, les merge
requests restent moins longtemps en attente dans un coin sur la forge,
car il y a une personne qui est en charge de sa publication. AssignBot
ne connait pas les domaines avec lesquels les gens ont plus ou moins
d'affinité. Donc il arrive des fois que l'on se retrouve assigné une
merge request qui est assez loin de ce qu'on maîtrise. Ce qui a été un
peu déroutant au début. Mais je pense qu'il faut voir cela du bon côté,
ça permet de découvrir de nouvelles choses, d'être informé de ce qui est
fait par l'équipe. Et il faut voir la mission comme « je dois faire en
sorte que ce travail avance » et non pas comme « je dois relire et
trouver les erreurs potentielles de ce code », ça peut donc vouloir
dire, aller voir un·e collègue et poser des questions, ou demander si
quelqu'un veut bien jeter un œil en parallèle. Voilà... en fait
l'objectif d'AssignBot, pour revenir à la question du début, c'est ça :
« faire en sorte que les choses avancent ».
- AssignBot est-il publié sous licence libre ? Est-il utilisable dans
un autre contexte que Logilab ?
Oui, tout à fait, AssignBot est libre, publié sous licence LGPL. Le
code-source est disponible sur notre forge:
https://forge.extranet.logilab.fr/open-source/assignbot et un paquet
python est disponible sur pipy: https://pypi.org/project/assignbot/.
AssignBot est utilisable − normalement :) − sur toutes les forges
Heptapod ou Gitlab, à partir du moment où un service d'intégration
continue est disponible et qu'un compte applicatif pour AssignBot a été
crée.
- Quelles sont les perspectives d\'évolution de cet outil (s\'il y
en a) ?
Il y a deux évolutions possibles qui me viennent en tête.
La première serait d'avoir une fonctionnalité pour publier
automatiquement les merge requests qui ont été validées depuis un
certain temps. Il est courant dans nos pratiques à Logilab, de mettre un
tag « To Publish » ou simplement d'approuver une merge request pour
que l'auteur publie ensuite. Dès fois, ça nous sort de la tête, on a
oublié qu'il y avait du code à publier. AssignBot pourrait peut être
s'en charger, en disant « si les tests passent et que quelqu'un a
approuvé il y a plus de XXX jours alors je publie », ce qui est aligné
avec l'objectif « faire en sorte que les choses avancent ».
L'autre idée est qu'actuellement AssignBot sauvegarde un historique sur
un serveur S3. Donc il est nécessaire d'avoir un tel serveur pour
utiliser AssignBot. Une évolution sans doute intéressante serait
d'utiliser tout simplement un artifact Gitlab. Ça permettrait de
supprimer cette dépendance et d'avoir un robot "tout en un". | [CubicWeb](https://cubicweb.readthedocs.io) est un cadriciel libre de gestion de
données sur le Web développé et maintenu par [Logilab](https://logilab.fr)
depuis 15 ans. Il est utilisé depuis 2010 dans des applications d'envergure
telles que [DataBnF](https://data.bnf.fr) ou
[FranceAr... | | 1170 |
CubicWeb est un cadriciel libre de gestion de
données sur le Web développé et maintenu par Logilab
depuis 15 ans. Il est utilisé depuis 2010 dans des applications d'envergure
telles que DataBnF ou
FranceArchives. Basé sur les principes du web
sémantique depuis sa création, il adopte à son rythme les standards du W3C pour
faciliter la publication de données sur le Web de données liées
(LOD).
CubicWeb vient de franchir une nouvelle étape avec la version 3.28 sortie le 24
juin 2020, qui met à disposition la négociation de contenu HTML / RDF.
Cette fonctionnalité a fait l'objet d'un article
scientifique
et d'une démonstration lors de la conférence d'Ingénierie de Connaissance de la Plateforme Française d'Intelligence Artificielle.
Nous allons maintenant présenter CubicWeb, les principes de la négociation de
contenu en général, les choix faits pour la mettre en oeuvre dans CubicWeb et
comment personnaliser le RDF généré.
Présentation de CubicWeb
CubicWeb fonctionne par composants, appelés
cubes, qui peuvent être combinés pour créer
une application (qui est elle-même un cube réutilisable).
Un cube est composé:
-
1- d'un schéma (ou modèle données) exprimé en
YAMS,
un langage qui permet d'exprimer un modèle entité-association et les
permissions associées en python ;
-
2- d'une logique applicative ;
-
3- de vues (interfaces graphiques ou fonctions d'export de données).
Lorsqu'une application est "instanciée", le schéma YAMS est compilé en un schéma
SQL et une base de données Postgresql est initialisée pour stocker le modèle et
les données de l'application.
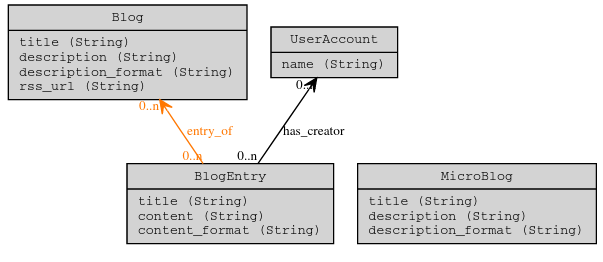
La logique de l'application, écrite en Python, interagit
avec la base de données par le biais du schéma YAMS et du langage de requête
RQL. Il
n'y a donc pas besoin d'écrire des requêtes SQL et de se préoccuper du schéma
physique de la base relationnelle sous-jacente.
L'introduction d'une séparation nette entre l'obtention des données via une
requête RQL et leur mise en forme par une vue permet d'offrir à l'utilisateur
une grande liberté dans son exploration de la base.
S'il n'y a pas de vue personnalisée prévue pour une entité du modèle YAMS, une
vue est générée automatiquement, ce qui assure que toutes les données sont
visibles et manipulables, ne serait-ce qu'au travers d'une interface minimale
qui permet aux utilisateurs autorisés d'ajouter, éditer et supprimer les entités
de l'application.
Dans cette architecture, offrir une représentation RDF d'une ressource/entité
consiste à définir une vue spécifique, qui traduira dans le vocabulaire RDF
choisi les entités définies par le modèle YAMS.
Présentation de la négociation de contenu
La négociation de contenu permet d'obtenir plusieurs représentations d'une même ressource à partir d'une même URL.
Une personne visitant la ressource http://cubicweb.example.com/person/123 avec
son navigateur souhaite généralement obtenir la version HTML pour la lire.
Dans le Web de données, un robot ou un programme sera plus intéressé par la
représentation RDF de cette ressource pour en traiter les données.
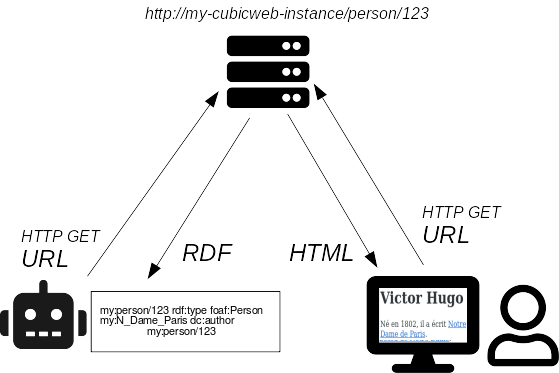
La même ressource abstraite est donc mise à disposition par le serveur sous deux représentations distinctes : le RDF et le HTML.
Le mécanisme de négociation de contenu permet de servir ces représentations
depuis la même URL, qui pourra ainsi être partagée entre ces deux mondes : humain
et robot.
Implémentation de la négociation de contenu
La négociation de contenu passe par les différents en-têtes Accept* d'une
requête HTTP. Elle peut concerner la langue avec Accept-Language, le jeu de
caractères avec Accept-Charset, l'encodage avec Accept-Encoding ou encore le
format avec Accept.
C'est l'en-tête Accept qui est utilisée par le client pour spécifier qu'il
souhaite la représentation RDF d'une ressource dans un format donné, en
utilisant l'un des types
MIME
suivants :
-
· application/rdf+xml
-
· text/turtle
-
· text/n3
-
· application/n-quads
-
· application/n-triples
-
· application/trig
-
· application/ld+json
Lorsqu'une requête est envoyée au serveur avec l'en-tête Accept et un type MIME de la liste ci-dessus, le serveur peut répondre de plusieurs façons.
Il peut indiquer au client, via une redirection intermédiaire (303 See Other), l'URL où se trouve la ressource dans la bonne représentation. C'est le choix fait par Virtuoso.

Il peut également répondre en envoyant directement la description RDF dans le format correspondant au type MIME de la requête.

C'est le choix que nous avons fait dans CubicWeb, pour éviter une seconde
requête et gagner en efficacité.
Description RDF des entités CubicWeb
Dans la version 3.28, CubicWeb fournit une représentation en RDF par défaut de
ses entités, qui contient deux «types» de triplets :
-
· ceux qui décrivent les relations et attributs du schéma YAMS. Ils utilisent le préfixe http://ns.cubicweb.org/cubicweb/0.0/, abrégé en cubicweb.
-
· ceux qui décrivent des relations Dublin Core.
Par exemple, si vous avez une instance qui héberge des articles de blog
(CustomBlogEntry), vous pourrez exécuter :
curl -iH "Accept: text/turtle" http://cubicweb.example.com/customblogentry/2872
qui retournera :
@prefix cubicweb: <http://ns.cubicweb.org/cubicweb/0.0/> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
@prefix dc: <http://purl.org/dc/elements/1.1/> .
# triplets Cubicweb (générés par cw_triples())
<http://cubicweb.example.com/902> cubicweb:wf_info_for <http://cubicweb.example.com/901> .
<http://cubicweb.example.com/901> a cubicweb:CustomBlogEntry ;
cubicweb:content "Ceci est le contenu de mon billet de blog" ;
cubicweb:content_format "text/plain" ;
cubicweb:creation_date "2020-07-09T07:59:09.339052+00:00"^^xsd:dateTime ;
cubicweb:entry_of <http://cubicweb.example.com/900> ;
cubicweb:modification_date "2020-07-09T07:59:29.300045+00:00"^^xsd:dateTime ;
cubicweb:title "Mon billet de blog" .
# triplets Dublin Core (généré par dc_triples())
dc:language "en" ;
dc:title "Mon billet de blog" ;
dc:type "Blog entry" .
Personnaliser le RDF généré
Pour personnaliser la représentation RDF d'un type d'entité, il faut créer une
classe héritant de EntityRDFAdapter, puis redéfinir sa méthode triples qui
doit, comme son nom l'indique, renvoyer un ensemble de triplets. Les triplets
sont formés avec rdflib.
Par défaut, la méthode triples appelle les méthodes cw_triples et
dc_triples de EntityRDFAdapter pour récupérer respectivement les triplets
CubicWeb et les triplets Dublin Core. Ces méthodes peuvent être surchargées si
nécessaire.
Le code ci-dessous montre un exemple d'adaptateur RDF pour la classe BlogEntry.
La fonction _use_namespace permet de relier un préfixe à son namespace dans
le graphe RDF généré, en l'ajoutant au dictionnaire NAMESPACES du module cubicweb.rdf.
from rdflib import URIRef, Namespace
from cubicweb.entities.adapters import EntityRDFAdapter
from cubicweb.rdf import NAMESPACES
NAMESPACES["sioct"] = Namespace("http://rdfs.org/sioc/types#")
class BlogEntryRDFAdapter(EntityRDFAdapter):
__select__ = is_instance("BlogEntry")
def triples(self):
SIOCT = self._use_namespace("sioct")
RDF = self._use_namespace("rdf")
yield (URIRef(self.uri), RDF.type, SIOCT.BlogPost)
Exemple de triplets personnalisés
Dans la version 1.14.0 du cube blog sortie le 24 juin 2020, l'ontologie SIOC (Semantically-Interlinked Online Communities) a été utilisée pour décrire les entités relatives aux blogs.
Voici le résultat obtenu pour un billet de blog :
curl -iH "Accept: text/turtle" https://www.logilab.fr/blogentry/2872
qui renverra:
@prefix dcterms: <http://purl.org/dc/terms/> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix sioc: <http://rdfs.org/sioc/ns#> .
@prefix sioct: <http://rdfs.org/sioc/types#> .
@prefix xml: <http://www.w3.org/XML/1998/namespace> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
<http://www.logilab.fr/2872> a sioct:BlogPost ;
dcterms:date "2019-06-28T15:28:31.852530+00:00"^^xsd:dateTime ;
dcterms:format "text/markdown" ;
dcterms:modified "2020-06-19T13:26:20.750747+00:00"^^xsd:dateTime ;
dcterms:title "SemWeb.Pro 2019 : envoyez votre proposition avant samedi 31 août !" ;
sioc:container <http://beta.logilab.fr1377> ;
sioc:content """La prochaine édition de SemWeb.Pro aura lieu mardi 3 décembre à Paris.\r
\r
\r
\r
Nous vous invitons à soumettre vos propositions de présentation en [répondant à l'appel à communication](<http://www.semweb.pro/semwebpro-2019.html>) **avant le 31 août 2019**.\r
\r
Pour être tenu informé de l'ouverture de la billetterie, envoyez un courriel à contact at semweb.pro en demandant à être inscrit à la liste d'information.""" .
Les prochaines étapes pour CubicWeb
Permettre la négociation de contenu est une étape de nos travaux actuels pour faire de CubicWeb une brique à part entière du LOD.
Nous travaillons déjà à la génération d'archive RDF pour faciliter l'export, mais également à la possibilité d'interroger la base en SPARQL, en plus du RQL.
| |
| La prochaine édition de SemWeb.Pro aura lieu mardi 3 décembre au FIAP
Jean Monnet, à Paris.

Nous vous invitons à soumettre vos propositions de présentation en [répondant à l'appel à communication](<http://www.semweb.pro/semwebpro-2019... | | 59 |
La prochaine édition de SemWeb.Pro aura lieu mardi 3 décembre au FIAP
Jean Monnet, à Paris.
Nous vous invitons à soumettre vos propositions de présentation en répondant à l'appel à communication avant le 31 août 2019.
Pour être tenu informé de l'ouverture de la billetterie, envoyez un courriel à contact@semweb.pro en demandant à être inscrit à la liste d'information. | Nous avons eu le plaisir de soutenir l'organisation du [pgDay Lyon 2019](https://pgday.fr/) aux côté des spécialistes de Postgresql et d'autres sociétés qui en font un usage intensif.
Le programme montre que Postgresql est une base de données très flexible, qui allie performances et très ... | | 48 |
Nous avons eu le plaisir de soutenir l'organisation du pgDay Lyon 2019 aux côté des spécialistes de Postgresql et d'autres sociétés qui en font un usage intensif.
Le programme montre que Postgresql est une base de données très flexible, qui allie performances et très grandes quantités de données ! | Co-organisée par [Logilab](https://www.logilab.org/), [Octobus](https://octobus.net/) & [RhodeCode](https://rhodecode.com/) la conférence Mercurial aura lieu mardi 28 mai au siège de [Mozilla](https://en.wikipedia.org/wiki/Mozilla), à Paris.
[Mercurial](https://www.mercurial-scm.org/) est... | | 135 |
Co-organisée par Logilab, Octobus & RhodeCode la conférence Mercurial aura lieu mardi 28 mai au siège de Mozilla, à Paris.
Mercurial est un système de gestion de contrôle de code source distribué gratuitement qui offre une interface intuitive pour gérer efficacement des projets de toutes tailles. Avec son système d'extension puissant, Mercurial peut facilement s'adapter à n'importe quel environnement.

Cette première édition s'adresse aux entreprises qui utilisent déjà Mercurial ou qui envisagent de passer d'un autre système de contrôle de version, tel que Subversion.
Assister à la conférence Mercurial permettra aux utilisateurs de partager des idées et des expériences dans différents secteurs. C'est aussi l'occasion de communiquer avec les principaux développeurs de Mercurial et d'obtenir des mises à jour sur le flux de travail et ses fonctionnalités modernes.
Inscrivez-vous !
Mozilla : 16 bis boulevard Montmartre 75009 - Paris | Logilab co-organise avec la société Octobus, un mini-sprint Mercurial qui aura lieu du jeudi 4 au dimanche 7 avril à Paris.

Logilab accueillera le mini-sprint dans ses locaux parisiens les jeudi 4 et vendredi 5 avril. Octobus s'occupe des sa... | | 94 |
Logilab co-organise avec la société Octobus, un mini-sprint Mercurial qui aura lieu du jeudi 4 au dimanche 7 avril à Paris.
Logilab accueillera le mini-sprint dans ses locaux parisiens les jeudi 4 et vendredi 5 avril. Octobus s'occupe des samedi et dimanche et communiquera très prochainement le lieu retenu pour ces jours-là.
Afin de participer au sprint, remplissez le sondage et indiquez votre nom et les dates auxquelles vous souhaitez participer.
Vous pouvez aussi remplir le pad pour indiquer les thématiques que vous souhaitez aborder au cours de ce sprint : https://mensuel.framapad.org/p/mini-sprint-hg
Let's code together! | Nous avons le plaisir de soutenir l'organisation du [pgDay Paris 2019](https://2019.pgday.paris/) aux côté des spécialistes de Postgresql et d'autres sociétés qui en font un usage intensif.
Consulter le programme, il est montre que Postgresql est une base de données très flexible, qui all... | | 50 |
Nous avons le plaisir de soutenir l'organisation du pgDay Paris 2019 aux côté des spécialistes de Postgresql et d'autres sociétés qui en font un usage intensif.
Consulter le programme, il est montre que Postgresql est une base de données très flexible, qui allie performances et très grandes quantités de données ! | Découvrez [le retour de Nicolas Chauvat](https://www.logilab.org/blogentry/10131142) sur l'édition 2019 du FOSDEM qui a lieu les 2 et 3 février à Bruxelles, en Belgique.

À cette occasion, Nicolas a présenté le dernier projet ... | | 67 |
Découvrez le retour de Nicolas Chauvat sur l'édition 2019 du FOSDEM qui a lieu les 2 et 3 février à Bruxelles, en Belgique.

À cette occasion, Nicolas a présenté le dernier projet de Logilab, un redémarrage de CubicWeb pour le transformer en une extension Web permettant de parcourir le Web des données. L'enregistrement de la conférence, les diapositives et la vidéo de la démo sont en ligne. | 
**Retrouvez-nous au stand C6-D5 du salon**
5 & 6 décembre au Dock Pullman, plaine Saint-Denis
Nous vous accueillerons avec plaisir au salon Paris Open Source Summit pour parler logiciel libre, données ouvertes et Web sémantique.
Et ne rate... | | 70 |

Retrouvez-nous au stand C6-D5 du salon
5 & 6 décembre au Dock Pullman, plaine Saint-Denis
Nous vous accueillerons avec plaisir au salon Paris Open Source Summit pour parler logiciel libre, données ouvertes et Web sémantique.
Et ne ratez pas la présentation de Arthur Lutz : Retour d'expérience sur la mise en place de déploiement continu qui aura lieu dans la matinée du mercredi 5 décembre, track Devops.
Demandez votre badge d'accès gratuit ! | Depuis son lancement, Logilab soutien PyParis : deux jours de conférence qui réuni des utilisateurs et des développeurs du langage de programmation Python.

**À cette occasion,** [Arthur Lutz](https://twitter.com/arthurlutz) *... | | 105 |
Depuis son lancement, Logilab soutien PyParis : deux jours de conférence qui réuni des utilisateurs et des développeurs du langage de programmation Python.

À cette occasion, Arthur Lutz présentera "Python tooling for continuous deployment". Il expliquera comment au sein de Logilab nous avons migré les processus de génération et de déploiement vers un modèle de distribution continue, les conséquences d'un tel changement en termes de technologie, au sein des équipes et de gestion de projet avec les clients. Cette présentation portera sur les outils Python qui ont permis de réaliser un tel changement, mais également sur les changements humains qu’il nécessite.
Consultez le programme et inscrivez-vous ! | 
<http://semweb.pro/semwebpro-2018.html>
Suivez nos actualités sur Twitter [@semwebpro](https://twitter.com/semwebpro) mais aussi avec le hashtag [\#semwebpro](https://twitter.com/hashtag/Semwebpro)
Pour plus d'informations, contactez-nous :... | | 18 |

http://semweb.pro/semwebpro-2018.html
Suivez nos actualités sur Twitter @semwebpro mais aussi avec le hashtag #semwebpro
Pour plus d'informations, contactez-nous : contact@semweb.pro | 
Rendez-nous visite et rencontrez notre équipe !
<contact@logilab.fr>
Suivez nos actus : [@logilab](https://twitter.com/logilab) | | 11 |

Rendez-nous visite et rencontrez notre équipe !
contact@logilab.fr
Suivez nos actus : @logilab | Pionnier du langage Python en France, **Logilab** est mécène de [PyConFr](https://www.pycon.fr/2018/), conférence annuelle des pythonistes francophones qui aura lieu du jeudi 4 au dimanche 7 octobre, à Lille.

Un codage participatif aura lieu... | | 146 |
Pionnier du langage Python en France, Logilab est mécène de PyConFr, conférence annuelle des pythonistes francophones qui aura lieu du jeudi 4 au dimanche 7 octobre, à Lille.

Un codage participatif aura lieu les jeudi 4 et vendredi 5 octobre. Des développeuses et des développeurs de différents projets open source se rassembleront pour coder ensemble. C'est l'occasion de participer au développement de son projet préféré !
Durant le week-end, auront lieu des présentations sur des sujets variés, autour du langage Python, de ses usages, des bonnes pratiques, des retours d'expériences, des partages d'idées.
Cette année, deux ingénieurs de notre équipe sont au programme :
- Arthur Lutz présentera Déployer des applications python dans un cluster openshift et aussi Faire de la domotique libriste avec Python
Et
- Julien Tayon présentera La cartographie c'est simple et "complexe"
La billetterie en ligne est fermée ! Pour plus d'informations, rapprochez-vous de l'association organisatrice. | 
**Mardi 6 novembre au FIAP Jean Monnet, à Paris**
Consultez le [programme et inscrivez-vous](http://semweb.pro/semwebpro-2018.html) dès à présent afin de bénéficier du tarif à 70€ (passage à 120€ après le 15 octobre).
*Vous pouvez assister ... | | 77 |

Mardi 6 novembre au FIAP Jean Monnet, à Paris
Consultez le programme et inscrivez-vous dès à présent afin de bénéficier du tarif à 70€ (passage à 120€ après le 15 octobre).
Vous pouvez assister à cette journée dans le cadre d'une formation professionnelle (donnant lieu à l'établissement d'une convention de formation). Dans ce cas, le tarif applicable est de 250€.
Suivez nos actualités sur Twitter @semwebpro mais aussi avec le hashtag #semwebpro
Pour plus d'informations, contactez-nous : contact@semweb.pro | Du 4 au 6 juin ont lieu les journées d'études **Documenter la production artistique : données, outils, usages** *autour des plateformes ReSource et Artefactory* qui se déroulent à la [Villa Arson](http://www.villa-arson.org), à Nice.
À cette occasion, [Adrien di Mascio](https://twitter.co... | | 115 |
Du 4 au 6 juin ont lieu les journées d'études Documenter la production artistique : données, outils, usages autour des plateformes ReSource et Artefactory qui se déroulent à la Villa Arson, à Nice.
À cette occasion, Adrien di Mascio présentera Désilotation et publication de données culturelles : un retour d’expérience.
Cette présentation expliquera de manière simple les notions d’échelle de qualité des données, d’ontologies, de référentiels, d’identifiants pérennes et d’alignements. Adrien montrera quelques retours d’expériences concrets de projets réalisés par Logilab comme data.bnf.fr, francearchives.fr ou Biblissima pour illustrer les différents concepts et processus mis en jeu pour publier des données patrimoniales.
Rendez-vous demain, mercredi 6 juin à partir de 10h45 à l'amphi 3 de la Villa Arson. | Organisée par [Logilab](https://www.logilab.fr/), avec le soutien de l'[INRIA](https://www.inria.fr/), [SemWeb.Pro](http://semweb.pro/semwebpro-2018.html) est une journée de conférences dédiée au Web Sémantique, qui réunit chaque année de 100 à 150 personnes depuis la première édition en 2... | | 374 |
Organisée par Logilab, avec le soutien de l'INRIA, SemWeb.Pro est une journée de conférences dédiée au Web Sémantique, qui réunit chaque année de 100 à 150 personnes depuis la première édition en 2011.
Participer à SemWeb.Pro c'est l'occasion d'échanger avec les membres de la communauté du Web Sémantique, ainsi qu'avec des sociétés innovantes et des industriels qui mettent en œuvre les nouvelles techniques du Web des données.
Nous vous invitons à soumettre dès à présent vos propositions de présentation afin de partager votre savoir-faire et votre expérience. Chaque présentation durera 20 minutes (hors Questions-réponses). La langue principale est le français, mais les présentations en anglais sont acceptées.
Procédure de soumission
Pour soumettre au comité de programme votre proposition de présentation, veuillez envoyer un courrier électronique à contact@semweb.pro avant le vendredi 15 juin 2018 en précisant les informations suivantes :
- titre,
- description en moins de 400 mots,
- auteur présenté en quelques phrases
- liens éventuels vers des démos, vidéos, applications, etc.
Critères de sélection
- l'utilisation effective des standards du Web Sémantique est indispensable,
- nous privilégierons les présentations de projets qui sont déjà en production ou qui concernent de nouveaux domaines d'application les démonstrations et vidéos seront appréciées.

Call for proposal
Organized by Logilab, with the support of INRIA, SemWeb.Pro is a one-day conference focused on the Semantic Web, which has been gathering between 100 to 150 persons each year since its first edition in 2011.
Attending SemWeb.Pro is a unique occasion to discuss with members of the Semantic Web community and with innovative companies and industrials implementors of the Web of Linked Data.
We invite you to send your proposal to share your experience and know-how. Each talk will last 20 minutes (excluding questions). The main language is French, but English talks are welcome.
Submission procedure
To submit your talk proposal to the program committee, please send an email to contact@semweb.pro before Friday June 15th, 2018 including the following information :
- title,
- description in less than 400 words,
- bio of the author in a few sentences,
- links to demos, videos, web applications, etc.
Selection criteria
- actual use of some of the Semantic Web standards is mandatory, we favor projects that are already at the production stage or that open new application domains
- demonstrations and videos are valued.
| Logilab co-organise avec la société [Octobus](https://octobus.net/), un mini-sprint Mercurial qui aura lieu du 21 au 25 mai au sein des [locaux logilabiens](https://www.logilab.fr/contact), à Paris.

Afin d'y participer, remplissez le sondage... | | 69 |
Logilab co-organise avec la société Octobus, un mini-sprint Mercurial qui aura lieu du 21 au 25 mai au sein des locaux logilabiens, à Paris.
Afin d'y participer, remplissez le sondage ci-dessous en nous indiquant votre nom et les dates de votre choix.
https://framadate.org/sprint-hg
Nous vous invitons également à remplir le pad et nous indiquer les thématiques que vous souhaitez aborder au cours de ce sprint : https://mensuel.framapad.org/p/mini-sprint-hg
Let's code together! | FOSDEM est une conférence qui réunit chaque année des milliers de développeurs de logiciels libres et open source du monde entier à Bruxelles.
Cette année ce rendez-vous incontournable aura lieu samedi 3 et dimanche 4 février à l'Université Libre de Bruxelles (ULB Solbosch Campus).

Logilab participera ensuite au Config Management Camp qui aura lieu du lundi 5 au mercredi 7 février à Gent.

Nous vous donnons rendez-vous mardi 6 février dans la Community Room Salt B.3.036.
Consultez le programme et rencontrons-nous sur place !
Suivez nos actualités sur ce blog ou sur Twitter :
| Demain, mardi 16 janvier, [Arthur Lutz](https://twitter.com/arthurlutz) vous invite au meetup Nantes monitoring où netdata et sensu sont à l'ordre du jour :
• [netdata](https://my-netdata.io/) pour la collecte et la visualisation de la métrologie

• sensu pour la supervision

Ce meet-up aura lieu de 19:00 à 22:00 au VA Solutions situé au 3 rue du Tisserand · Saint-Herblain (5 minutes à pied de l'arrêt de tram François Mitterrand sur la ligne 1).
INSCRIVEZ-VOUS ! | 
Pour la 5ème édition de ce rendez-vous, les Rencontres Régionales du Logiciel Libre s'installent cette année à l'Hippodrome de Toulouse, et pour la toute première fois à Montpellier.
Ces rencontres s'adressent aussi bien aux services informa... | | 155 |

Pour la 5ème édition de ce rendez-vous, les Rencontres Régionales du Logiciel Libre s'installent cette année à l'Hippodrome de Toulouse, et pour la toute première fois à Montpellier.
Ces rencontres s'adressent aussi bien aux services informatiques qu'aux directions métiers qui trouveront des réponses à leurs problématiques techniques et besoins fonctionnels.
Les RRLL sont ainsi l'occasion de diverses rencontres telles que des administrations, collectivités, industries et entreprises ayant déployé des solutions libres, ainsi que les prestataires locaux. Les Rencontres Régionales du Logiciel Libre sont une série d'évènements dans toute la France organisés sous l'égide du Conseil National du Logiciel Libre (CNLL).
Les RRLL de Toulouse sont inscrites dans le cadre de la manifestation Capitole du Libre organisée tous les ans par l' Association Toulibre.
À cette occasion, Logilab présentera "Tirer parti du Web des données pour améliorer l'efficacité des administrations et des entreprises".
Consultez les programmes :
| 
Pour cette sixième édition de SemWeb.Pro, des posters seront exposés dans le hall de la conférence. Rendez-vous mercredi 22 novembre au FIAP Jean Monnet, à Paris.
Participer à SemWeb.Pro c'est l'occasion d'échanger avec les membres de la com... | | 76 |

Pour cette sixième édition de SemWeb.Pro, des posters seront exposés dans le hall de la conférence. Rendez-vous mercredi 22 novembre au FIAP Jean Monnet, à Paris.
Participer à SemWeb.Pro c'est l'occasion d'échanger avec les membres de la communauté du Web Sémantique ainsi qu'avec des utilisateurs, issus de l'industrie ou de la culture, qui mettent en œuvre les nouvelles techniques du Web des données.
Consultez le programme et inscrivez-vous
Twitter @semwebpro #semwebpro
Pour plus d'informations, contactez-nous : contact@semweb.pro |  | | 0 |
| Membre toujours actif de la communauté Python, Logilab soutient le *meetup Python Nantes sur luigi et behave* qui aura lieu ce soir, à 19h au site de Voyages-Sncf.com situé au sud de la Gare SNCF, au 5ème étage du bâtiment Jalais dont l'entrée principale se trouve au 34 rue du Pré Gauchet.... | | 58 |
Membre toujours actif de la communauté Python, Logilab soutient le meetup Python Nantes sur luigi et behave qui aura lieu ce soir, à 19h au site de Voyages-Sncf.com situé au sud de la Gare SNCF, au 5ème étage du bâtiment Jalais dont l'entrée principale se trouve au 34 rue du Pré Gauchet.

Entrée gratuite, mais inscription obligatoire.
INSCRIVEZ-VOUS ! | Poursuivant notre développement en 2017, nous cherchons des ingénieurs afin de renforcer nos équipes de R&D :
> - [CDI - Directeur de projets agiles](/ddp1)
> - [CDI - Développement web (client / *Front-end*)](/inge3)
> - [CDI - Développement informatique et web sémantique](/inge2)
... | | 32 |
Poursuivant notre développement en 2017, nous cherchons des ingénieurs afin de renforcer nos équipes de R&D :

| 
Pour ce meetup de rentrée, trois présentations au programme :
• Introduction à SaltStack et son écosystème
• Quelles nouveautés dans la version 2017.7 de Salt Nitrogen ?
• Utiliser les formulas pour déployer des composants logiciels sur le... | | 49 |

Pour ce meetup de rentrée, trois présentations au programme :
• Introduction à SaltStack et son écosystème
• Quelles nouveautés dans la version 2017.7 de Salt Nitrogen ?
• Utiliser les formulas pour déployer des composants logiciels sur le cloud (avec salt-cloud)
INSCRIVEZ-VOUS
Heuritech : 248 rue du faubourg Saint Antoine, Paris. | 
Nous vous donnons rendez-vous pour la 6ème édition de SemWeb.Pro, journée de présentations et de rencontres dédiées au web sémantique dans le monde professionnel.
**Mercredi 22 novembre au FIAP Jean Monnet, à Paris**
Consultez le [programme... | | 101 |
Nous vous donnons rendez-vous pour la 6ème édition de SemWeb.Pro, journée de présentations et de rencontres dédiées au web sémantique dans le monde professionnel.
Mercredi 22 novembre au FIAP Jean Monnet, à Paris
Consultez le programme et inscrivez-vous dès à présent afin de bénéficier du tarif à 67€ (passage à 100€ après le 13 octobre).
Vous pouvez assister à cette journée dans le cadre d'une formation professionnelle (donnant lieu à l'établissement d'une convention de formation). Dans ce cas, le tarif applicable est de 200€.
Suivez nos actualités sur Twitter @semwebpro mais aussi avec le hashtag #semwebpro
Pour plus d'informations, contactez-nous : contact@semweb.pro | Logilab se réjouit de la mise en ligne de [FranceArchives.fr](http://francearchives.fr/) le mois dernier et félicite tous ceux qui ont participé à ce beau projet qui a reçu un accueil chaleureux dans la presse spécialisée et sur les réseaux sociaux ! | | 39 |
Logilab se réjouit de la mise en ligne de FranceArchives.fr le mois dernier et félicite tous ceux qui ont participé à ce beau projet qui a reçu un accueil chaleureux dans la presse spécialisée et sur les réseaux sociaux !
|
