
Hackathon "Des archives aux données" 2023
1500 mots: ~7min
Du 1er au 3 juin 2023 a eu lieu le colloque "Des archives aux données" au cours duquel deux jours de hackathon ont permis de s'interroger sur l'interopérabilité des données entre différentes institutions culturelles.
Les données présentées concernaient les représentations théâtrales de la Comédie Française (Base RCF), de la Comédie Italienne, du théâtre d'Amsterdam (Base On Stage) et du théâtre français des XVIIe et XVIIIe siècles (Base CESAR).
Ce fut l'occasion d'éprouver dans un contexte concret les avantages des technologies du Web Sémantique. Les requêtes fédérées ont en effet permis d'assembler et de manipuler des données publiées sans concertation préalable par les différents participants.
Tempête de cerveaux sur les besoins en interopérabilité
Lors de la première journée nous avons commencé par faire émerger des idées de traitements qui nécessitent une interopérabilité des données. Cette session a été très riche et il nous a fallu quelques efforts pour résumér les diverses idées et choisir vers quoi nous diriger.
Nos sources de données divergent principalement sur le périmètre étudié: les registres de la Comédie Française concernent une unique troupe, la base "ON_Stage" se focalise sur le théâtre d'Amsterdam et la base CESAR se limite à une période de temps.
La date des représentation théâtrales a été clairement identifiée comme centrale puisqu'elle permet de les aligner de manière non ambigüe. Chaque source de données décrit différemment les représentations, mais toutes ont renseigné la date.
Les lieux des représentations constituent un autre point de contact, pour autant que les périodes temporelles soient les mêmes.
Partant de ces deux constats, nous nous sommes demandé s'il serait possible d'afficher un graphique qui rendrait compte de l'évolution géographique d'une pièce dans une période de temps donnée.
Maquette d'une potentielle application
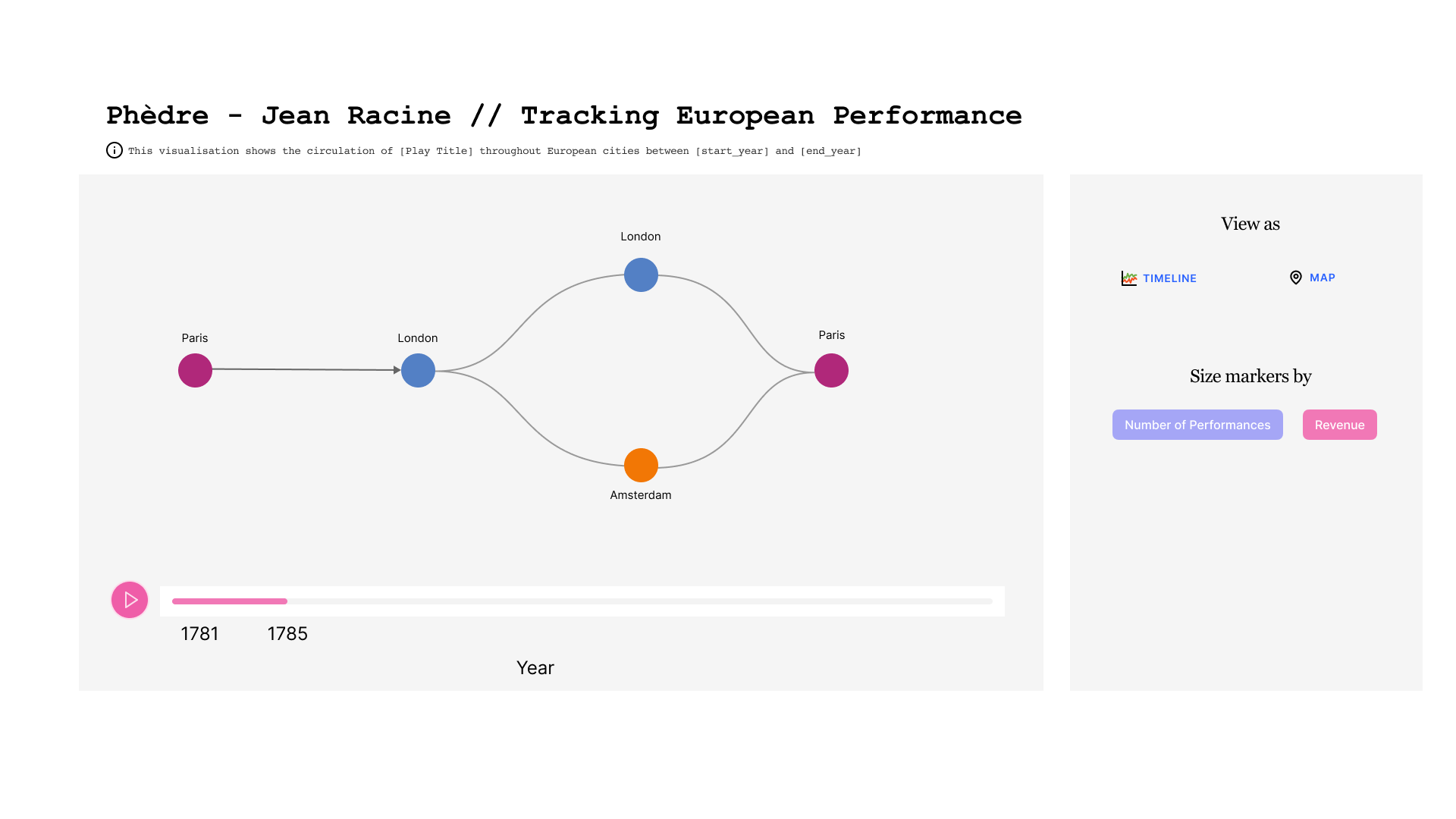
Dans la maquette ci-dessous, nous pouvons observer l'évolution dans le temps d'une pièce donnée. Au centre on voit l'enchaînement des villes où la pièce a été jouée. Une ville peut apparaître plusieurs fois si la pièce y a été rejouée après avoir tourné ailleurs. En bas figure la ligne de temps, qui est sous-divisée par année. A droite, on trouve un cadre avec des boutons qui permettent de choisir le mode de représentation.
Dans la première figure, la taille des cercles qui représentent les villes est liée au nombre de représentations.
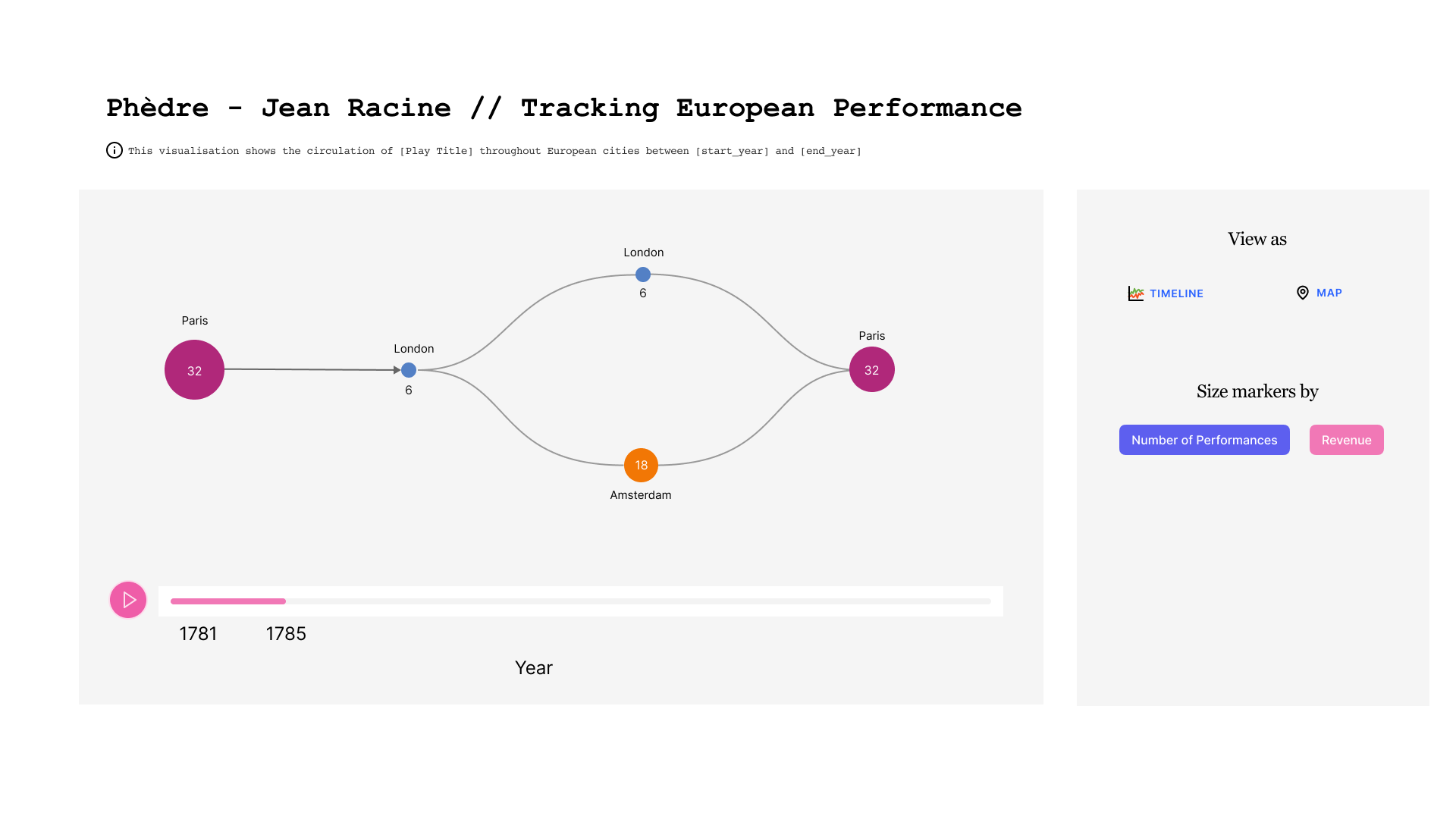
Dans la deuxième figure, la taille des cercles qui représentent les villes est liée au revenu généré.
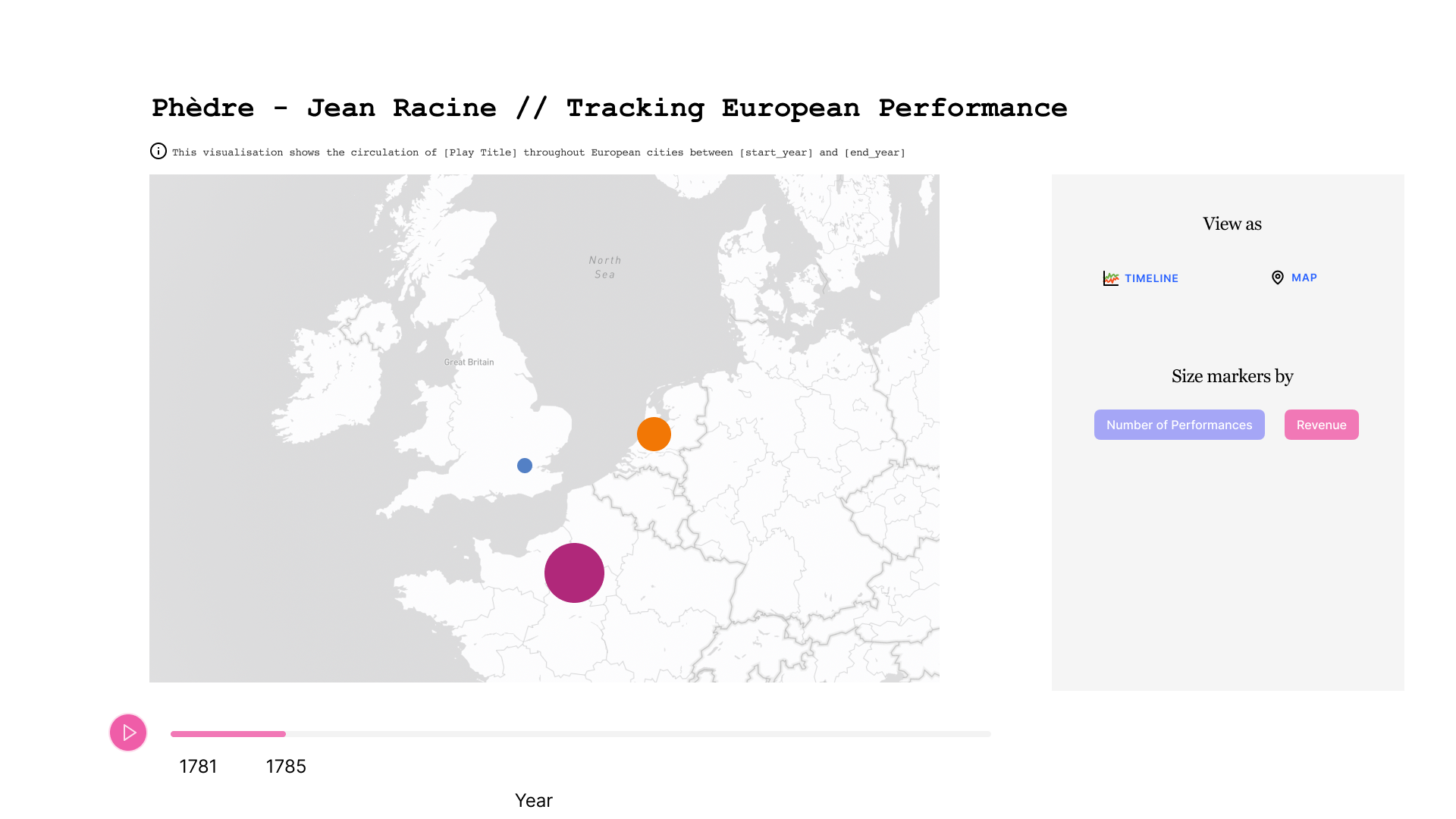
Dans la troisième figure, les données sont affichées sur une carte plutôt qu'avec un graphe.
Analyse des sources de données
Nous avons choisi de nous focaliser sur les sources déjà publiées dans des entrepôts SPARQL pour deux raisons. D'une part le hackathon était court, donc il fallait éviter de onsacrer du temps à des questions de lecture de formats de fichiers qui ne produiraient aucun résultat visible. D'autre part les gens autour de la table connaissaient déjà bien ces jeux de données.
Nous avons donc privilégié l'utilisation de ces trois sources de données: * Les registres de la Comédie Française / accès sparql * La base CESAR / accès sparql * La base ON-STAGE / accès sparql
Nous avons tout d'abord écrit des requêtes SPARQL fédérées afin de pouvoir joindre avec une seule requête des données de plusieurs bases.
Ce faisant, nous avons rencontré un premier problème technique, à savoir que l'entrepôt qui héberge les données de la Comédie Française n'était pas configuré pour accepter les requêtes fédérées. Nous avons donc essayé l'inverse, à savoir interroger l'entrepôt de la base CESAR, mais ce dernier repose sur Ontop, qui ne permet pas non plus les requêtes fédérées. Nous avons finalement utilisé l'entrepôt de la base ONSTAGE, déployé avec TriplyDB, pour exécuter une requête fédérée assemblant des données de RCF et CESAR... mais aucune de ONSTAGE. Ceci nous a rappelé que la fédération de requêtes, séduisante sur le papier, est parfois plus compliquée qu'il n'y paraît.
Alignement des modèles
Nous avons ensuite cherché quel modèle utiliser pour assembler les données obtenues avec ces requêtes.
La base CESAR décrit des "Séances", qui peuvent être définies comme des ensembles de représentations contigües. Cette notion peut être rapprochée de celle de "Journée" dans le modèle RCF, mais cet alignement n'est pas tout à fait exact puisqu'il est possible qu'il y ait plusieurs "Séances" à la même date, donc plusieurs "Séances" dans une "Journée". Les registres de la Comédie Française ne détiennent pas cette information de "Séance" spécifique et se contentent de considérer uniquement la "Journée".
Ces différences de modélisation sont monnaie courante et nous avons dû, sans surprise, définir un modèle intermédiaire adapté à notre objectif et des opérations de transformation des données pour les convertir de leur modèle d'origine vers ce modèle afin de les fusionner.
Nous avons retenu les notions de Pièce, de Représentation, de Séance et de Lieu.
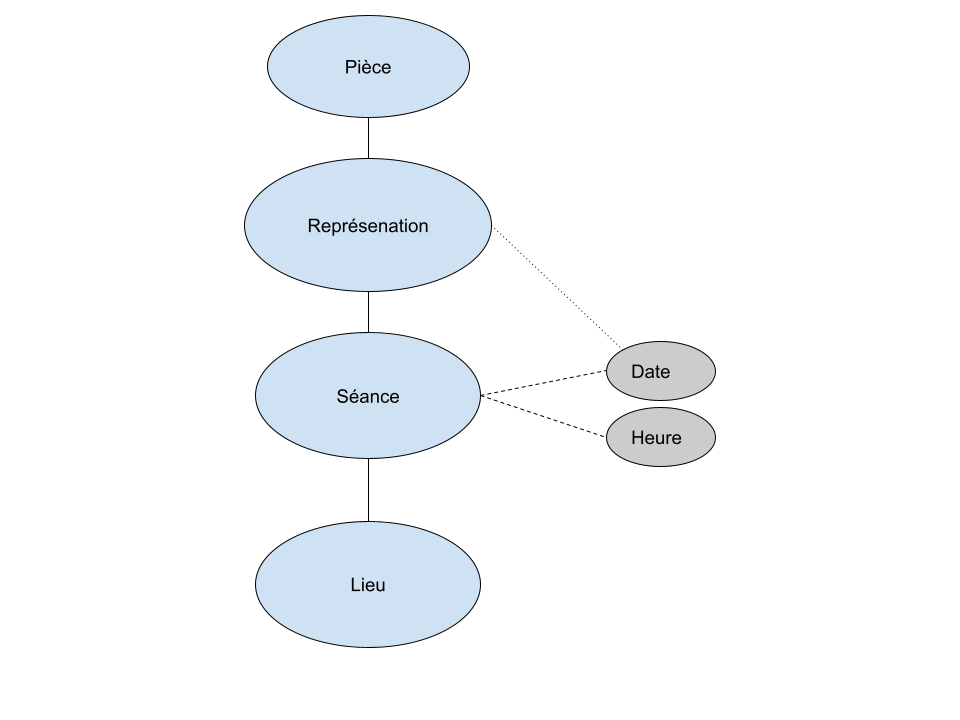
Alignement des données
L'objectif de notre maquette étant de rendre visible les évolutions des pièces qui apparaissent quand on fusionne les données complémentaires issues des différentes sources, nous avons ensuite aligné les pièces.
Pour cela, nous avons utilisé la date de représentation pour restreindre les candidats à l'alignement, puis le nom de la pièce. Par exemple, nous savons que le 30 septembre 1681 on a joué d'après la base CESAR une pièce 123303 intitulée "Phèdre et Hippolyte" et une pièce 23287 intitulée "Les Fragments de Molière". A la même date, d'après la base RCF, on a joué une pièce 5772 intitulée "Phèdre et Hippolyte ou Phèdre" et une pièce 5396 intitulée "Fragments de Molière (Les)". Avec une simple distance de Levenshtein entre chaînes de caractères, nous pouvons aligner les pièces et affimer que 123303 chez CESAR correspond à 5396 chez RCF.
En appliquant ce traitement sur l'ensemble des dates, nous avons obtenu un alignement entre les 49 pièces de CESAR et RCF.
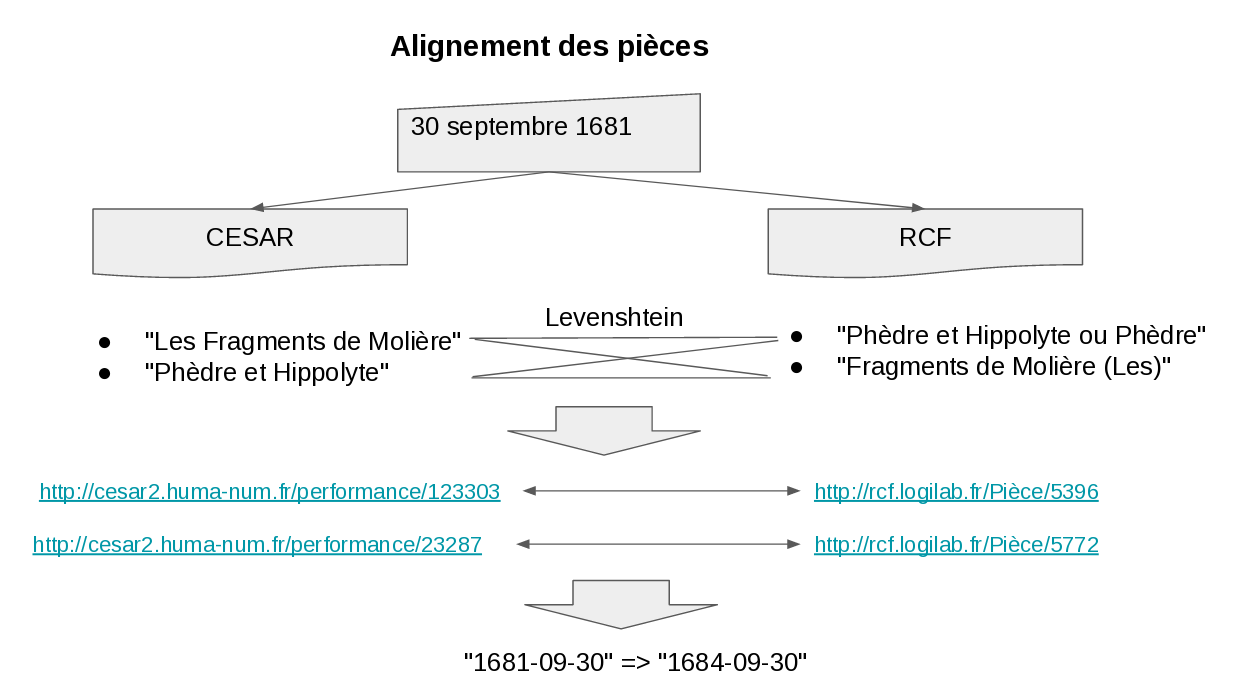
Vu le temps imparti, nous nous sommes limité aux pièces, mais on pourrait pousser plus loin et par exemple inclure dans le modèle les personnes, puis les aligner en utilisant des critères appropriés.
Exploitation des données
Une fois les données importées depuis les différentes sources, converties dans le même modèle et alignées automatiquement entre CESAR et RCR ou une par une pour quelques pièces de ONSTAGE, il devient possible de les exploiter.
Les bases RCF et ONSTAGE ne contenant pas de lieux, nous avons supposé que toutes les représentations RCF étaient à Paris et toutes celles d'ONSTAGE à Amsterdam. C'est probablement faux, donc pour améliorer la qualité du résultat il faudrait trouver des sources complémentaires à partir desquelles importer les lieux exacts des représentations.
Dans le calepin Jupyter qui nous a servi pour consigner nos expérimentations de manière reproductible, nous avons finalement produit le graphique ci-dessous:
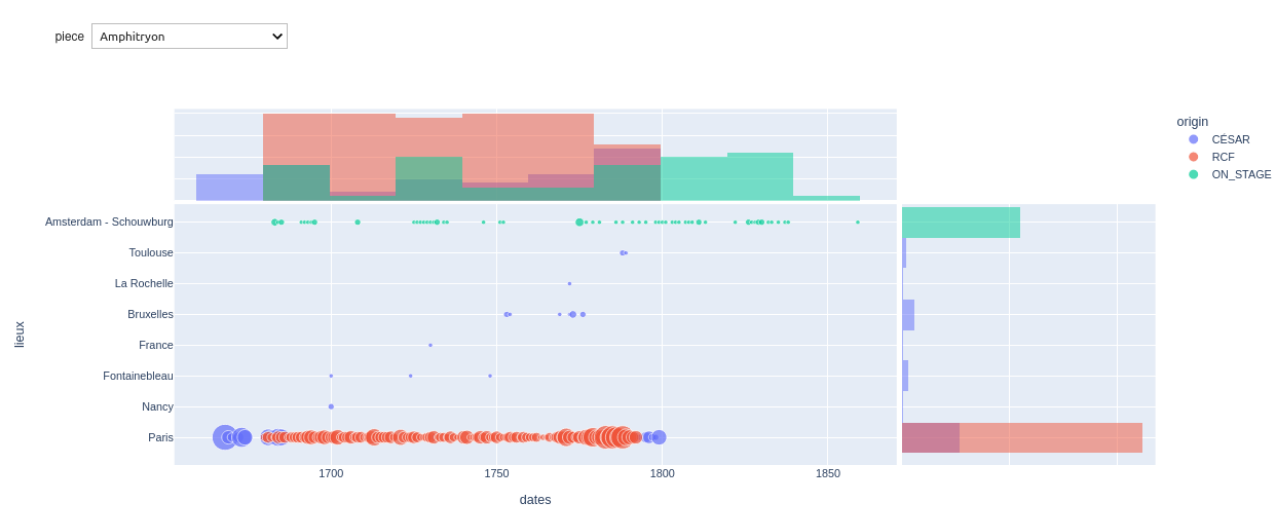
Le menu déroulant en haut à gauche permet de choisir une pièce.
Nous voyons au centre un nuage de points, avec l'année en abscisse et la ville en ordonnée. La couleur des points reflète la source de données et leur taille dépend du nombre de représentations.
L'histogramme au-dessus du graphique est l'aggrégation des données par an pour toutes les villes. L'histogramme de droite est l'agrégation par ville pour toutes les années.
Ce graphique démontre que nous avons produit les données souhaitées, mais il aurait fallu plus de temps pour les représenter comme imaginé en début de hackathon lorsque nous avons dessiné les maquettes graphiques.
Conditions de l'interopérabilité et gouvernance
Ce hackathon a mis en lumière pour tous les participants des questions bien connues de ceux qui ont l'habitude de ce genre d'exercice:
- un modèle commun est nécessaire pour communiquer entre les bases et celles et ceux qui administrent ces bases
- la qualité des données d'entrée détermine l'efficacité du traitement, c'est à dire le rapport entre la qualité du résultat et l'effort nécessaire pour le produire
- l'alignement est une étape cruciale de la fusion des données issues de plusieurs sources
- les standards du Web Sémantique, et particulièrement le RDF et le SPARQL sont des atouts indéniables pour faire interopérer plusieurs sources de données
Ces constats ont fait émerger, au sein de la communauté présente à ce colloque, la question du partage des bonnes pratiques de publication de données. Effectivement, maintenir un modèle commun d'échange, rédiger une guide de bonnes pratiques pour la publication, accompagner les institutions dans leur parcours d'apprentissage, tout cela est un travail long, mais primordial pour supprimer les obstacles à l'interopérabilité.
Il a été discuté de créer un consortium Huma-Num consacré à la gestion des données du spectacle vivant et à l'expression de ces bonnes pratiques, pour orienter la suite des travaux vers des solutions communes et faciliter les interactions entre les données de différentes institutions.
A Logilab, nous apprécions le travail que nous réalisons depuis plusieurs années pour le projet des Registres de la Comédie François et nous avons été honorés d'être invités à ce colloque. Ce hackathon nous a permis de relier les données de RCF, que nous connaissons bien, à d'autres jeux de données, que nous avons découverts, mais aussi de prendre part aux débats sur leur gouvernance future. Nous espérons pouvoir continuer à apporter nos compétences techniques à ces projets, pour faciliter le travail de recherche sur le théâtre et son histoire.